Clear Sky Science · pl
Maszyna percepcja-decyzja inspirowana mózgiem do wykrywania fałszywych nagrań mowy
Dlaczego fałszywe głosy dotyczą nas wszystkich
Generowanie mowy brzmiącej jak prawdziwa osoba staje się alarmująco proste dzięki współczesnym narzędziom sztucznej inteligencji. Te przekonujące fałszywe głosy zagrażają wszystkim — od bankowości telefonicznej i inteligentnych głośników po spotkania online i relacje informacyjne. Opisane tu badanie zajmuje się kluczowym pytaniem: jak można wiarygodnie odróżnić mowę ludzką od syntetycznej, nawet gdy stosowane narzędzia fałszowania ciągle się zmieniają i ulepszają?
Nowy sposób słuchania problemów
Większość istniejących systemów traktuje wykrywanie fałszywej mowy jak prostą decyzję tak/nie. Uczą się na ogromnych zbiorach przykładów i próbują wyznaczyć granicę między dźwiękiem prawdziwym a fałszywym. To działa dobrze dla typów fałszywej mowy widzianych podczas trenowania, ale wydajność spada, gdy pojawiają się nowe metody ataku. Autorzy twierdzą, że to niewłaściwe podejście. Zamiast zmuszać pojedynczy model do podejmowania decyzji „wszystko albo nic”, proponują naśladować sposób, w jaki eksperci i sam mózg radzą sobie ze skomplikowanymi informacjami sensorycznymi: poprzez poszukiwanie wielu małych, charakterystycznych wskazówek, a następnie rozumowanie na ich podstawie.
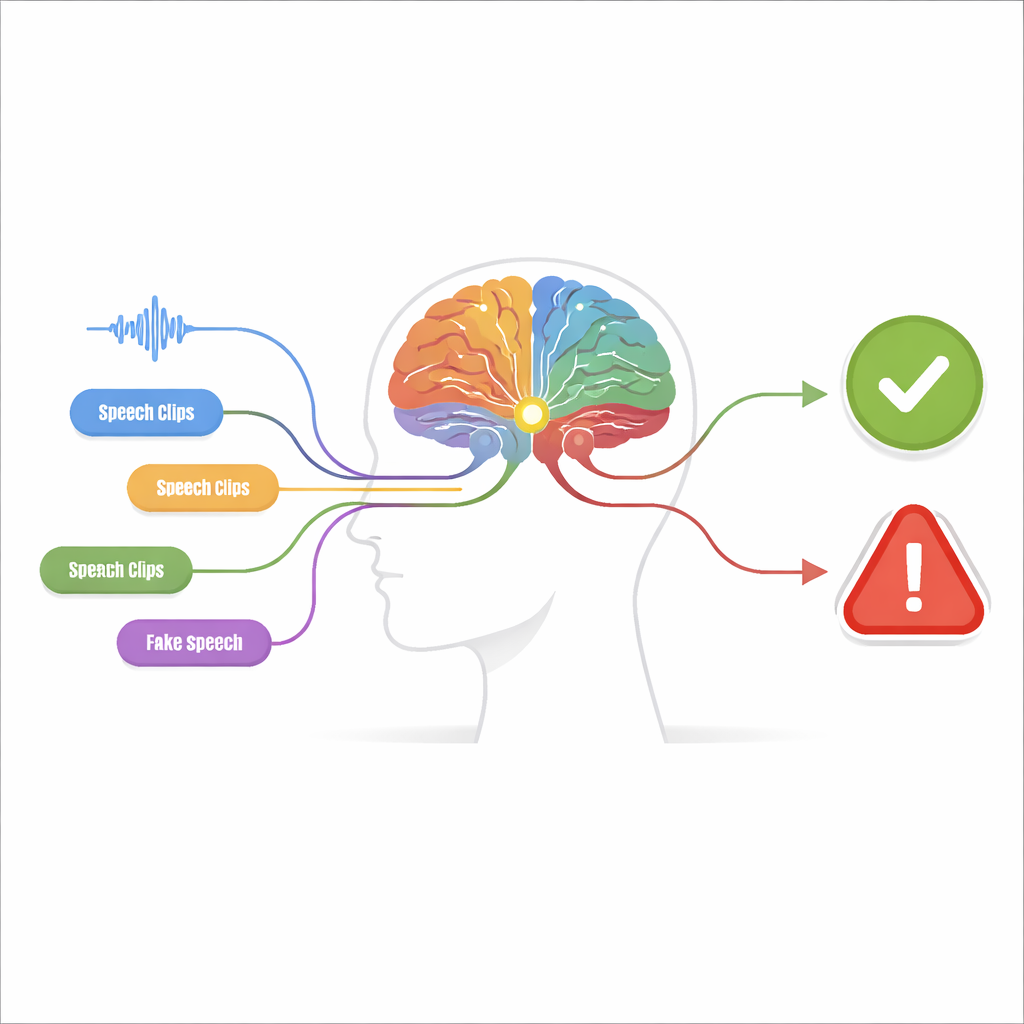
Wiele małych wskazówek zamiast jednej wielkiej zgadywanki
Proponowany system, nazwany maszyną percepcja-decyzja, składa się z dwóch etapów. W etapie percepcji audio jest analizowane przez wiele niezależnych detektorów, z których każdy jest wyczulony na jedną, konkretną „wskazówkę fałszerstwa”. Niektóre detektory skupiają się