Clear Sky Science · es
Máquina de percepción-decisión inspirada en el cerebro para la detección de voz falsa
Por qué las voces falsas son un problema para todos
Cada vez resulta alarmantemente más fácil generar voces que suenan exactamente como una persona real, gracias a las herramientas modernas de inteligencia artificial. Estas voces convincentes amenazan desde la banca telefónica y los altavoces inteligentes hasta las reuniones en línea y los informes de noticias. El estudio descrito aquí aborda una pregunta clave: ¿cómo podemos distinguir de forma fiable el habla humana del habla sintética, incluso cuando las herramientas de falsificación subyacentes siguen cambiando y mejorando?
Una nueva forma de escuchar el problema
La mayoría de los sistemas existentes tratan la detección de voces falsas como una tarea simple de clasificación sí/no. Aprenden a partir de enormes colecciones de ejemplos e intentan trazar una frontera entre audio real y falso. Esto funciona bien con los tipos de voces falsas vistos durante el entrenamiento, pero el rendimiento cae cuando aparecen nuevos métodos de ataque. Los autores sostienen que esta es la mentalidad equivocada. En lugar de forzar a un único modelo a tomar una decisión de todo o nada, proponen imitar cómo los expertos humanos e incluso el propio cerebro manejan la información sensorial compleja: buscando muchas pequeñas pistas reveladoras y luego razonando sobre ellas.
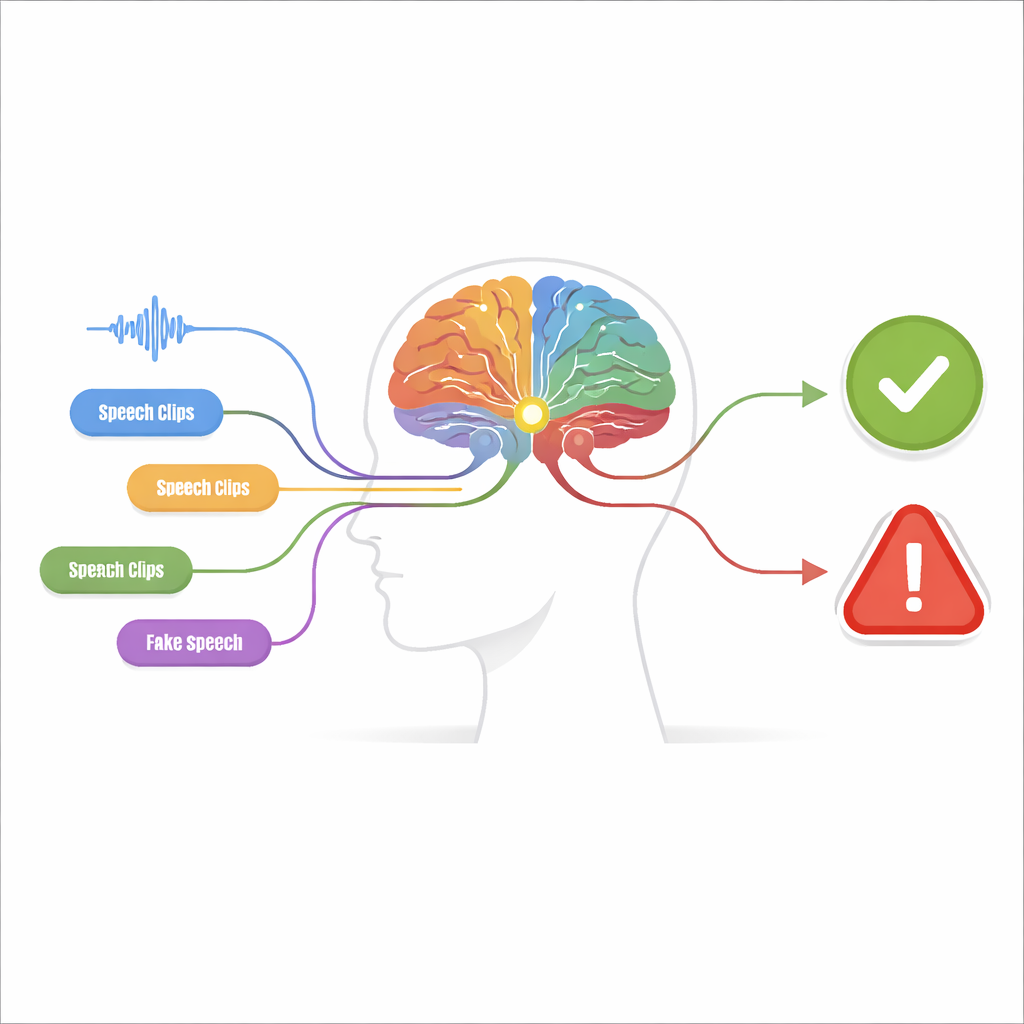
Muchas pistas pequeñas en lugar de una gran suposición
