Clear Sky Science · zh
用于大规模社交网络影响力最大化问题的深度强化学习框架
为什么在线传播思想很重要
当一段视频、产品或政治信息突然走红时,这并非纯属运气。幕后往往有少数关键人物在在线社交网络中点燃了这股浪潮。企业、公共卫生机构和活动组织者都想知道:应首先向哪些用户传递信息,才能让它覆盖尽可能多的人?这一被称为影响力最大化的难题在当今庞大而复杂的社交平台上变得极其困难。论文提出了一个名为 MaDGNN 的新人工智能框架,它学会快速且可靠地挑选这些“超级传播者”账号,即便在非常大且多样化的网络中也能做到。
选择合适的传播者
影响力最大化提出了一个简单的问题:在可直接联系的人选有限的情况下,应选择哪些人,才能使你的信息最终触及最多的用户?早期研究将其形式化为一个数学优化问题,并提出了通过模拟信息如何在朋友间级联的精细贪心算法。这些方法有强有力的理论保证,但在大规模网络上需要大量模拟,使得它们在实践中既慢又昂贵。近来的工作尝试用深度学习加速处理,但许多模型在从小规模训练图迁移到具有百万级连接的复杂真实平台时难以很好泛化。
用于社会级联的学习引擎
作者提出 MaDGNN,将影响力最大化视为一步步进行的博弈。在每一步,系统观察哪些用户已被选为种子,然后选择下一个要联系的用户,目标是最大化最终的传播规模。为理解网络结构,MaDGNN 使用专为图设计的一类神经网络。这个“级联感知”模块为每个用户创建丰富的数值指纹,既捕捉他们的邻居是谁,也反映影响力如何沿连串连接传播。独立的子模块跟踪某用户在级联中是否活跃、他们影响他人的强度以及他们自身被说服的易性。
用更智能的强化学习稳定决策
在这些学习到的指纹之上,MaDGNN 使用强化学习——一种基于试错的方式,当其种子选择导致广泛传播时会给予奖励。经典强化学习方法可能不稳定:它们可能高估某些动作的价值并陷入糟糕策略。为应对这一点,作者采用了一种称为 Munchausen 强化学习的近期技术,该技术通过温和惩罚过于自信的选择并鼓励合理探索来稳健训练。他们还在决策网络中加入了噪声层,这种噪声直接注入模型内部参数而不是仅依赖随机动作选择。二者结合帮助 MaDGNN 更可靠地收敛到稳健的种子选择策略。
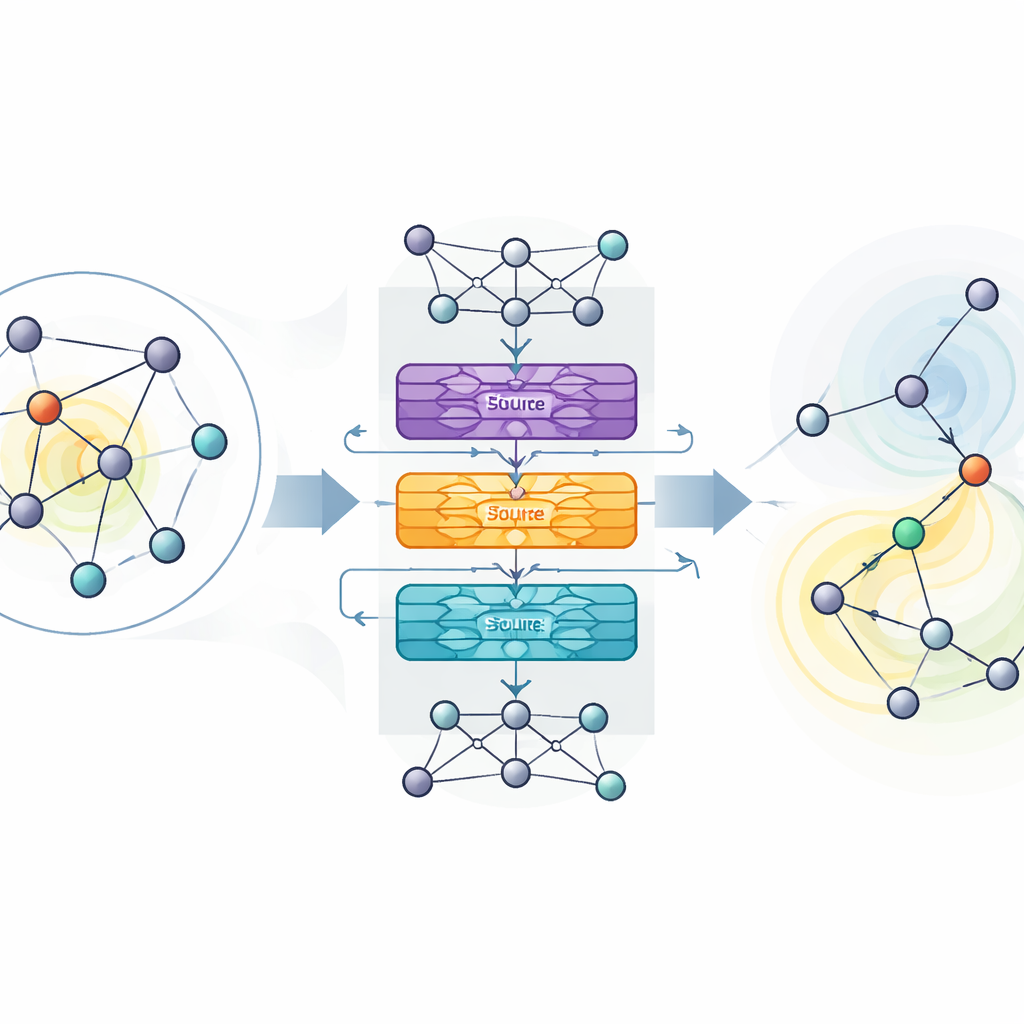
在真实网络上超越现有工具
