Clear Sky Science · en
Brain-inspired perception-decision machine for fake speech detection
Why fake voices are everyone’s problem
It is becoming alarmingly easy to generate speech that sounds just like a real person, using modern artificial intelligence tools. These convincing fake voices threaten everything from phone banking and smart speakers to online meetings and news reports. The study described here tackles a key question: how can we reliably tell human speech apart from synthetic speech, even as the underlying forgery tools keep changing and improving?
A new way to listen for trouble
Most existing systems treat fake speech detection like a simple yes-or-no classification task. They learn from huge collections of examples and try to draw a boundary between real and fake audio. This works well on the types of fake speech they have seen during training, but performance drops when new attack methods appear. The authors argue that this is the wrong mindset. Instead of forcing a single model to make an all-or-nothing decision, they suggest mimicking how human experts and even the brain itself handle complex sensory information: by looking for many small, telltale clues and then reasoning about them.
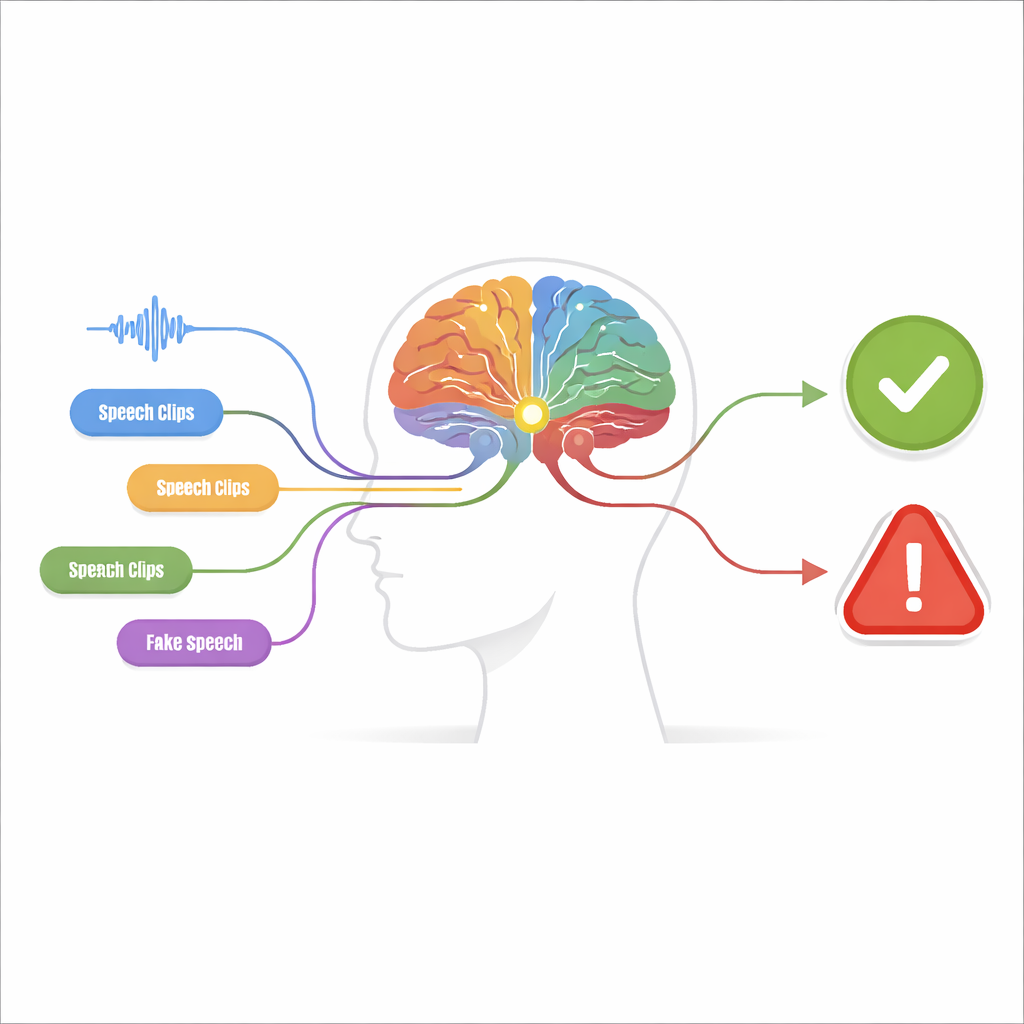
Many small clues instead of one big guess
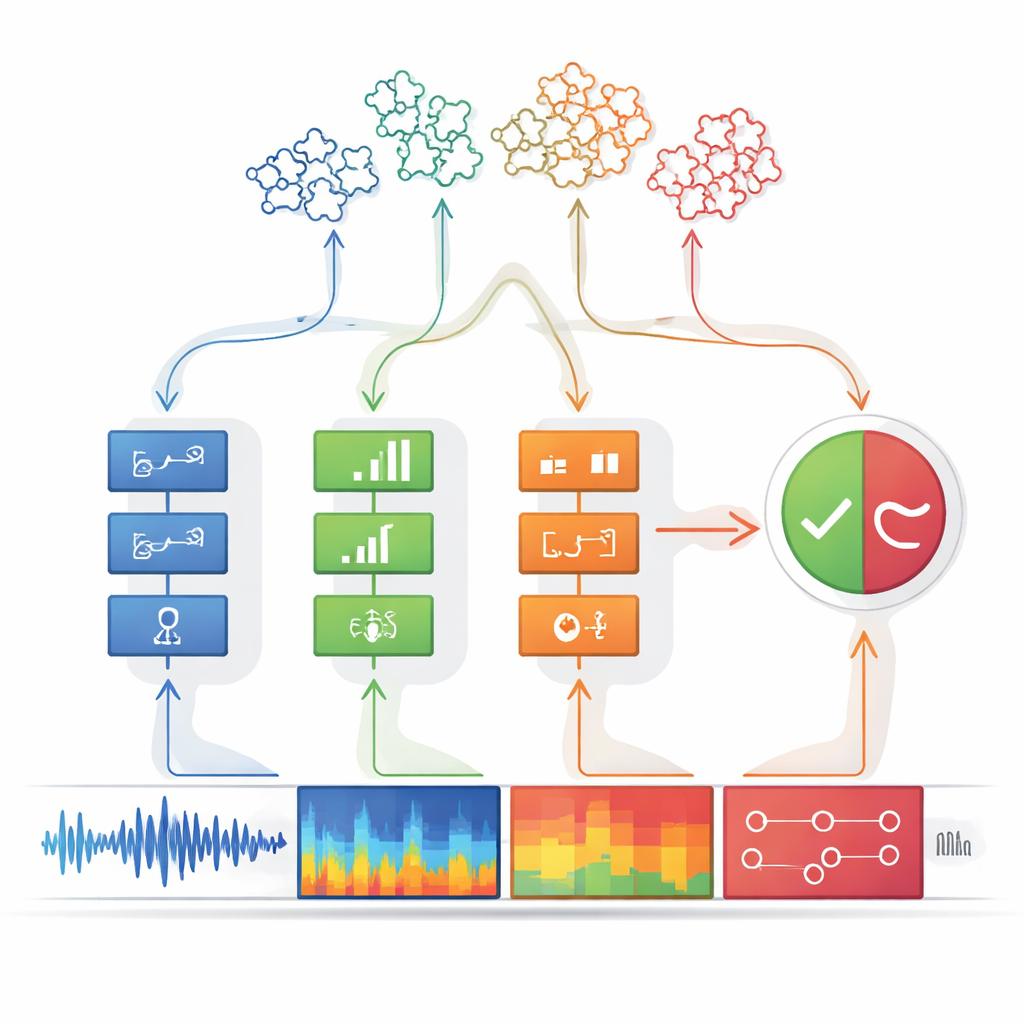
The proposed system, called a perception-decision machine, is built in two stages. In the perception stage, the audio is examined by multiple independent detectors, each tuned to one specific “forgery clue.” Some detectors focus on the raw waveform, searching for abrupt jumps and unnaturally smooth patterns. Others examine the frequency content, where fake voices may show blurred harmonics or oddly shaped resonances. Additional detectors look at how time and frequency evolve together, catching mismatches between when certain sounds occur and which tones are present. A final group analyzes phoneme-level details—the tiny sound units that form words—where fake speech often lacks the subtle, fluid articulation of a real speaker.
From clue patterns to a clear decision