El sistema propuesto, llamado máquina de percepción-decisión, se construye en dos etapas. En la etapa de percepción, el audio es examinado por múltiples detectores independientes, cada uno afinado a una "pista de falsificación" específica. Algunos detectores se centran en la forma de onda cruda, buscando saltos bruscos y patrones artificialmente suaves. Otros examinan el contenido en frecuencia, donde las voces falsas pueden mostrar armónicos difuminados o resonancias de forma extraña. Detectores adicionales analizan cómo evolucionan conjuntamente el tiempo y la frecuencia, captando desajustes entre cuándo se producen ciertos sonidos y qué tonos están presentes. Un último grupo analiza detalles a nivel de fonemas—las pequeñas unidades sonoras que forman las palabras—donde el habla falsa a menudo carece de la articulación sutil y fluida de un hablante real.
De los patrones de pistas a una decisión clara
Cada detector está diseñado para ser extremadamente cauteloso: sólo señala "pista presente" cuando está casi seguro, priorizando la precisión sobre la detección de todo posible fake. Su salida se simplifica a un valor binario, como una luz que está encendida o apagada. Estas señales de encendido/apagado se alimentan luego al módulo de toma de decisiones. Aquí, grupos de pistas se combinan mediante árboles de decisión—cadenas estructuradas de reglas if–then que se parecen a la forma en que una persona podría razonar sobre la evidencia. Un paso lógico especial, aproximadamente similar a una regla de "cualquiera de estas es suficiente", enlaza múltiples árboles. Este razonamiento en capas no solo aumenta la precisión sino que también hace el sistema más transparente: se puede rastrear exactamente qué pistas condujeron a un veredicto de "falso".
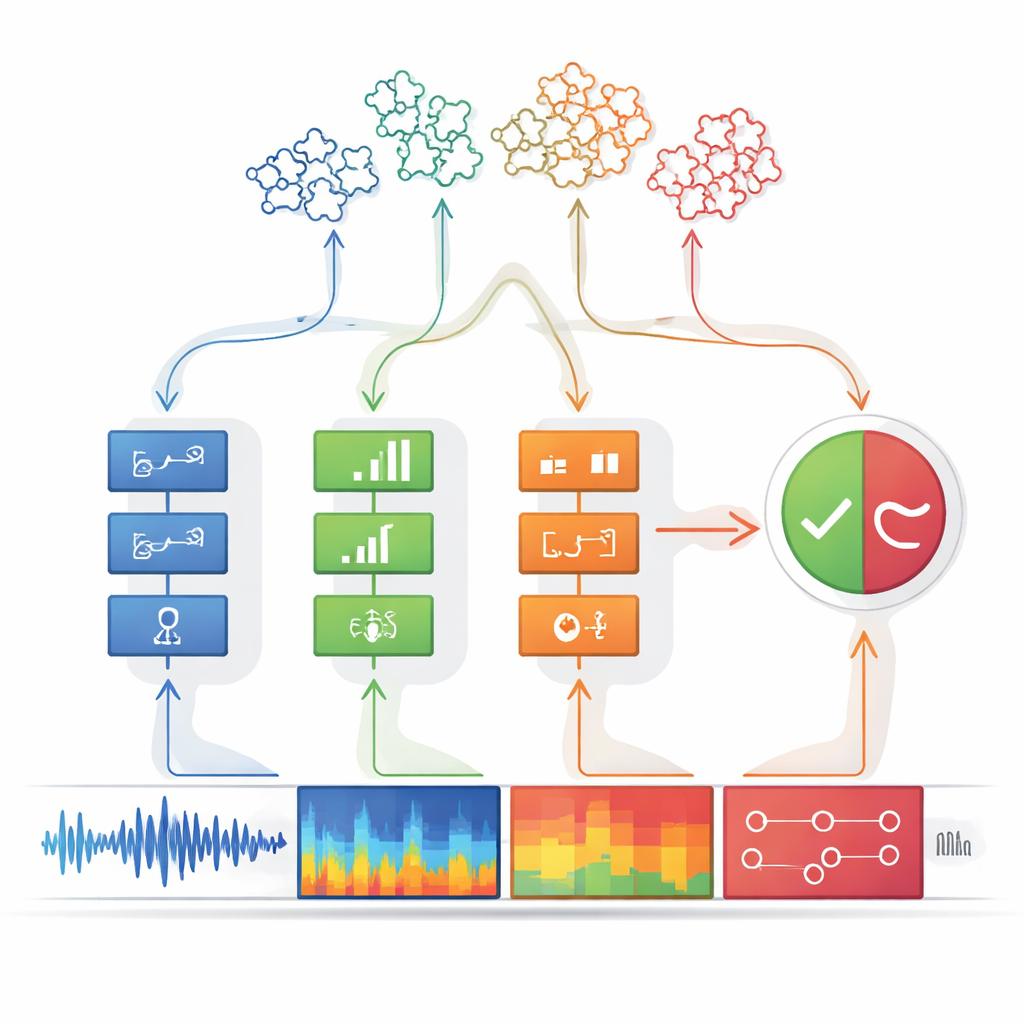
Mantenerse por delante de nuevos tipos de falsificaciones
