Clear Sky Science · ru
Глубокая среда обучения с подкреплением для задачи максимизации влияния в масштабных социальных сетях
Почему важно распространять идеи онлайн
Когда видео, продукт или политическое сообщение внезапно становятся вирусными, это не просто случайность. За кулисами несколько ключевых людей в онлайн‑сети часто запускают волну. Компании, органы здравоохранения и активисты хотят знать: каким пользователям следует отправить сообщение в первую очередь, чтобы оно дошло до как можно большего числа других? Эта головоломка, известная как максимизация влияния, становится чрезвычайно сложной на современных огромных, запутанных социальных платформах. В статье представлен новый фреймворк искусственного интеллекта под названием MaDGNN, который учится быстро и надежно выбирать такие «суперраспространяющие» аккаунты даже в очень больших и разнообразных сетях.
Выбор правильных вестников
Задача максимизации влияния формулируется просто: имея ограниченный бюджет людей, с которыми вы можете связаться напрямую, кого из них следует выбрать так, чтобы ваше сообщение в итоге охватило максимальное число пользователей? Ранние исследования формализовали это как задачу математической оптимизации и предложили аккуратные жадные алгоритмы, имитирующие, как информация может распространяться от друга к другу. Эти методы обладают сильными теоретическими гарантиями, но требуют огромного числа симуляций на больших графах, что делает их медленными и затратными на практике. Более поздние работы пытались ускорить процесс с помощью глубокого обучения, однако многие из этих моделей плохо обобщаются при переносе с небольших обучающих графов на сложные реальные платформы с миллионами связей.
Двигатель обучения для каскадов в соцсетях
Авторы предлагают MaDGNN, который рассматривает максимизацию влияния как пошаговую игру. На каждом шаге система учитывает, какие пользователи уже выбраны в качестве «сирен» (seed), и затем выбирает следующего пользователя для контакта, стремясь максимизировать итоговый охват. Чтобы понять структуру сети, MaDGNN использует тип нейронной сети, специально разработанный для графов. Этот «учетный к каскадам» модуль создаёт богатые числовые отпечатки для каждого пользователя, которые захватывают не только информацию о том, кто у них в друзьях, но и то, как влияние, вероятно, будет распространяться по цепочкам связей. Отдельные подсистемы отслеживают, активен ли пользователь в каскаде, насколько сильно он может влиять на других и как легко его самого можно убедить.
Стабилизация решений с помощью более умного обучения с подкреплением
Поверх этих изученных отпечатков MaDGNN использует обучение с подкреплением — метод проб и ошибок, когда систему награждают, если её выборы «сидов» приводят к широкому распространению. Классические методы обучения с подкреплением могут быть нестабильны: они могут переоценивать ценность некоторых действий и уходить в плохие стратегии. Чтобы противостоять этому, авторы адаптируют недавнюю технику, называемую Munchausen reinforcement learning, которая мягко наказывает излишнюю уверенность в выборе и поощряет осмысленное исследование пространства действий. Они также добавляют шумовые слои в решающую сеть, которые вводят случайность непосредственно в внутренние параметры модели, а не полагаются только на случайный выбор действий. Вместе эти компоненты помогают MaDGNN более надёжно сходиться к устойчивым политикам выбора «сидов».
