Clear Sky Science · pt
Máquina de percepção-decisão inspirada no cérebro para detecção de fala falsa
Por que vozes falsas são problema de todo mundo
Está ficando alarmantemente fácil gerar fala que soa exatamente como uma pessoa real, usando as ferramentas modernas de inteligência artificial. Essas vozes convincentes ameaçam desde serviços bancários por telefone e alto-falantes inteligentes até reuniões online e reportagens. O estudo descrito aqui aborda uma questão central: como podemos distinguir de forma confiável fala humana de fala sintética, mesmo quando as ferramentas de falsificação subjacentes continuam mudando e melhorando?
Uma nova maneira de ouvir sinais de problema
A maioria dos sistemas existentes trata a detecção de fala falsa como uma tarefa simples de classificação sim/não. Eles aprendem a partir de grandes coleções de exemplos e tentam traçar um limite entre áudio real e falso. Isso funciona bem para os tipos de falsificações que viram durante o treinamento, mas o desempenho cai quando surgem novos métodos de ataque. Os autores argumentam que esse é o raciocínio equivocado. Em vez de forçar um único modelo a tomar uma decisão binária, eles sugerem imitar a forma como especialistas humanos e até o próprio cérebro lidam com informações sensoriais complexas: procurando muitos pequenos indícios reveladores e então raciocinando sobre eles.
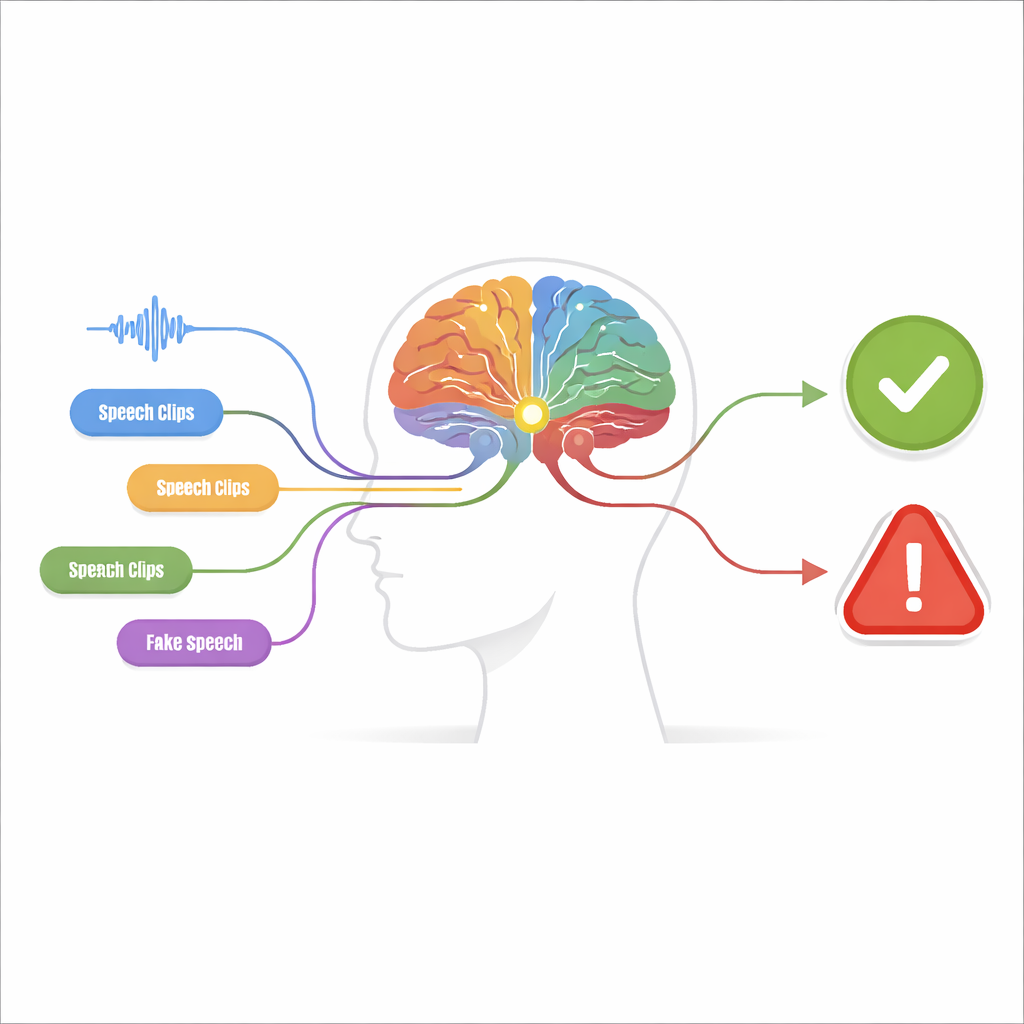
Muitos pequenos indícios em vez de um grande palpite
O sistema proposto, chamado de máquina de percepção-decisão, é construído em duas etapas. Na etapa de percepção, o áudio é examinado por múltiplos detectores independentes, cada um sintonizado para um "indício de falsificação" específico. Alguns detectores se concentram na