Clear Sky Science · it
Macchina di percezione-decisione ispirata al cervello per il rilevamento di discorsi falsi
Perché le voci false sono un problema per tutti
Diventa allarmantemente semplice generare discorsi che suonano proprio come una persona reale, grazie agli strumenti moderni di intelligenza artificiale. Queste voci false convincenti mettono a rischio tutto, dal banking telefonico e dagli smart speaker alle riunioni online e ai servizi di informazione. Lo studio descritto qui affronta una domanda centrale: come possiamo distinguere in modo affidabile il parlato umano da quello sintetico, anche quando gli strumenti di contraffazione sottostanti continuano a cambiare e migliorare?
Un nuovo modo di ascoltare i problemi
La maggior parte dei sistemi esistenti tratta il rilevamento del parlato falso come un semplice compito di classificazione sì-o-no. Imparano da enormi raccolte di esempi e cercano di tracciare una frontiera tra audio reale e falso. Questo funziona bene sui tipi di falsificazione visti durante l'addestramento, ma le prestazioni calano quando compaiono nuovi metodi d'attacco. Gli autori sostengono che questa sia la mentalità sbagliata. Invece di costringere un singolo modello a prendere una decisione assoluta, propongono di imitare il modo in cui gli esperti umani e persino il cervello stesso gestiscono informazioni sensoriali complesse: cercando molti piccoli indizi rivelatori e poi ragionando su di essi.
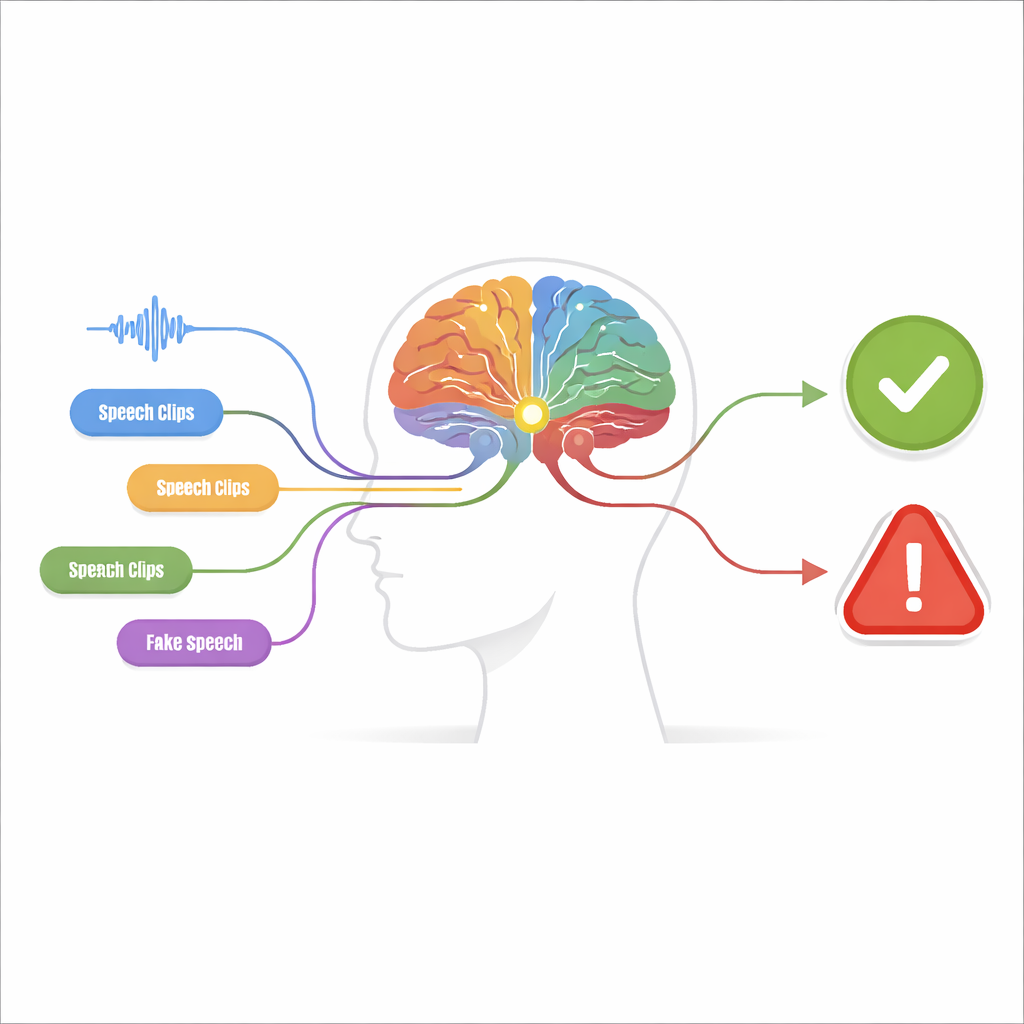
Molti piccoli indizi invece di un’unica grande ipotesi
