Clear Sky Science · nl
Hersengeïnspireerde waarnemings-besluitmachine voor detectie van valse spraak
Waarom valse stemmen ieders probleem zijn
Het wordt alarmerend eenvoudig om spraak te genereren die net als een echte persoon klinkt, met moderne AI-tools. Deze overtuigende valse stemmen vormen een bedreiging voor alles, van telefonische bankdiensten en slimme luidsprekers tot online vergaderingen en nieuwsitems. De hier beschreven studie gaat een belangrijke vraag te lijf: hoe kunnen we betrouwbare onderscheid maken tussen menselijke spraak en synthetische spraak, zelfs wanneer de onderliggende vervalsingstools blijven veranderen en verbeteren?
Een nieuwe manier om te luisteren naar problemen
De meeste bestaande systemen behandelen detectie van valse spraak als een eenvoudige ja-of-nee classificatieopgave. Ze leren van enorme verzamelingen voorbeelden en proberen een grens te trekken tussen echte en nep-audio. Dat werkt goed voor de soorten valse spraak die ze tijdens training hebben gezien, maar de prestaties nemen af wanneer nieuwe aanvalsmethoden opduiken. De auteurs stellen dat dit de verkeerde denkwijze is. In plaats van één model te dwingen een alles-of-niets beslissing te nemen, suggereren ze het nabootsen van hoe menselijke experts en zelfs de hersenen zelf complexe zintuiglijke informatie verwerken: door te zoeken naar veel kleine, karakteristieke aanwijzingen en daar vervolgens over te redeneren.
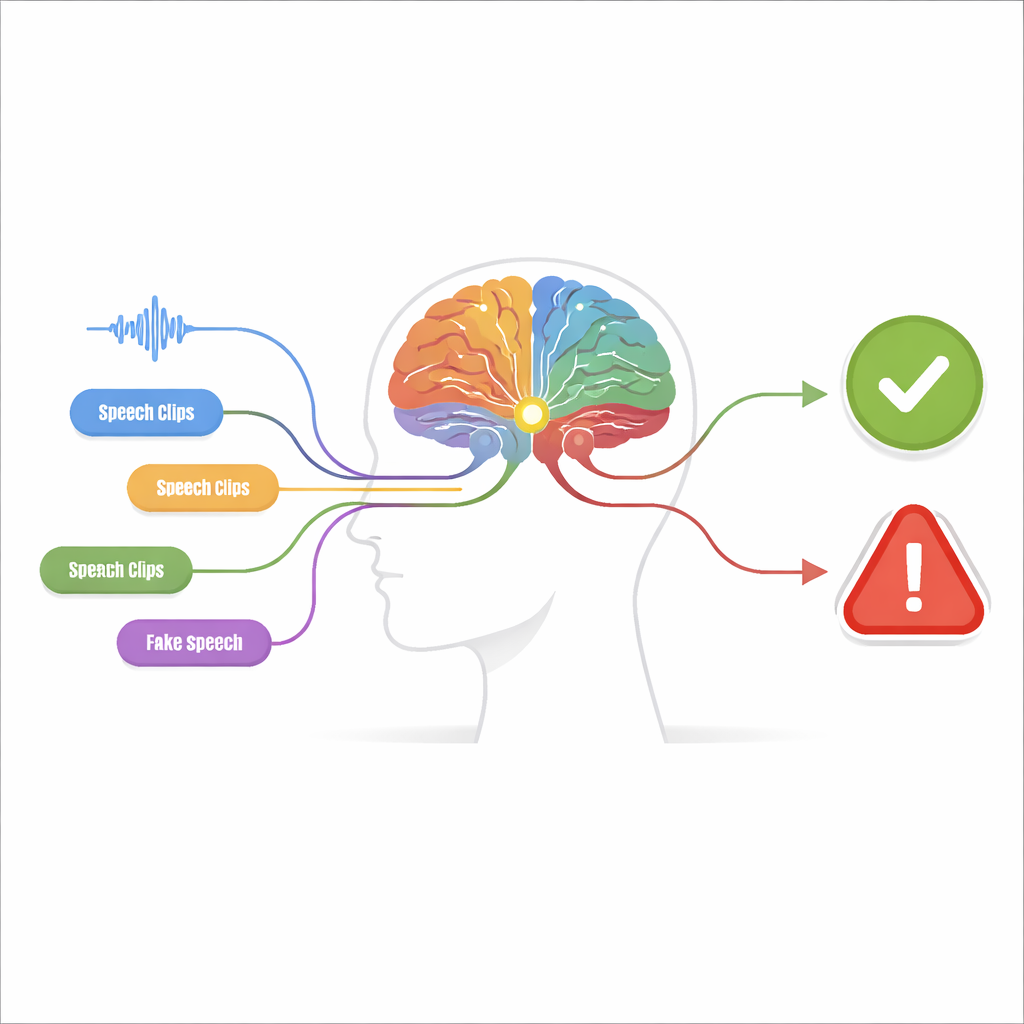
Vele kleine aanwijzingen in plaats van één grote gok
Het voorgestelde systeem, een waarnemings-besluitmachine genoemd, is opgebouwd uit twee fasen. In de waarnemingsfase wordt de audio onderzocht door meerdere onafhankelijke detectoren, elk afgestemd op één specifieke “vervalsingsaanwijzing”. Sommige detectoren richten zich op de ruwe golfvorm