Clear Sky Science · pl
Głębokie uczenie ze wzmocnieniem dla problemu maksymalizacji wpływu w sieciach społecznościowych o dużej skali
Dlaczego rozprzestrzenianie pomysłów w sieci ma znaczenie
Gdy wideo, produkt lub przekaz polityczny nagle stają się wiralne, nie jest to tylko kwestia przypadku. Za kulisami kilka kluczowych osób w sieci społecznościowej często zapala iskrę fali. Firmy, agencje zdrowia publicznego i aktywiści chcą wiedzieć: którym użytkownikom warto przekazać wiadomość najpierw, aby dotarła do jak największej liczby osób? To zadanie, znane jako maksymalizacja wpływu, staje się wyjątkowo trudne na dzisiejszych rozległych, splątanych platformach społecznościowych. Artykuł przedstawia nowe ramy sztucznej inteligencji, nazwane MaDGNN, które uczą się, jak szybko i niezawodnie wybierać takich „super‑rozsiewaczy”, nawet w bardzo dużych i zróżnicowanych sieciach.
Wybór odpowiednich posłańców
Maksymalizacja wpływu stawia proste pytanie: mając ograniczony budżet osób, które można skontaktować bezpośrednio, które z nich wybrać, aby ostatecznie przekaz dotarł do jak największej liczby użytkowników? Wcześniejsze badania sformalizowały to jako problem optymalizacyjny i zaproponowały staranne algorytmy zachłanne, które symulują, jak informacja może przetaczać się od znajomego do znajomego. Metody te mają silne gwarancje teoretyczne, lecz wymagają ogromnej liczby symulacji na dużych sieciach, co czyni je powolnymi i kosztownymi w praktyce. Nowsze prace próbowały przyspieszyć proces za pomocą głębokiego uczenia, jednak wiele z tych modeli słabo uogólnia, gdy przeniesie się je ze skromnych grafów treningowych na złożone, rzeczywiste platformy z milionami połączeń.
Silnik uczący się dla kaskad społecznych
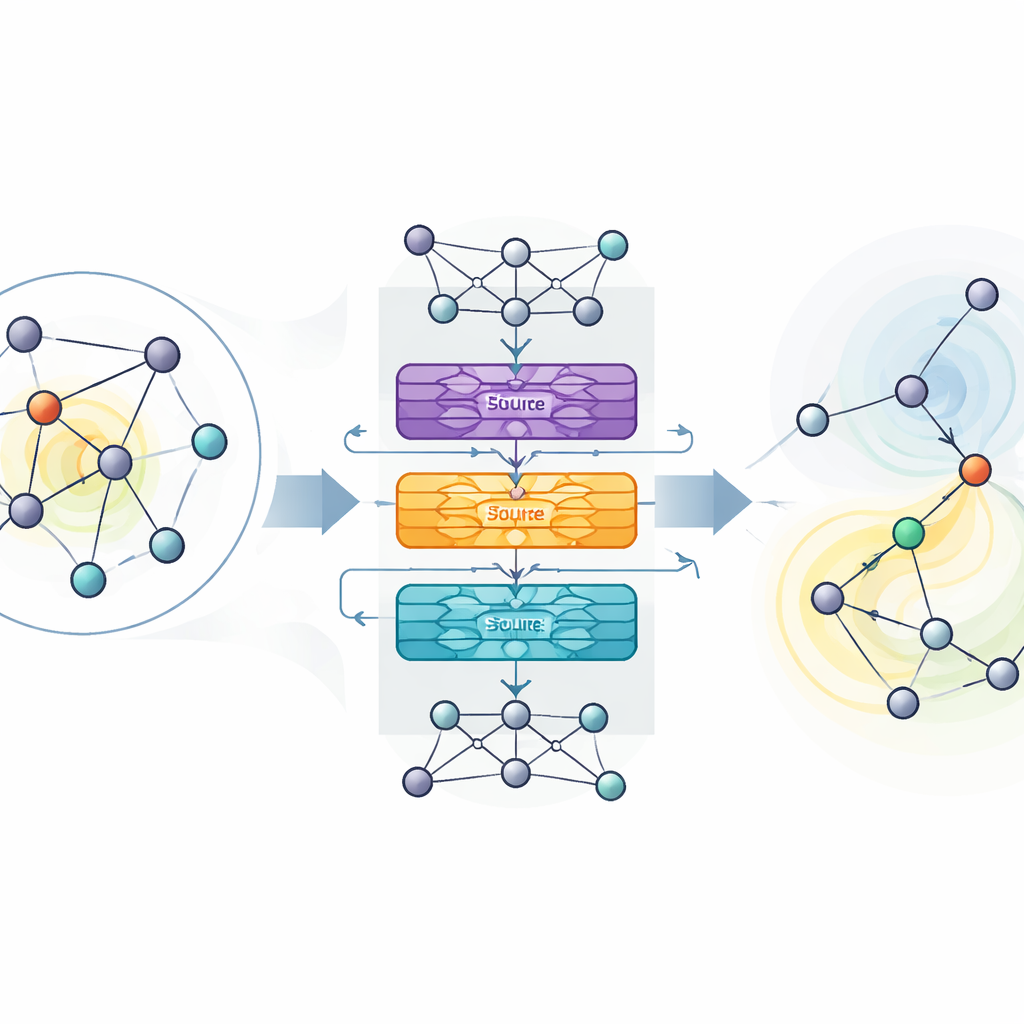
Autorzy proponują MaDGNN, które traktuje maksymalizację wpływu jako grę rozegraną krok po kroku. W każdym kroku system patrzy, którzy użytkownicy już zostali wybrani jako ziarna, a następnie wybiera następnego użytkownika do skontaktowania, dążąc do zmaksymalizowania ostatecznego zasięgu. Aby zrozumieć strukturę sieci, MaDGNN wykorzystuje rodzaj sieci neuronowej zaprojektowanej specjalnie dla grafów. Ten moduł „świadomy kaskady” tworzy bogate numeryczne odciski palców dla każdego użytkownika, które uchwytują nie tylko to, kim są ich znajomi, ale także jak wpływ prawdopodobnie będzie rozchodził się przez łańcuchy połączeń. Oddzielne podmoduły śledzą, czy użytkownik jest aktywny w kaskadzie, jak silnie może wpływać na innych oraz jak łatwo sam może zostać przekonany.