na surowej fali dźwiękowej, poszukując nagłych skoków i nienaturalnie gładkich wzorców. Inne badają zawartość częstotliwościową, gdzie fałszywe głosy mogą wykazywać rozmyte harmoniczne lub dziwnie ukształtowane rezonanse. Dodatkowe detektory obserwują współzmienność czasu i częstotliwości, wychwytując niespójności między momentem wystąpienia dźwięków a obecnymi tonami. Ostatnia grupa analizuje szczegóły na poziomie fonemów — drobnych jednostek dźwiękowych tworzących słowa — gdzie fałszywa mowa często brakuje subtelnej, płynnej artykulacji prawdziwego mówcy.
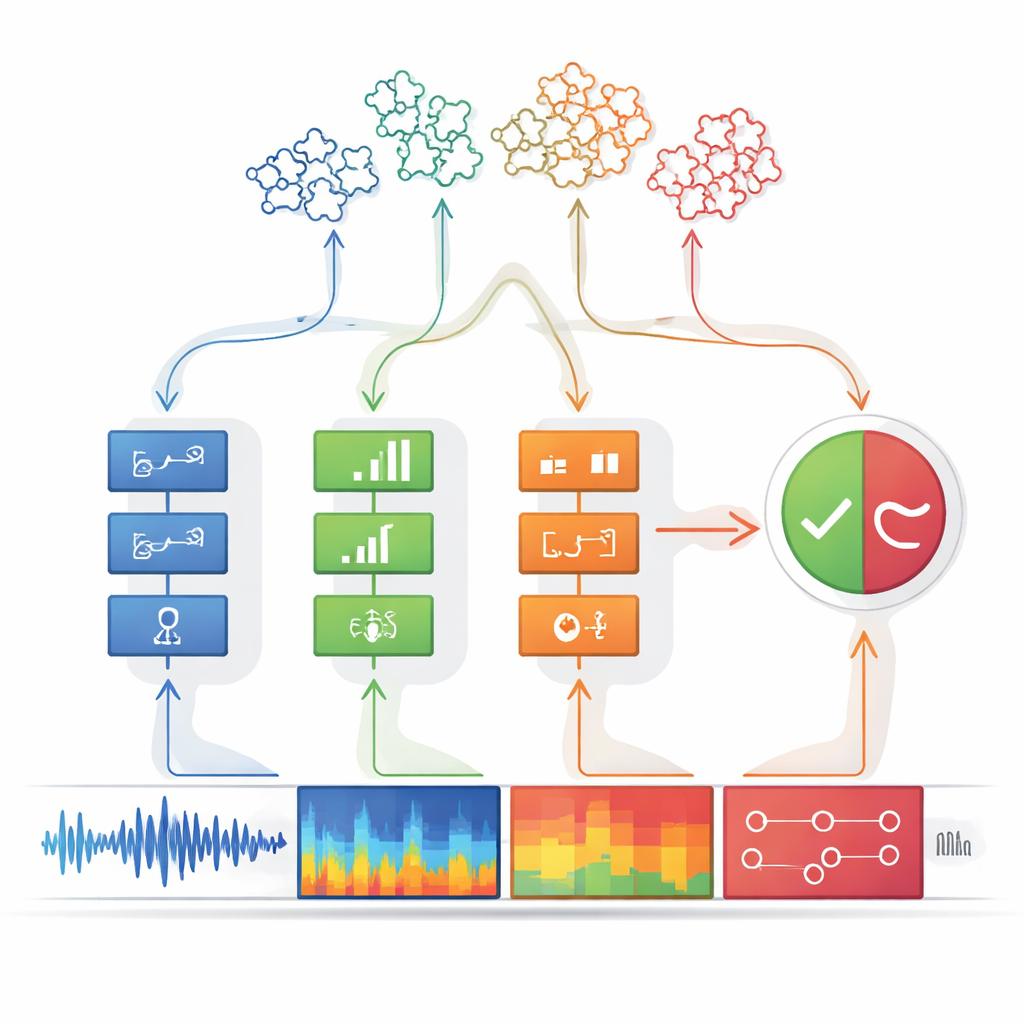
Od wzorców wskazówek do jasnej decyzji
Każdy detektor zaprojektowano, by być wyjątkowo ostrożnym: sygnalizuje „wskazówka obecna” tylko gdy jest niemal pewny, priorytetowo traktując precyzję nad wykrywaniem każdej możliwej fałszywki. Jego wyjście upraszczane jest do wartości binarnej, jak światło zapalone lub zgaszone. Te sygnały włącz/wyłącz trafiają następnie do modułu decyzyjnego. Tam grupy wskazówek są łączone za pomocą drzew decyzyjnych — zorganizowanych łańcuchów reguł jeśli–to przypominających sposób, w jaki osoba mogłaby rozumować nad dowodami. Specjalny krok logiczny, przypominający regułę „wystarczy dowolna z tych”, wiąże ze sobą wiele drzew. Takie warstwowe rozumowanie nie tylko poprawia dokładność, ale też zwiększa przejrzystość systemu: można dokładnie odtworzyć, które wskazówki doprowadziły do orzeczenia „fałsz”.
Wyprzedzanie nowych rodzajów fałszerstw