Il sistema proposto, chiamato macchina di percezione-decisione, è costruito in due fasi. Nella fase di percezione, l’audio viene esaminato da molteplici rivelatori indipendenti, ciascuno sintonizzato su uno specifico “indizio di contraffazione”. Alcuni rivelatori si concentrano sulla forma d’onda grezza, cercando salti bruschi e pattern innaturalmente lisci. Altri esaminano il contenuto in frequenza, dove le voci false possono mostrare armoniche sfocate o risonanze dalla forma anomala. Altri ancora osservano come tempo e frequenza evolvono insieme, cogliendo discrasie tra quando certi suoni si manifestano e quali toni sono presenti. Un ultimo gruppo analizza dettagli a livello di fonemi—quelle minuscole unità sonore che formano le parole—dove il parlato falso spesso manca della sottile, fluida articolazione di un parlante reale.
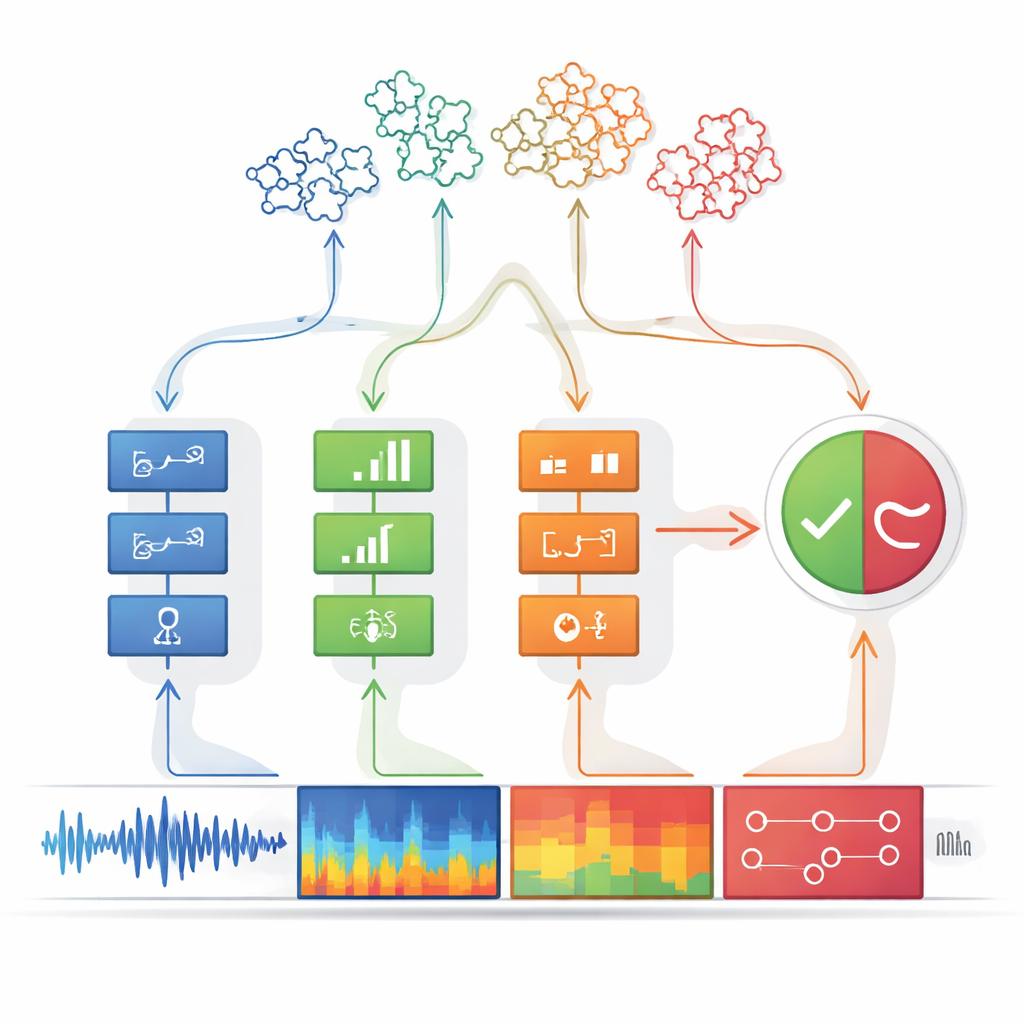
Dai pattern di indizi a una decisione chiara
Ogni rivelatore è progettato per essere estremamente prudente: segnala “indizio presente” solo quando è quasi certo, privilegiando la precisione rispetto al catturare ogni possibile falso. La sua uscita è semplificata in un valore binario, come una luce che è accesa o spenta. Questi segnali on–off vengono poi inviati al modulo di decisione. Qui, gruppi di indizi si combinano usando alberi decisionali—catene strutturate di regole if–then che assomigliano al modo in cui una persona potrebbe ragionare sulle prove. Un passaggio logico speciale, grosso modo simile a una regola “qualunque di questi è sufficiente”, lega più alberi insieme. Questo ragionamento a livelli non solo migliora l’accuratezza ma rende il sistema più trasparente: è possibile risalire esattamente a quali indizi hanno portato a un giudizio di “falso”.
Restare avanti rispetto a nuove tipologie di falsi
