Clear Sky Science · de
Gehirninspirierte Wahrnehmungs-Entscheidungsmaschine zur Erkennung gefälschter Sprache
Warum gefälschte Stimmen ein Problem für alle sind
Es wird alarmierend einfach, mit modernen KI-Werkzeugen Sprache zu erzeugen, die wie eine echte Person klingt. Diese überzeugenden gefälschten Stimmen bedrohen alles von Telefonbanking und smarten Lautsprechern bis hin zu Online-Meetings und Nachrichtenberichten. Die hier beschriebene Studie widmet sich einer zentralen Frage: Wie können wir zuverlässig zwischen menschlicher und synthetischer Sprache unterscheiden, selbst wenn sich die zugrundeliegenden Fälschungstools ständig ändern und verbessern?
Eine neue Art, auf Probleme zu hören
Die meisten bestehenden Systeme behandeln die Erkennung gefälschter Sprache wie eine einfache Ja‑/Nein-Klassifikationsaufgabe. Sie lernen aus riesigen Beispielsammlungen und versuchen, eine Grenze zwischen echter und gefälschter Audiodatei zu ziehen. Das funktioniert gut für die Arten von Fälschungen, die während des Trainings gesehen wurden, doch die Leistung sinkt, sobald neue Angriffsmethoden auftauchen. Die Autor:innen argumentieren, dass das die falsche Denkweise ist. Statt ein einzelnes Modell zu zwingen, eine alles-oder-nichts-Entscheidung zu treffen, schlagen sie