Główną zaletą tego projektu jest możliwość rozbudowy bez zaczynania od zera. Gdy pojawia się nowy rodzaj fałszywej mowy, inżynierowie mogą stworzyć i wyszkolić dodatkowy detektor wyspecjalizowany w wykrywaniu jego unikalnych artefaktów, a następnie podłączyć go do modułu percepcji. Ponieważ etap decyzyjny oczekuje elastycznej listy wejść wskazówek, wyjście nowego detektora można włączyć bez potrzeby retrenowania całego systemu. W testach na powszechnie używanych benchmarkach do wykrywania oszustw maszyna percepcja-decyzja dorównała lub przewyższyła potężne modele uczenia głębokiego w znanych atakach i wyraźnie je pokonała w przypadkach wcześniej niewidzianych. Dostosowała się także do nowego chińskojęzycznego zestawu danych poprzez prostą dodawkę detektorów, podczas gdy konkurencyjne systemy musiały być trenowane od nowa i cierpiały na „zapominanie” wcześniejszych ataków.
Co to oznacza dla codziennego bezpieczeństwa głosowego
Dla osób niebędących specjalistami najważniejszy wniosek jest taki, że wykrywanie fałszywej mowy nie musi być tajemniczą czarną skrzynką. Dzieląc problem na wiele małych, zrozumiałych wskazówek i łącząc je następnie za pomocą jawnych reguł logicznych, autorzy stworzyli system zarówno wysoce dokładny, jak i wyjaśnialny. Tak jak nasze mózgi polegają na wielu wskazówkach sensorycznych przed wydaniem osądu, ta maszyna zbiera i rozumuje nad różnorodnymi sygnałami fałszerstwa. Efekt to bardziej odporny strażnik przed stale zmieniającymi się audio-deepfakes — taki, który może rosnąć z czasem i pomagać w zabezpieczaniu usług i komunikacji głosowej dla wszystkich.
Cytowanie: Feng, C., Wu, X., Askar, H. et al. Brain-inspired perception-decision machine for fake speech detection. Sci Rep 16, 12273 (2026). https://doi.org/10.1038/s41598-026-41859-8
Słowa kluczowe: audio deepfake, wykrywanie fałszywej mowy, Sztuczna inteligencja inspirowana mózgiem, bezpieczeństwo głosowe, uczenie przyrostowe