forma de onda bruta, procurando saltos abruptos e padrões artificialmente suaves. Outros examinam o conteúdo de frequência, onde vozes falsas podem apresentar harmônicos borrados ou ressonâncias de formato estranho. Detectores adicionais observam como tempo e frequência evoluem juntos, captando descompassos entre quando certos sons ocorrem e quais tons estão presentes. Um grupo final analisa detalhes ao nível de fonemas — as pequenas unidades sonoras que formam as palavras — onde a fala falsa frequentemente carece da articulação sutil e fluida de um falante real.
De padrões de indícios a uma decisão clara
Cada detector é projetado para ser extremamente cauteloso: só sinaliza "indício presente" quando está quase certo, priorizando precisão em vez de capturar todas as falsificações possíveis. Sua saída é simplificada para um valor binário, como uma luz que está ligada ou desligada. Esses sinais liga/desliga são então encaminhados ao módulo de tomada de decisão. Ali, grupos de indícios são combinados usando árvores de decisão — cadeias estruturadas de regras se-então que se assemelham à forma como uma pessoa poderia raciocinar sobre evidências. Um passo lógico especial, aproximadamente similar a uma regra de "qualquer um desses é suficiente", conecta múltiplas árvores. Esse raciocínio em camadas não apenas aumenta a precisão, como também torna o sistema mais transparente: é possível rastrear exatamente quais indícios levaram a um julgamento de "falso".
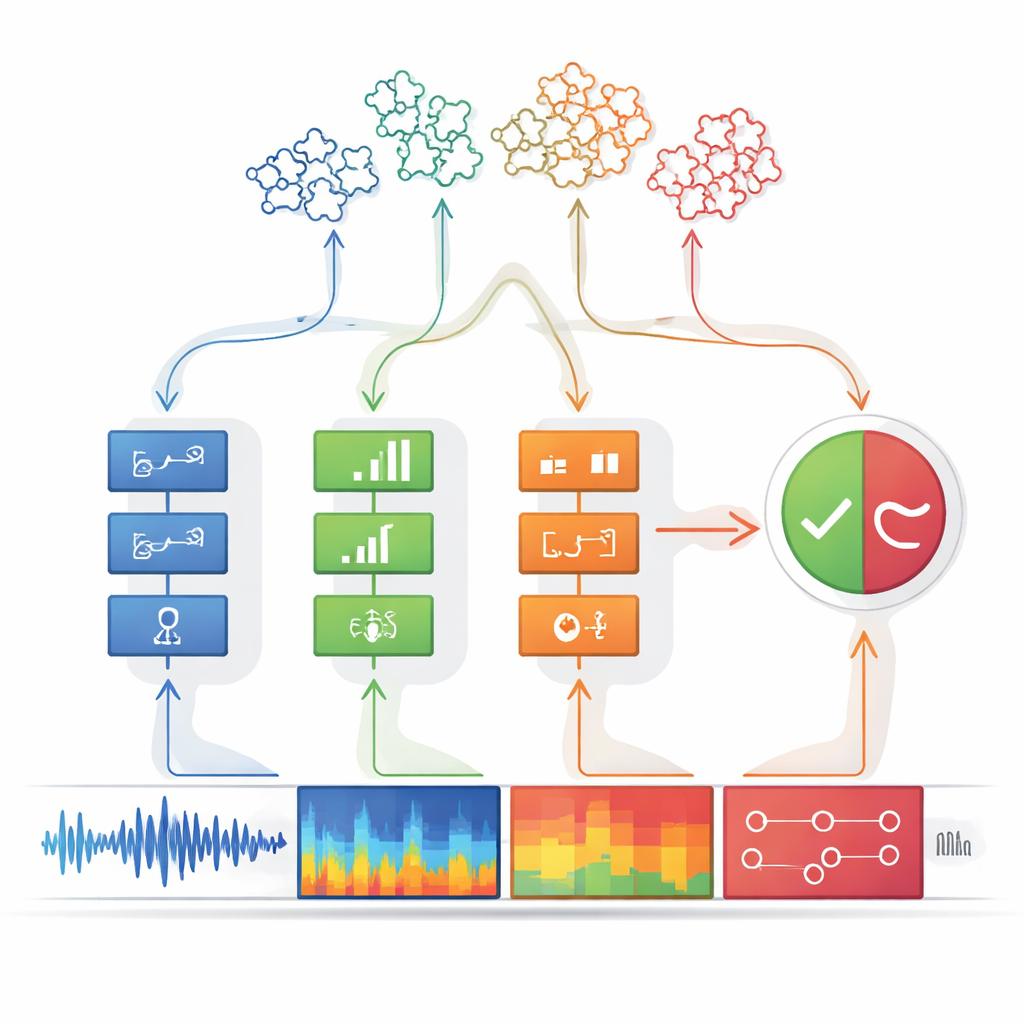
Antecipando novos tipos de falsificações
