Clear Sky Science · sv
Hjärnliknande perceptions-beslutsmaskin för upptäckt av falskt tal
Varför falska röster är allas problem
Det blir alarmerande lätt att skapa tal som låter precis som en verklig person med moderna AI-verktyg. Dessa övertygande falska röster hotar allt från telefonbanker och smarta högtalare till onlinemöten och nyhetsinslag. Studien som beskrivs här tar sig an en nyckelfråga: hur kan vi på ett pålitligt sätt skilja mänskligt tal från syntetiskt tal, även när verktygen för förfalskning förändras och förbättras?
Ett nytt sätt att lyssna efter problem
De flesta befintliga system behandlar upptäckt av falskt tal som en enkel ja-eller-nej-klassificering. De lär sig från stora samlingar av exempel och försöker dra en gräns mellan verkligt och fejk ljud. Det fungerar bra för de typer av förfalskningar de sett under träning, men prestationen sjunker när nya attackmetoder dyker upp. Författarna menar att detta är fel inställning. Istället för att tvinga en enda modell att fatta ett allt-eller-inget-beslut föreslår de att härma hur mänskliga experter och till och med hjärnan själv hanterar komplex sensorisk information: genom att leta efter många små, talande ledtrådar och sedan resonera kring dem.
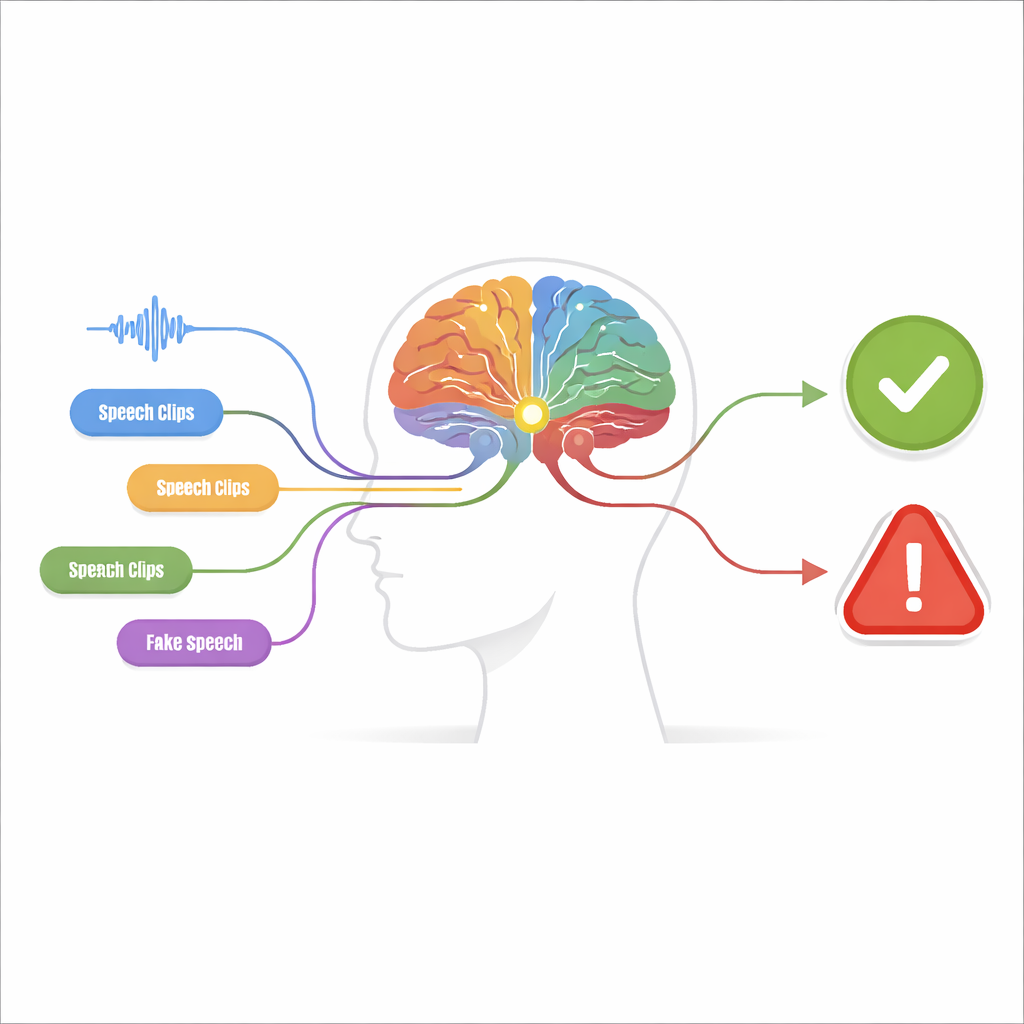
Många små ledtrådar istället för ett stort gissande
Det föreslagna systemet, kallat en perceptions-beslutsmaskin, är uppbyggt i två steg. I perceptionssteget undersöks ljudet av flera oberoende detektorer, var och en inställd på en specifik ”förfalskningsledtråd”. Vissa detektorer fokuserar på råvågformen och söker efter plötsliga hopp och onaturligt