vor, nachzuahmen, wie menschliche Expert:innen und sogar das Gehirn selbst mit komplexen Sinnesinformationen umgehen: durch Suche nach vielen kleinen, charakteristischen Hinweisen und anschließende reasoning darüber.
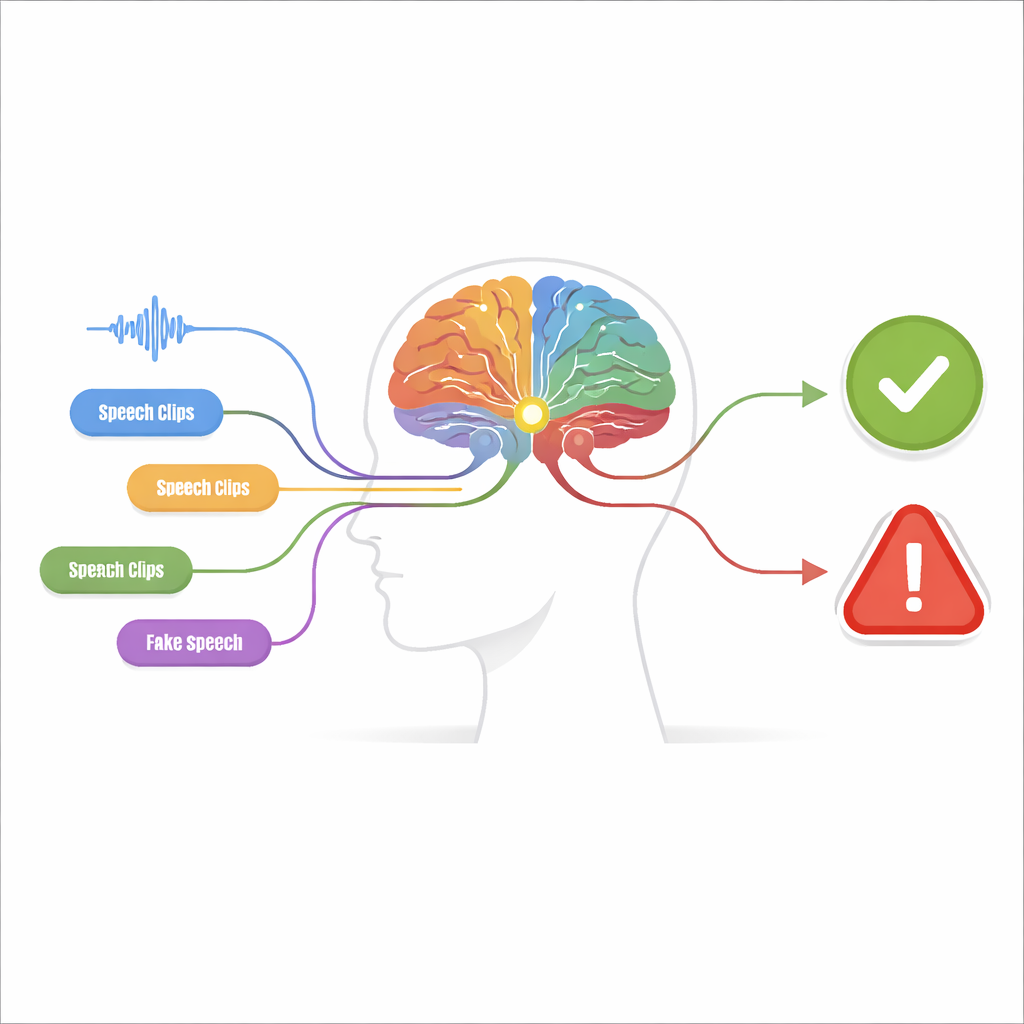
Viele kleine Hinweise statt einer großen Vermutung
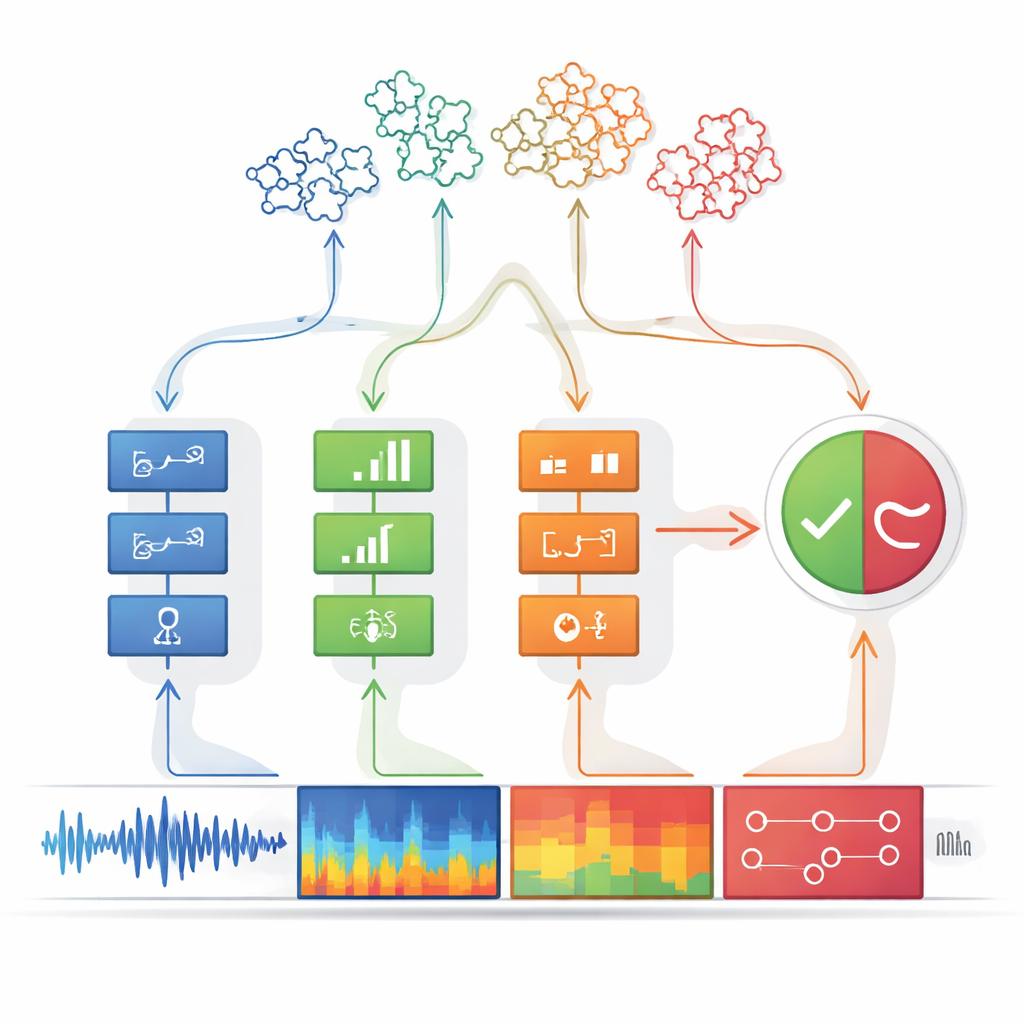
Das vorgeschlagene System, genannt Wahrnehmungs-Entscheidungsmaschine, ist in zwei Stufen aufgebaut. In der Wahrnehmungsstufe wird das Audio von mehreren unabhängigen Detektoren untersucht, von denen jeder auf einen bestimmten „Fälschungs-Hinweis“ abgestimmt ist. Einige Detektoren konzentrieren sich auf die Rohwellenform und suchen nach abrupten Sprüngen und unnatürlich glatten Mustern. Andere analysieren den Frequenzinhalt, wo gefälschte Stimmen verschwommene Obertöne oder ungewöhnlich geformte Resonanzen zeigen können. Weitere Detektoren betrachten die gemeinsame Entwicklung von Zeit und Frequenz, um Diskrepanzen zwischen dem Zeitpunkt bestimmter Laute und den vorhandenen Tonhöhen zu erkennen. Eine letzte Gruppe analysiert phonemische Details – die winzigen Lautbausteine, aus denen Wörter bestehen – bei denen gefälschte Sprache oft die subtile, fließende Artikulation einer echten Sprecherin oder eines echten Sprechers vermissen lässt.
