Clear Sky Science · fr
Machine perception-décision inspirée du cerveau pour la détection de la parole truquée
Pourquoi les voix truquées concernent tout le monde
Il devient alarmantement facile de générer une voix qui ressemble à une personne réelle grâce aux outils d’intelligence artificielle modernes. Ces voix convaincantes menacent tout, des services bancaires par téléphone et des enceintes connectées aux réunions en ligne et aux reportages. L’étude décrite ici aborde une question essentielle : comment distinguer de façon fiable la parole humaine de la parole synthétique, alors même que les outils de falsification évoluent et s’améliorent en permanence ?
Une nouvelle façon d’écouter les problèmes
La plupart des systèmes existants traitent la détection de parole truquée comme une simple tâche de classification binaire. Ils apprennent à partir d’immenses collections d’exemples et cherchent à tracer une frontière entre l’audio réel et l’audio faux. Cela fonctionne bien pour les types de contrefaçons vus pendant l’entraînement, mais les performances chutent quand apparaissent de nouvelles méthodes d’attaque. Les auteurs soutiennent que cette approche est erronée. Plutôt que de forcer un modèle unique à rendre une décision tout ou rien, ils proposent d’imiter la manière dont les experts humains — et même le cerveau — traitent une information sensorielle complexe : en recherchant de nombreux petits indices révélateurs puis en raisonnant à leur sujet.
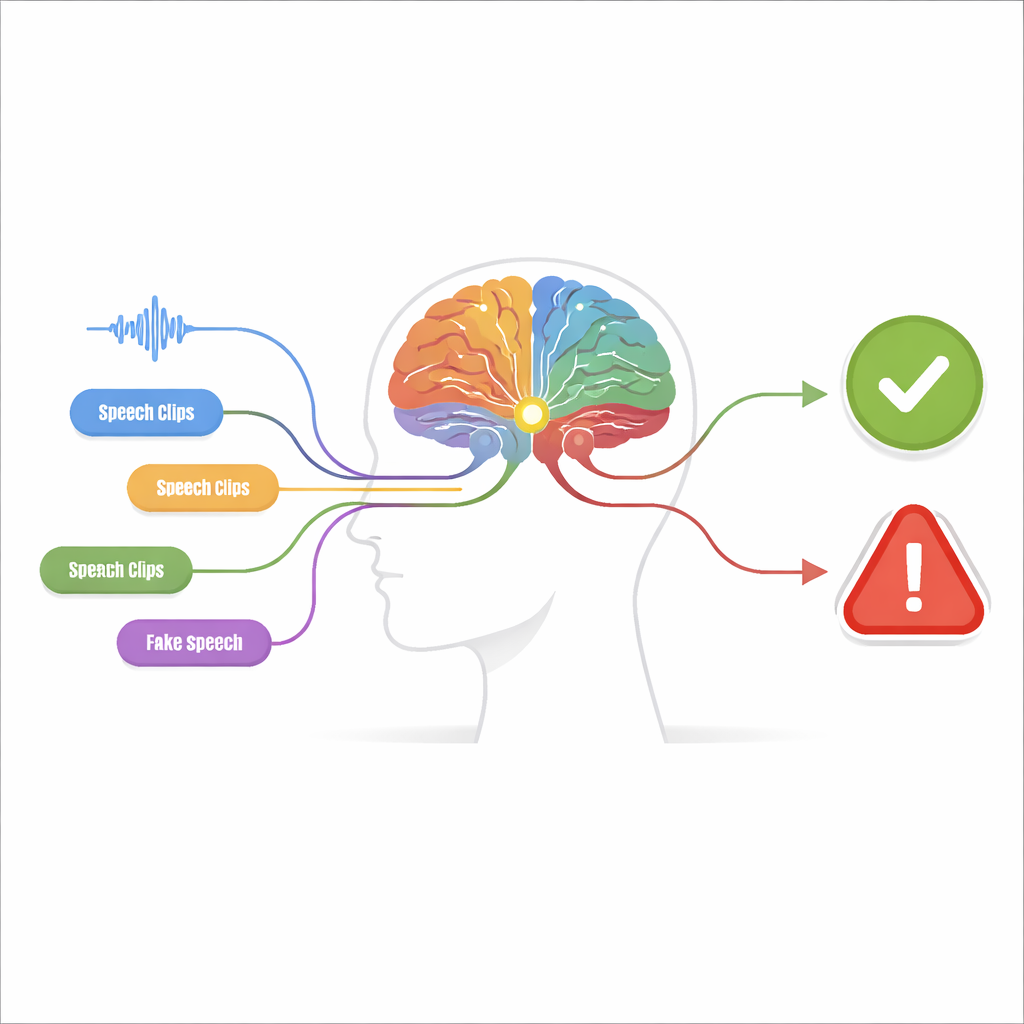
Beaucoup de petits indices plutôt qu’une grosse hypothèse