Un punto di forza importante di questo disegno è che può essere esteso senza ricominciare da zero. Quando compare una nuova tipologia di parlato falso, gli ingegneri possono creare e addestrare un rivelatore aggiuntivo specializzato nei suoi artefatti unici, quindi inserirlo nel modulo di percezione. Poiché la fase di decisione si aspetta una lista flessibile di input di indizi, l’output del nuovo rivelatore può essere incorporato senza riaddestrare l’intero sistema. Nei test su benchmark di spoofing ampiamente usati, la macchina di percezione-decisione ha eguagliato o superato potenti modelli deep-learning negli attacchi familiari e li ha chiaramente battuti su quelli precedentemente inesplorati. Si è inoltre adattata a un nuovo dataset in lingua cinese semplicemente aggiungendo rivelatori, mentre i sistemi concorrenti hanno dovuto essere completamente riaddestrati e hanno sofferto di “dimenticanza” rispetto agli attacchi precedenti.
Cosa significa per la sicurezza vocale di tutti i giorni
Per i non specialisti, la conclusione è che il rilevamento del parlato falso non deve essere una scatola nera misteriosa. Spezzando il problema in molti piccoli indizi comprensibili e combinandoli poi con regole logiche esplicite, gli autori costruiscono un sistema che è allo stesso tempo altamente accurato e spiegabile. Proprio come i nostri cervelli si affidano a molti indizi sensoriali prima di formare un giudizio, questa macchina raccoglie e ragiona su segni diversi della contraffazione. Il risultato è una protezione più robusta contro i deepfake audio in continua evoluzione—una soluzione che può crescere nel tempo, aiutando a mantenere più sicuri i servizi e le comunicazioni basate sulla voce per tutti.
Citazione: Feng, C., Wu, X., Askar, H. et al. Brain-inspired perception-decision machine for fake speech detection. Sci Rep 16, 12273 (2026). https://doi.org/10.1038/s41598-026-41859-8
Parole chiave: deepfake audio, rilevamento del parlato falso, IA ispirata al cervello, sicurezza vocale, apprendimento incrementale