jämna mönster. Andra granskar frekvensinnehållet, där fejkade röster kan visa suddiga harmoniska strukturer eller märkligt formade resonanser. Ytterligare detektorer tittar på hur tid och frekvens utvecklas tillsammans och fångar missanpassningar mellan när vissa ljud uppträder och vilka toner som är närvarande. En sista grupp analyserar fonemnivådetaljer—de små ljudenheter som bygger upp ord—där falskt tal ofta saknar den subtila, flytande artikulationen hos en verklig talare.
Från mönster av ledtrådar till ett tydligt beslut
Varje detektor är utformad för att vara extremt försiktig: den signalerar endast ”ledtråd närvarande” när den är nästan säker och prioriterar precision framför att fånga varje möjlig förfalskning. Dess utgång förenklas till ett binärt värde, som en lampa som antingen är på eller av. Dessa på–av-signaler matas sedan in i beslutsmodulen. Här kombineras grupper av ledtrådar med hjälp av beslutsträd—strukturerade kedjor av om–så-regler som liknar hur en person kan resonera kring bevis. Ett särskilt logiksteg, ungefär liknande en regel om ”någon av dessa räcker”, länkar flera träd samman. Detta flerskiktade resonemang förbättrar inte bara noggrannheten utan gör också systemet mer transparent: man kan spåra exakt vilka ledtrådar som ledde till en bedömning av ”fejk”.
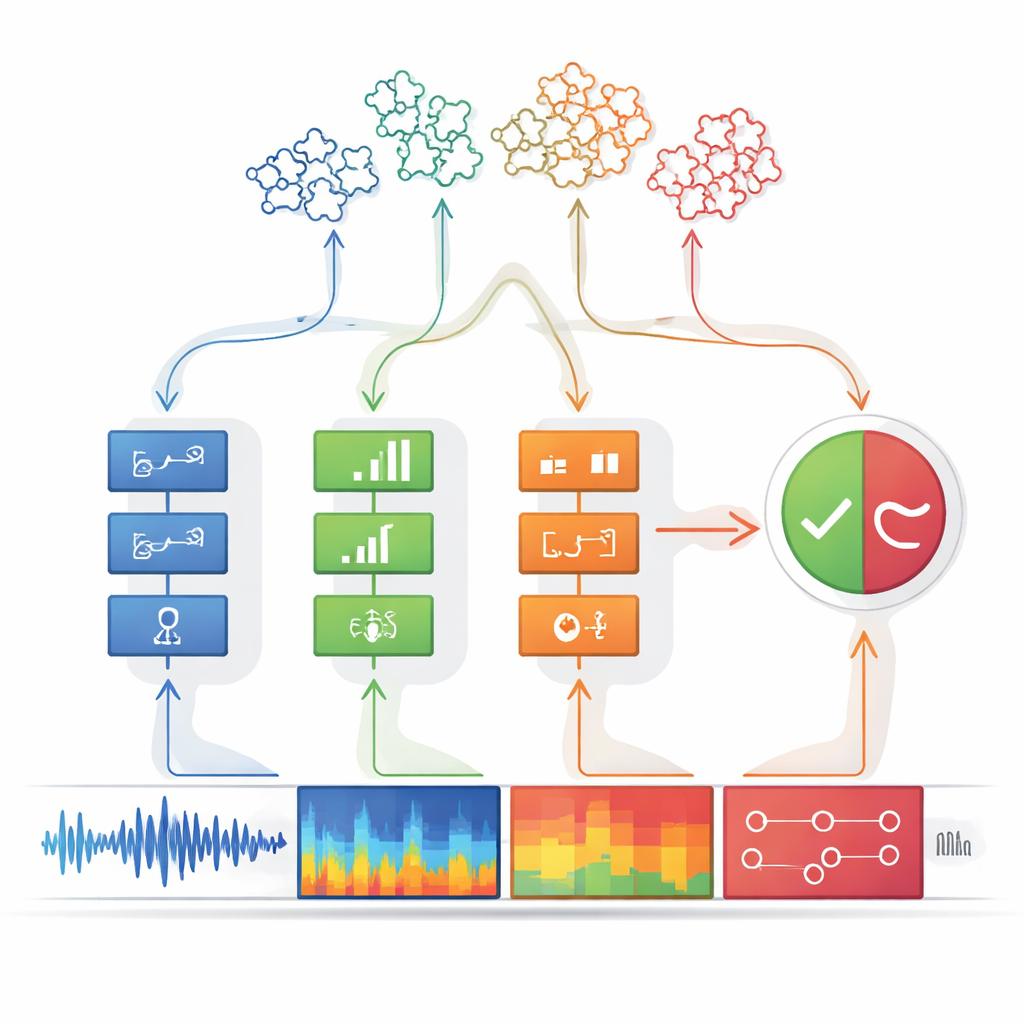
Hålla sig före nya typer av förfalskningar