en zoeken naar abrupte sprongen en onnatuurlijk gladde patronen. Andere analyseren de frequentie-inhoud, waar valse stemmen vage harmonischen of vreemd gevormde resonanties kunnen vertonen. Aanvullende detectoren bestuderen hoe tijd en frequentie samen evolueren, en vangen mismatches tussen wanneer bepaalde geluiden optreden en welke tonen aanwezig zijn. Een laatste groep analyseert fonemeniveau-details — de kleine klankeenenheden waaruit woorden bestaan — waar valse spraak vaak de subtiele, vloeiende articulatie van een echte spreker mist.
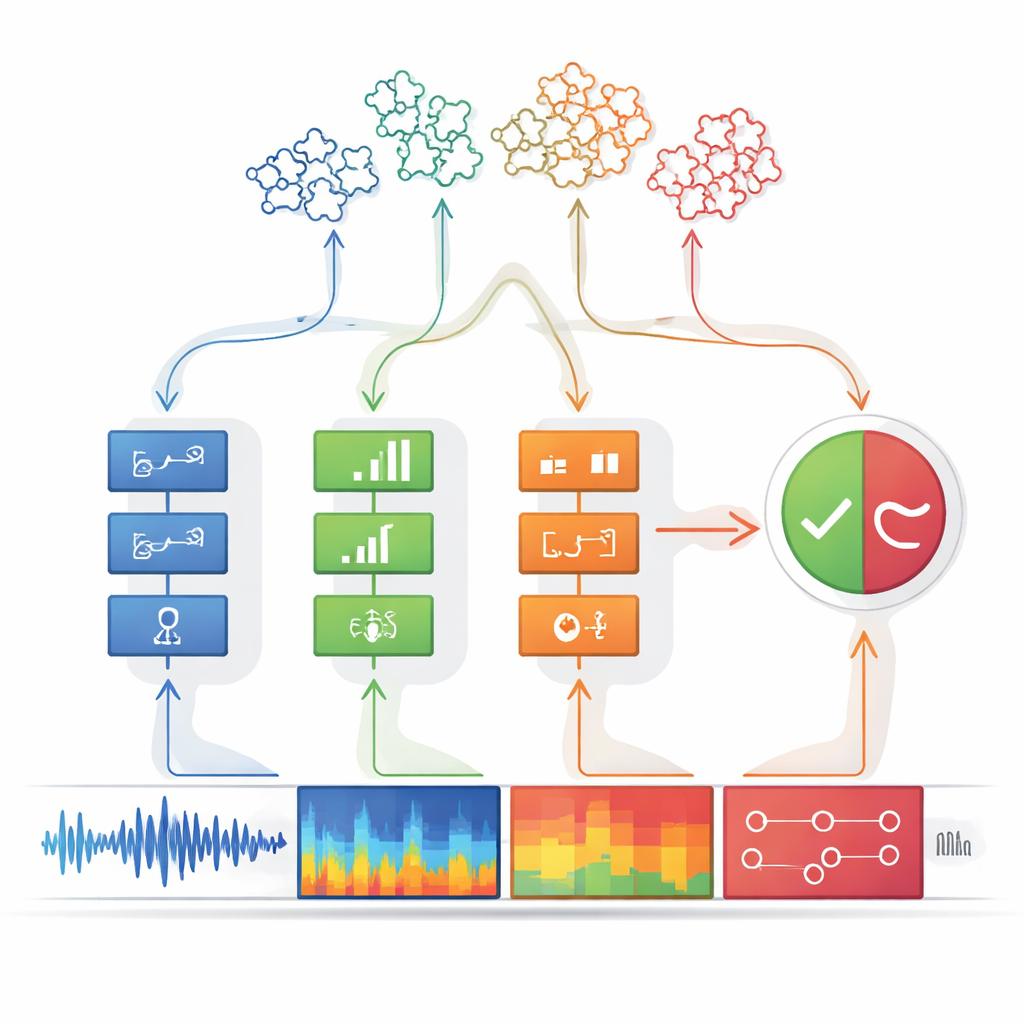
Van aanwijzingenpatronen naar een duidelijke beslissing
Elke detector is ontworpen om extreem voorzichtig te zijn: hij geeft alleen een signaal "aanwezigheid van aanwijzing" wanneer hij vrijwel zeker is, waarbij precisie wordt vooropgesteld boven het opvangen van elke mogelijke vervalsing. De output wordt vereenvoudigd tot een binaire waarde, als een lampje dat aan of uit is. Deze aan-uit signalen worden vervolgens aan de besluitvormingsmodule gevoed. Hier worden groepen aanwijzingen gecombineerd met behulp van beslisbomen — gestructureerde ketens van als-dan regels die lijken op hoe een persoon over bewijs redeneert. Een speciale logische stap, ruwweg vergelijkbaar met een "een van deze is voldoende"-regel, koppelt meerdere bomen aan elkaar. Deze gelaagde redenering verhoogt niet alleen de nauwkeurigheid maar maakt het systeem ook transparanter: je kunt precies terug traceren welke aanwijzingen tot een "nep"-oordeel leidden.
Voorblijven op nieuwe soorten nep
