Clear Sky Science · ru
Машина восприятия-решения, вдохновлённая мозгом, для обнаружения фейковой речи
Почему поддельные голоса — проблема для всех
Современные инструменты искусственного интеллекта делают всё более лёгким создание речи, которая звучит как настоящий человек. Эти правдоподобные фальшивые голоса угрожают всему: от телефонного банкинга и «умных» колонок до онлайн-встреч и новостных репортажей. Описанное здесь исследование решает ключевой вопрос: как надёжно отличать человеческую речь от синтетической, даже когда инструменты подделки постоянно меняются и совершенствуются?
Новый способ «слушать» признаки подделки
Большинство существующих систем рассматривают обнаружение фейковой речи как простую задачу классификации «да-или-нет». Они обучаются на огромных наборах примеров и пытаются провести границу между реальным и поддельным звуком. Это хорошо работает для типов подделок, которые были в обучающей выборке, но производительность падает при появлении новых методов атак. Авторы утверждают, что такой подход ошибочен. Вместо того чтобы заставлять одну модель принимать всеобъемлющее решение, они предлагают имитировать то, как специалисты и сам мозг обрабатывают сложную сенсорную информацию: искать множество мелких, характерных подсказок и затем рассуждать о них.
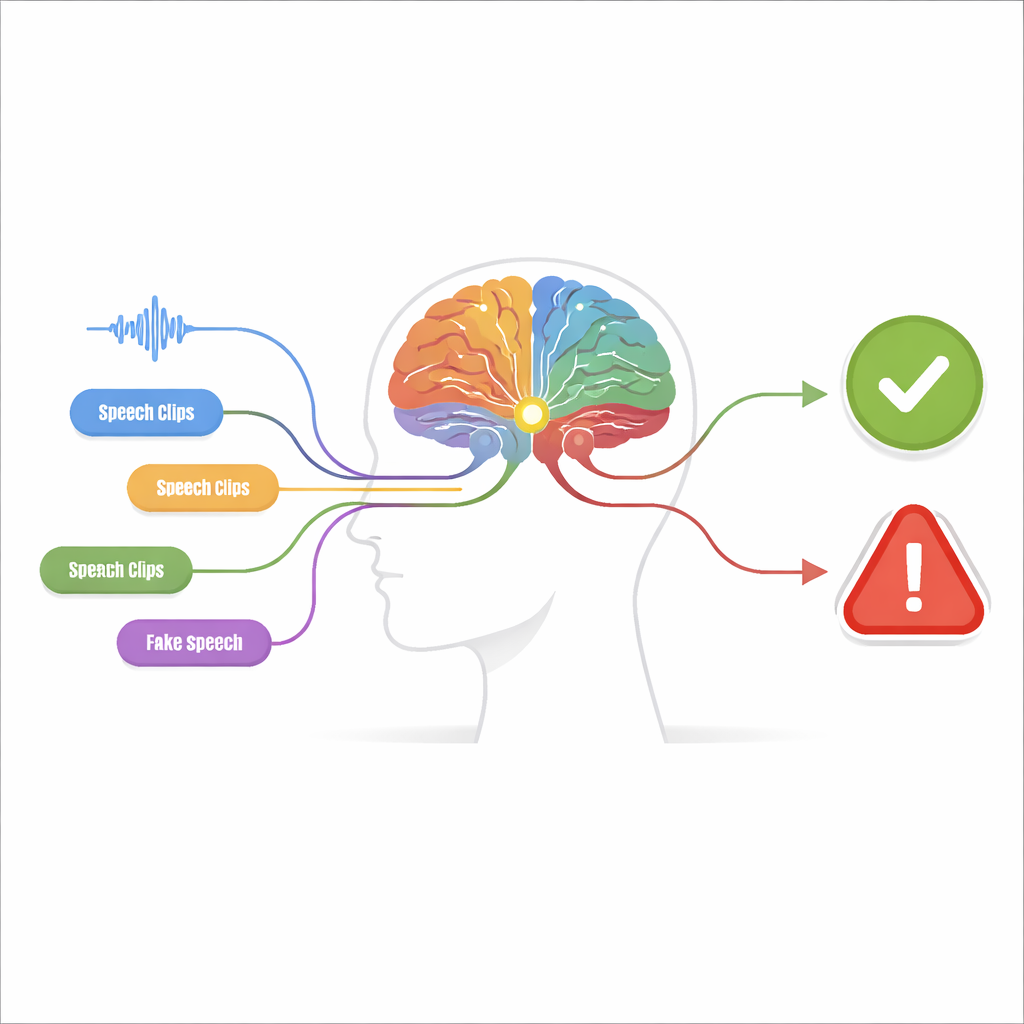
Множество мелких подсказок вместо одной общей догадки
Предложенная система, названная машиной восприятия-решения, построена в два этапа. На стадии восприятия аудиосигнал анализируют несколько независимых детекторов, каждый из которых настроен на одну конкретную «подсказку подделки». Одни детекторы фокусируются на исходной волновой