Le système proposé, appelé machine perception-décision, est construit en deux étapes. Lors de l’étape de perception, l’audio est examiné par plusieurs détecteurs indépendants, chacun ajusté sur un « indice de falsification » spécifique. Certains détecteurs se concentrent sur la forme d’onde brute, recherchant des sauts brusques ou des motifs anormalement lisses. D’autres analysent le contenu fréquentiel, où les voix synthétiques peuvent présenter des harmoniques floues ou des résonances aux formes étranges. Des détecteurs supplémentaires examinent la façon dont le temps et la fréquence évoluent ensemble, repérant des décalages entre le moment où certains sons apparaissent et les tonalités présentes. Un dernier groupe analyse le niveau phonémique — les minuscules unités sonores qui forment les mots — où la parole truquée manque souvent de l’articulation subtile et fluide d’un locuteur réel.
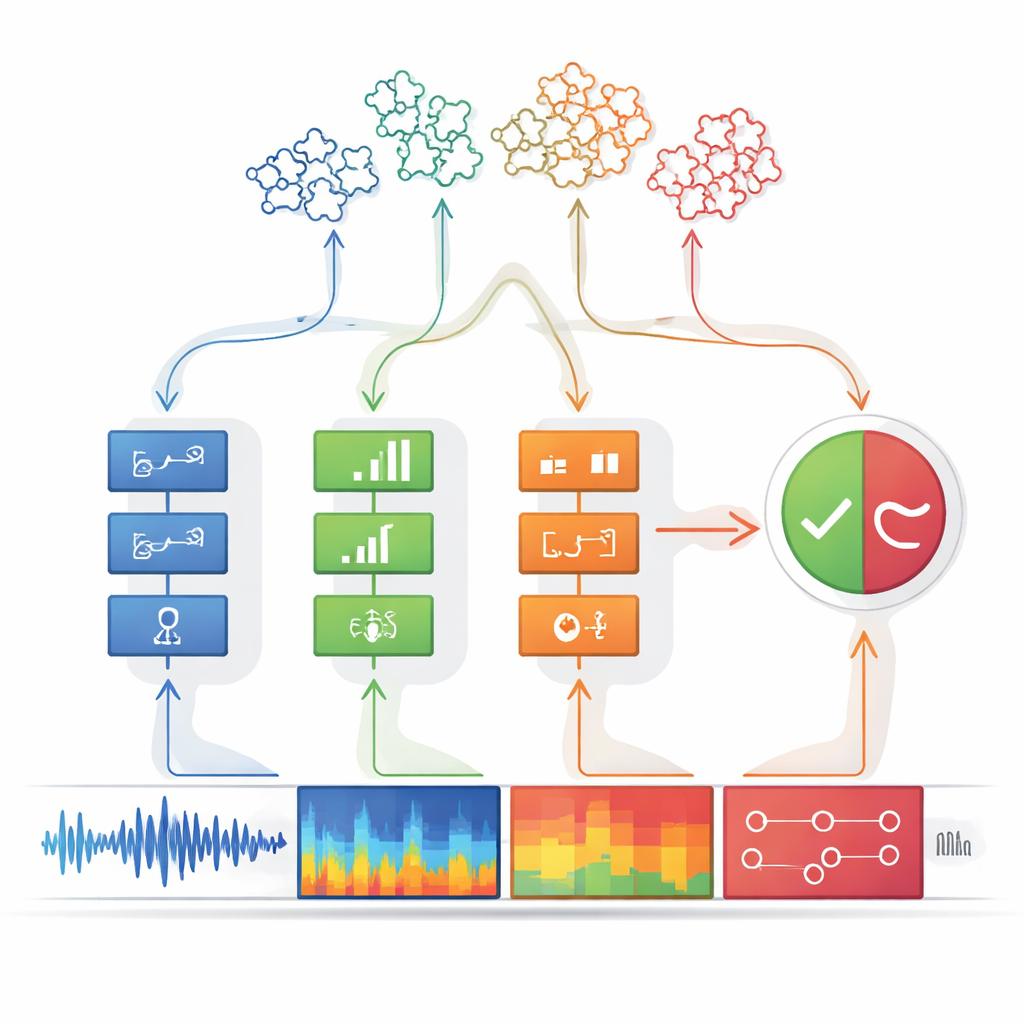
Des motifs d’indices vers une décision claire
Chaque détecteur est conçu pour être extrêmement prudent : il ne signale la présence d’un indice que lorsqu’il en est presque certain, privilégiant la précision plutôt que la couverture exhaustive des faux. Sa sortie est simplifiée en une valeur binaire, comme une lampe allumée ou éteinte. Ces signaux marche–arrêt sont ensuite transmis au module de décision. Là, des groupes d’indices sont combinés à l’aide d’arbres de décision — des chaînes structurées de règles if–then qui ressemblent à la façon dont une personne pourrait raisonner à partir d’éléments de preuve. Une étape logique spéciale, assez proche d’une règle du type « n’importe lequel suffit », relie plusieurs arbres entre eux. Ce raisonnement en couches améliore non seulement la précision, mais rend aussi le système plus transparent : on peut remonter exactement aux indices qui ont conduit à un jugement « truqué ».
Rester en avance sur de nouveaux types de faux