Uma grande vantagem desse desenho é que ele pode ser estendido sem começar do zero. Quando surge um novo tipo de fala falsa, os engenheiros podem criar e treinar um detector adicional especializado em seus artefatos únicos e então conectá‑lo ao módulo de percepção. Como a etapa de decisão espera uma lista flexível de entradas de indícios, a saída do novo detector pode ser incorporada sem re-treinar todo o sistema. Em testes em benchmarks amplamente usados de spoofing, a máquina de percepção-decisão igualou ou superou poderosas linhas de base de deep learning em ataques conhecidos e claramente as superou em ataques previamente não vistos. Ela também se adaptou a um novo conjunto de dados em chinês simplesmente adicionando detectores, enquanto sistemas concorrentes precisaram ser totalmente re-treinados e sofreram de "esquecimento" sobre como lidar com ataques anteriores.
O que isso significa para a segurança de voz no dia a dia
Para não especialistas, a conclusão é que a detecção de fala falsa não precisa ser uma caixa-preta misteriosa. Ao dividir o problema em muitos pequenos indícios compreensíveis e então combiná‑los com regras lógicas explícitas, os autores constroem um sistema que é tanto altamente preciso quanto explicável. Assim como nossos cérebros dependem de muitos sinais sensoriais antes de formar um julgamento, essa máquina reúne e raciocina sobre sinais diversos de falsificação. O resultado é uma proteção mais robusta contra deepfakes de áudio sempre mutantes — uma que pode crescer ao longo do tempo, ajudando a manter serviços e comunicações baseados em voz mais seguros para todos.
Citação: Feng, C., Wu, X., Askar, H. et al. Brain-inspired perception-decision machine for fake speech detection. Sci Rep 16, 12273 (2026). https://doi.org/10.1038/s41598-026-41859-8
Palavras-chave: deepfake de áudio, detecção de fala falsa, IA inspirada no cérebro, segurança de voz, aprendizado incremental