En stor styrka i denna design är att den kan utökas utan att börja om från början. När en ny typ av falskt tal dyker upp kan ingenjörer skapa och träna en ytterligare detektor specialiserad på dess unika artefakter och sedan plugga in den i perceptionsmodulen. Eftersom beslutssteget förväntar sig en flexibel lista av ledtrådsinmatningar kan den nya detektorns utgång införlivas utan att hela systemet behöver omtränas. I tester på välanvända spoofing-benchmarks matchade perceptions-beslutsmaskinen eller överträffade kraftfulla djupinlärningsbaslinjer på kända attacker och presterade tydligt bättre på tidigare osedda attacker. Den anpassade sig också till en ny dataset på kinesiska genom att helt enkelt lägga till detektorer, medan konkurrerande system var tvungna att tränas om helt och drabbades av att ”glömma” hur tidigare attacker hanterades.
Vad detta betyder för vardaglig röstsäkerhet
För icke-specialister är slutsatsen att upptäckt av falskt tal inte behöver vara en mystisk svart låda. Genom att dela upp problemet i många små, förståeliga ledtrådar och sedan kombinera dem med uttryckliga logiska regler bygger författarna ett system som både är mycket noggrant och förklarligt. Precis som våra hjärnor litar på många sensoriska antydningar innan de formar en bedömning, samlar denna maskin in och resonerar över mångfaldiga tecken på förfalskning. Resultatet är en mer robust skyddsmekanism mot ständigt föränderliga ljuddeepfakes—en som kan växa över tid och hjälpa till att hålla röstbaserade tjänster och kommunikationer säkrare för alla.
Citering: Feng, C., Wu, X., Askar, H. et al. Brain-inspired perception-decision machine for fake speech detection. Sci Rep 16, 12273 (2026). https://doi.org/10.1038/s41598-026-41859-8
Nyckelord: audio deepfake, upptäckt av falskt tal, hjärnliknande AI, röstsäkerhet, inkrementell inlärning