форме, иская резкие скачки и неестественно сглаженные участки. Другие изучают частотное содержание, где у фейковых голосов могут быть размытые гармоники или странно сформированные резонансы. Дополнительные детекторы отслеживают совместную эволюцию времени и частоты, улавливая несоответствия между моментами появления звуков и наличием определённых тонов. Последняя группа анализирует фонемные детали — крошечные звуковые единицы, из которых состоят слова, — где у поддельной речи часто отсутствует тонкая, плавная артикуляция настоящего оратора.
От шаблонов подсказок к ясному решению
Каждый детектор спроектирован быть исключительно осторожным: он сигнализирует «подсказка обнаружена» только когда почти уверен, отдавая приоритет точности перед попыткой поймать все возможные фейки. Его выход упрощён до бинарного значения, как свет, который либо включён, либо выключен. Эти сигналы «вкл/выкл» затем подаются в модуль принятия решений. Здесь группы подсказок комбинируются с помощью деревьев решений — структурированных цепочек правил если–то, напоминающих рассуждение человека о доказательствах. Специальный логический шаг, примерно соответствующий правилу «достаточно любой из этих подсказок», связывает несколько деревьев вместе. Такая многоуровневая логика не только повышает точность, но и делает систему более прозрачной: можно проследить, какие именно подсказки привели к решению «фейк».
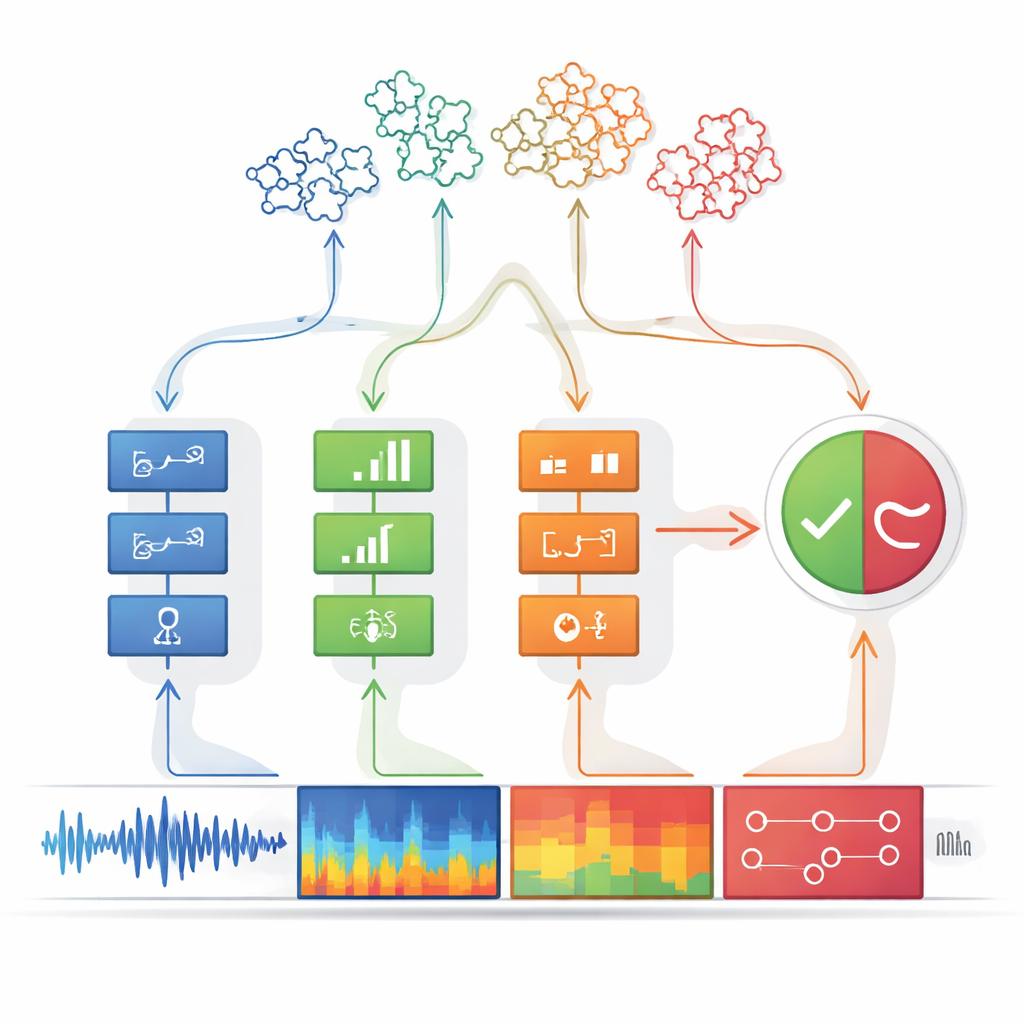
Опережать новые виды подделок