Una gran fortaleza de este diseño es que puede ampliarse sin empezar de cero. Cuando aparece un nuevo tipo de voz falsa, los ingenieros pueden crear y entrenar un detector adicional especializado en sus artefactos únicos y luego conectarlo al módulo de percepción. Debido a que la etapa de toma de decisiones espera una lista flexible de entradas de pistas, la salida del nuevo detector puede incorporarse sin reentrenar todo el sistema. En pruebas sobre puntos de referencia de suplantación ampliamente usados, la máquina de percepción-decisión igualó o superó a potentes modelos de aprendizaje profundo en ataques conocidos y los aventajó claramente en ataques previamente no vistos. También se adaptó a un nuevo conjunto de datos en idioma chino simplemente añadiendo detectores, mientras que los sistemas competidores tuvieron que reentrenarse por completo y sufrieron de "olvido" sobre cómo manejar ataques anteriores.
Lo que esto significa para la seguridad de la voz cotidiana
Para los no especialistas, la conclusión es que la detección de voces falsas no tiene por qué ser una caja negra misteriosa. Al descomponer el problema en muchas pistas pequeñas y comprensibles y luego combinarlas con reglas lógicas explícitas, los autores construyen un sistema que es a la vez muy preciso y explicable. Así como nuestros cerebros confían en muchas pistas sensoriales antes de formar un juicio, esta máquina reúne y razona sobre diversas señales de falsificación. El resultado es una defensa más robusta contra los deepfakes de audio en constante cambio—una que puede crecer con el tiempo, ayudando a mantener los servicios y las comunicaciones basadas en la voz más seguras para todos.
Cita: Feng, C., Wu, X., Askar, H. et al. Brain-inspired perception-decision machine for fake speech detection. Sci Rep 16, 12273 (2026). https://doi.org/10.1038/s41598-026-41859-8
Palabras clave: deepfake de audio, detección de voz falsa, IA inspirada en el cerebro, seguridad de la voz, aprendizaje incremental