为了测试 MaDGNN,研究人员先在小型人工图上训练,然后在八个真实的社交与信息网络上进行评估,这些网络包括产品评论网站、电子邮件交流和 Facebook 好友图,规模从数千到数十万用户不等。在大多数数据集以及关于影响力在用户间传播难易程度的多种假设下,MaDGNN 一贯选择出比若干强基线算法(包括流行的基于采样的算法和其他深度强化学习方法)产生更大级联的种子集。它常常在相当或更低的运行时间内取得这些提升,而且其优势在严格的统计检验下仍然成立。
剖析设计并展望未来
团队还解析了 MaDGNN 的设计:将标准学习规则替换为 Munchausen 变体在不显著增加运行时间的情况下提升了传播效果。用成熟的图嵌入技术初始化节点表示带来了进一步的提升,噪声层则通过鼓励更好探索而提高了性能。重要的是,仅通过改变奖励的计算方式,相同的架构即可在不同的信息采纳模型下工作,这表明 MaDGNN 捕捉到的是普遍的结构性线索,而非对单一扩散规则的过拟合。作者也指出仍存在的挑战,例如需调优某些稳定性参数并扩展到拥有数千万边的网络,在这些极端规模下可能需要额外技巧如图划分。
对现实活动的意义
通俗地说,这项工作表明,精心设计的学习系统可以成为病毒式传播的强大战略家。MaDGNN 不再穷举模拟每种可能的情形,而是从经验中学习哪些连接模式倾向于触发大规模级联,并将这些知识应用到新的、更大规模的网络上。对实践者而言,这意味着能更有效地利用有限资源——无论是选择哪些客户获得产品的抢先体验、在健康运动中动员哪些社区成员,还是监控哪些账号以遏制谣言。虽然并非万能,且在最大规模上仍面临可扩展性限制,MaDGNN 仍为把社交网络那种混乱的几何结构转化为可执行的信息传播计划提供了一个有前途的新基准。
引用: Yang, F., Wang, Y., Shu, N. et al. A deep reinforcement learning framework for influence maximization problem on large-scale social networks. Sci Rep 16, 11515 (2026). https://doi.org/10.1038/s41598-026-41731-9
关键词: 影响力最大化, 社交网络, 图神经网络, 强化学习, 信息传播