Главное преимущество этой архитектуры в том, что её можно расширять, не начиная всё заново. Когда появляется новый тип фейковой речи, инженеры могут создать и обучить дополнительный детектор, специализированный на его уникальных артефактах, и интегрировать его в модуль восприятия. Поскольку стадия принятия решений ожидает гибкий список входных подсказок, вывод нового детектора можно добавить без переобучения всей системы. В тестах на общепринятых бенчмарках по спуфингу машина восприятия-решения сравнялась или превзошла мощные глубокие модели на известных атаках и явно опередила их на ранее невидимых. Она также адаптировалась к новому китайскоязычному набору данных просто добавлением детекторов, тогда как конкурирующие системы требовали полного дообучения и страдали от «забывания» ранее освоенных атак.
Что это значит для повседневной голосовой безопасности
Для неспециалистов вывод таков: обнаружение фейковой речи не обязательно должно быть таинственной «чёрной коробкой». Разбивая задачу на множество небольших и понятных подсказок и затем комбинируя их с явными логическими правилами, авторы создают систему, которая одновременно высокоточная и объяснимая. Точно так же, как наш мозг опирается на множество сенсорных намёков перед вынесением суждения, эта машина собирает и рассуждает о разнообразных признаках подделки. В результате получается более надёжная защита от постоянно меняющихся аудио-дипфейков — система, которая может со временем расти и помогать сделать голосовые сервисы и коммуникации безопаснее для всех.
Цитирование: Feng, C., Wu, X., Askar, H. et al. Brain-inspired perception-decision machine for fake speech detection. Sci Rep 16, 12273 (2026). https://doi.org/10.1038/s41598-026-41859-8
Ключевые слова: аудио дипфейк, обнаружение фейковой речи, искусственный интеллект, вдохновлённый мозгом, защита голоса, инкрементное обучение