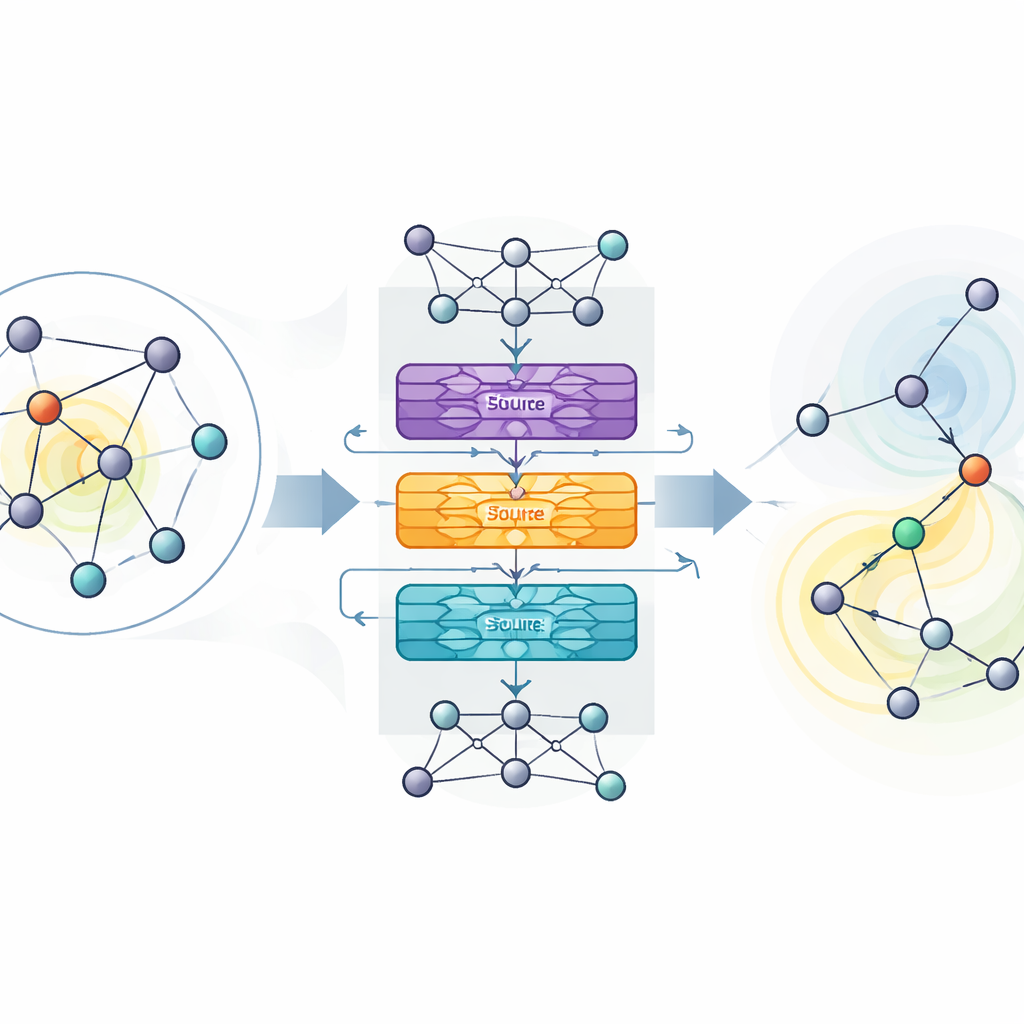
Превосходство над существующими инструментами на реальных сетях
Для проверки MaDGNN исследователи сначала обучали его на небольших искусственных графах, а затем оценивали на восьми реальных социальных и информационных сетях, включая сайты с отзывами о товарах, обмены электронной почтой и графы дружбы Facebook, каждая из которых насчитывала от тысяч до сотен тысяч пользователей. На большинстве наборов данных и при разных предположениях о том, как легко влияние передаётся от одного пользователя к другому, MaDGNN последовательно выбирал множества «сидов», которые порождали более крупные каскады по сравнению с несколькими сильными базовыми методами, включая популярные алгоритмы на основе семплирования и другие методы глубокого обучения с подкреплением. Часто он достигал этих преимуществ при сопоставимом или даже меньшем времени выполнения, и его преимущество подтверждалось тщательными статистическими тестами.
Что внутри и что дальше
Команда также проанализировала конструкцию MaDGNN. Замена стандартного правила обучения вариантом Munchausen улучшила охват влияния без существенного увеличения времени работы. Инициализация представлений узлов с помощью признанной техники графового встраивания дала дополнительные улучшения, а шумовые слои повысили производительность за счёт поощрения лучшего исследования. Важно отметить, что изменив только способ вычисления наград, та же архитектура работала при разных моделях усвоения информации людьми, что указывает на то, что MaDGNN улавливает общие структурные сигналы, а не переобучается под одно правило диффузии. Авторы отмечают оставшиеся проблемы, такие как настройка некоторых параметров стабильности и масштабирование на сети с десятками миллионов рёбер, где могут потребоваться дополнительные приёмы, например разбиение графа.
Что это означает для реальных кампаний
Проще говоря, эта работа показывает, что тщательно спроектированная обучающая система может стать мощным стратегом для вирусного распространения. Вместо того чтобы исчерпывающе моделировать каждый возможный сценарий, MaDGNN учится на опыте, какие шаблоны связей склонны вызывать крупные каскады, а затем применяет это знание к новым, значительно большим сетям. Для практиков это означает более эффективное использование ограниченных ресурсов — будь то выбор клиентов для раннего доступа к продукту, участников сообщества для вовлечения в кампанию по здравоохранению или аккаунтов для мониторинга в целях борьбы с слухами. Хотя это не панацея и система по‑прежнему сталкивается с ограничениями масштабируемости на самых больших масштабах, MaDGNN предлагает многообещающую новую отправную точку для превращения запутанной геометрии социальных сетей в практические планы по распространению информации.
Цитирование: Yang, F., Wang, Y., Shu, N. et al. A deep reinforcement learning framework for influence maximization problem on large-scale social networks. Sci Rep 16, 11515 (2026). https://doi.org/10.1038/s41598-026-41731-9
Ключевые слова: максимизация влияния, социальные сети, графовые нейронные сети, обучение с подкреплением, диффузия информации