Von Hinweis-Mustern zu einer klaren Entscheidung
Jeder Detektor ist so konzipiert, dass er extrem vorsichtig agiert: Er signalisiert nur „Hinweis vorhanden“, wenn er sich fast sicher ist, und legt dabei Wert auf Präzision statt darauf, jede mögliche Fälschung zu erfassen. Seine Ausgabe wird auf einen binären Wert vereinfacht, wie ein Licht, das entweder an oder aus ist. Diese Ein‑/Aus‑Signale werden dann in das Entscheidungsmodul eingespeist. Dort werden Gruppen von Hinweisen mithilfe von Entscheidungsbäumen kombiniert – strukturierten If‑Then‑Regeln, die der Art und Weise ähneln, wie eine Person über Beweise nachdenken könnte. Ein spezieller Logikschritt, etwa vergleichbar mit einer Regel „jeder dieser Hinweise reicht aus“, verknüpft mehrere Bäume. Dieses geschichtete Reasoning erhöht nicht nur die Genauigkeit, sondern macht das System auch transparenter: Man kann genau zurückverfolgen, welche Hinweise zu einem „gefälscht“-Urteil geführt haben.
Neuen Arten von Fälschungen einen Schritt voraus bleiben
Eine der großen Stärken dieses Entwurfs ist, dass er erweitert werden kann, ohne von vorn zu beginnen. Wenn eine neue Art gefälschter Sprache auftaucht, können Ingenieur:innen einen zusätzlichen Detektor entwickeln und trainieren, der auf deren spezifische Artefakte spezialisiert ist, und ihn dann in das Wahrnehmungsmodul einstecken. Da die Entscheidungsstufe eine flexible Liste von Hinweis-Eingängen erwartet, lässt sich die Ausgabe des neuen Detektors einbinden, ohne das gesamte System neu zu trainieren. In Tests auf weit verbreiteten Spoofing-Benchmarks erreichte die Wahrnehmungs-Entscheidungsmaschine die Leistungsfähigkeit starker Deep‑Learning-Baselines bei bekannten Angriffen und übertraf diese deutlich bei zuvor nicht gesehenen Angriffen. Sie passte sich auch an einen neuen chinesischsprachigen Datensatz an, indem einfach Detektoren hinzugefügt wurden, während konkurrierende Systeme vollständig neu trainiert werden mussten und unter dem Problem des „Vergessens“ früherer Angriffe litten.
Was das für die alltägliche Stimm‑Sicherheit bedeutet
Für Nicht‑Spezialist:innen lautet die Quintessenz: Die Erkennung gefälschter Sprache muss kein mysteriöser Blackbox‑Prozess sein. Indem das Problem in viele kleine, verständliche Hinweise zerlegt und diese dann mit expliziten logischen Regeln kombiniert werden, bauen die Autor:innen ein System, das sowohl hochpräzise als auch erklärbar ist. So wie unser Gehirn sich auf viele sensorische Hinweise stützt, bevor es ein Urteil fällt, sammelt und bewertet diese Maschine vielfältige Anzeichen von Manipulation. Das Ergebnis ist ein robusterer Schutz gegen sich ständig wandelnde Audio‑Deepfakes – ein System, das im Laufe der Zeit wachsen kann und dazu beiträgt, sprachbasierte Dienste und Kommunikation für alle sicherer zu machen.
Zitation: Feng, C., Wu, X., Askar, H. et al. Brain-inspired perception-decision machine for fake speech detection. Sci Rep 16, 12273 (2026). https://doi.org/10.1038/s41598-026-41859-8
Schlüsselwörter: Audio-Deepfake, Erkennung gefälschter Sprache, gehirninspirierte KI, Stimm-Sicherheit, inkrementelles Lernen