Een belangrijke kracht van dit ontwerp is dat het kan worden uitgebreid zonder helemaal opnieuw te beginnen. Wanneer een nieuw soort valse spraak verschijnt, kunnen ingenieurs een extra detector maken en trainen die gespecialiseerd is in de unieke artefacten daarvan, en die vervolgens in de waarnemingsmodule pluggen. Omdat de besluitvormingsfase een flexibele lijst van aanwijzingsinputs verwacht, kan de output van de nieuwe detector worden opgenomen zonder het hele systeem opnieuw te trainen. In tests op veelgebruikte spoofing-benchmarks behaalde de waarnemings-besluitmachine vergelijkbare of betere resultaten dan krachtige deep-learning baselines bij bekende aanvallen en presteerde duidelijk beter bij eerder ongeziene aanvallen. Het paste zich ook aan een nieuwe dataset in het Chinees aan door simpelweg detectoren toe te voegen, terwijl concurrerende systemen volledig opnieuw getraind moesten worden en last kregen van het "vergeten" hoe eerdere aanvallen behandeld moesten worden.
Wat dit betekent voor dagelijkse spraakbeveiliging
Voor niet-specialisten is de conclusie dat detectie van valse spraak geen mysterieuze zwarte doos hoeft te zijn. Door het probleem op te delen in veel kleine, begrijpelijke aanwijzingen en die vervolgens te combineren met expliciete logische regels, bouwen de auteurs een systeem dat zowel zeer nauwkeurig als uitlegbaar is. Net zoals onze hersenen op veel zintuiglijke hints vertrouwen voordat ze een oordeel vormen, verzamelt en redeneert deze machine over diverse tekenen van vervalsing. Het resultaat is een robuustere verdediging tegen voortdurend veranderende audio-deepfakes — een systeem dat in de loop van de tijd kan groeien en zo helpt spraakgebaseerde diensten en communicatie voor iedereen veiliger te houden.
Bronvermelding: Feng, C., Wu, X., Askar, H. et al. Brain-inspired perception-decision machine for fake speech detection. Sci Rep 16, 12273 (2026). https://doi.org/10.1038/s41598-026-41859-8
Trefwoorden: audio deepfake, detectie van valse spraak, hersengeïnspireerde AI, spraakbeveiliging, incrementeel leren