Each detector is designed to be extremely cautious: it only signals “clue present” when it is almost certain, prioritizing precision over catching every possible fake. Its output is simplified to a binary value, like a light that is either on or off. These on–off signals are then fed into the decision-making module. Here, groups of clues are combined using decision trees—structured chains of if–then rules that resemble the way a person might reason about evidence. A special logic step, roughly similar to an “any of these is enough” rule, ties multiple trees together. This layered reasoning not only boosts accuracy but also makes the system more transparent: one can trace back exactly which clues led to a “fake” judgment.
Staying ahead of new kinds of fakes
A major strength of this design is that it can be extended without starting over. When a new kind of fake speech appears, engineers can create and train an additional detector specialized for its unique artifacts, then plug it into the perception module. Because the decision-making stage expects a flexible list of clue inputs, the new detector’s output can be incorporated without retraining the entire system. In tests on widely used spoofing benchmarks, the perception-decision machine matched or surpassed powerful deep-learning baselines on familiar attacks and clearly outperformed them on previously unseen ones. It also adapted to a new Chinese-language dataset by simply adding detectors, while competing systems had to be fully retrained and suffered from “forgetting” how to handle earlier attacks.
What this means for everyday voice security
For non-specialists, the takeaway is that fake speech detection does not have to be a mysterious black box. By breaking the problem into many small, understandable clues and then combining them with explicit logical rules, the authors build a system that is both highly accurate and explainable. Just as our brains rely on many sensory hints before forming a judgment, this machine gathers and reasons over diverse signs of forgery. The result is a more robust guard against ever-changing audio deepfakes—one that can grow over time, helping keep voice-based services and communications safer for everyone.
Citation: Feng, C., Wu, X., Askar, H. et al. Brain-inspired perception-decision machine for fake speech detection. Sci Rep 16, 12273 (2026). https://doi.org/10.1038/s41598-026-41859-8
Keywords: audio deepfake, fake speech detection, brain-inspired AI, voice security, incremental learning