Un atout majeur de ce dispositif est qu’il peut être étendu sans repartir de zéro. Lorsqu’un nouveau type de parole truquée apparaît, les ingénieurs peuvent créer et entraîner un détecteur supplémentaire spécialisé dans ses artefacts particuliers, puis l’ajouter au module de perception. Comme l’étape de décision attend une liste d’entrées d’indices flexible, la sortie du nouveau détecteur peut être intégrée sans réentraîner l’ensemble du système. Dans des tests sur des bancs d’essai de spoofing largement utilisés, la machine perception-décision a égalé ou surpassé de puissants modèles d’apprentissage profond sur les attaques connues et les a clairement dépassés sur des attaques inédites. Elle s’est aussi adaptée à un nouveau jeu de données en chinois simplement en ajoutant des détecteurs, tandis que des systèmes concurrents ont dû être entièrement réentraînés et ont souffert d’un « oubli » des attaques antérieures.
Ce que cela signifie pour la sécurité vocale au quotidien
Pour le grand public, la leçon est que la détection de la parole truquée n’a pas à rester une boîte noire mystérieuse. En décomposant le problème en nombreux petits indices compréhensibles puis en les combinant avec des règles logiques explicites, les auteurs construisent un système à la fois très précis et explicable. Tout comme notre cerveau s’appuie sur de nombreux indices sensoriels avant de former un jugement, cette machine collecte et raisonne sur des signes variés de falsification. Le résultat est une garde plus robuste contre des deepfakes audio en constante évolution — une solution qui peut croître avec le temps et aider à rendre les services et communications vocaux plus sûrs pour tous.
Citation: Feng, C., Wu, X., Askar, H. et al. Brain-inspired perception-decision machine for fake speech detection. Sci Rep 16, 12273 (2026). https://doi.org/10.1038/s41598-026-41859-8
Mots-clés: deepfake audio, détection de parole truquée, IA inspirée du cerveau, sécurité vocale, apprentissage incrémental