Stabilizowanie decyzji dzięki mądrzejszemu uczeniu ze wzmocnieniem
Na bazie tych wyuczonych odcisków MaDGNN używa uczenia ze wzmocnieniem — podejścia prób i błędów, w którym system jest nagradzany, gdy wybory ziaren prowadzą do szerokiego rozprzestrzenienia. Klasyczne metody uczenia ze wzmocnieniem mogą być niestabilne: mogą przeszacowywać wartość pewnych działań i wplątywać się w słabe strategie. Aby temu przeciwdziałać, autorzy adaptują niedawno zaproponowaną technikę zwaną uczeniem ze wzmocnieniem Munchausena, która łagodnie penalizuje nadmiernie pewne wybory i zachęca do zdrowej eksploracji. Dodają także warstwy z hałasem do sieci decyzyjnej, które wprowadzają losowość bezpośrednio w parametry wewnętrzne modelu zamiast polegać wyłącznie na losowych wyborach działań. Razem te składniki pomagają MaDGNN osiągać bardziej niezawodne zbieżności do solidnych polityk wyboru ziaren.
Lepsze wyniki niż istniejące narzędzia na rzeczywistych sieciach
Aby przetestować MaDGNN, badacze najpierw trenowali je na małych sztucznych grafach, a następnie oceniali na ośmiu rzeczywistych sieciach społecznych i informacyjnych, w tym serwisach z recenzjami produktów, wymianach e‑mail oraz grafach znajomości z Facebooka, każda z tysiącami do setek tysięcy użytkowników. W większości zbiorów danych i przy różnych założeniach dotyczących łatwości rozchodzenia się wpływu od jednego użytkownika do drugiego, MaDGNN konsekwentnie wybierało zbiory ziaren prowadzące do większych kaskad niż kilka silnych punktów odniesienia, w tym popularne algorytmy oparte na próbkowaniu oraz inne metody głębokiego uczenia ze wzmocnieniem. Często osiągało te przewagi przy porównywalnym lub nawet krótszym czasie działania, a jego przewaga utrzymywała się po starannych testach statystycznych.
Prześwietlenie konstrukcji i dalsze perspektywy
Zespół również rozłożył MaDGNN na części. Zastąpienie standardowej reguły uczenia wariantem Munchausena poprawiło zasięg wpływu bez istotnego wydłużenia czasu działania. Inicjalizacja reprezentacji węzłów przy użyciu ugruntowanej techniki osadzania grafu przyniosła dalsze korzyści, a warstwy z hałasem poprawiły wydajność, zachęcając do lepszej eksploracji. Co ważne, zmieniając jedynie sposób obliczania nagród, ta sama architektura działała pod różnymi modelami przyjmowania informacji przez ludzi, co sugeruje, że MaDGNN wyłapuje ogólne wskazówki strukturalne, zamiast nadmiernie dopasowywać się do jednego reguły dyfuzji. Autorzy wskazują na pozostające wyzwania, takie jak strojenie niektórych parametrów stabilności i skalowanie do sieci z dziesiątkami milionów krawędzi, gdzie mogą być potrzebne dodatkowe sztuczki, np. partycjonowanie grafu.
Co to oznacza dla kampanii w świecie rzeczywistym
Mówiąc prosto, ta praca pokazuje, że starannie zaprojektowany system uczący może stać się potężnym strategiem w działaniach wiralowych. Zamiast wyczerpująco symulować każdy możliwy scenariusz, MaDGNN uczy się z doświadczenia, które wzorce połączeń mają tendencję do wywoływania dużych kaskad, a następnie stosuje tę wiedzę w nowych, znacznie większych sieciach. Dla praktyków oznacza to skuteczniejsze wykorzystanie ograniczonych zasobów — czy to wybór klientów otrzymujących wczesny dostęp do produktu, członków społeczności do zaangażowania w kampanię zdrowotną, czy kont do monitorowania w celu kontroli plotek. Choć nie jest to rozwiązanie doskonałe i nadal napotyka ograniczenia skalowalności na największych skalach, MaDGNN oferuje obiecujący nowy punkt odniesienia do przekształcania złożonej geometrii sieci społecznych w wykonalne plany rozpowszechniania informacji.
Cytowanie: Yang, F., Wang, Y., Shu, N. et al. A deep reinforcement learning framework for influence maximization problem on large-scale social networks. Sci Rep 16, 11515 (2026). https://doi.org/10.1038/s41598-026-41731-9
Słowa kluczowe: maksymalizacja wpływu, sieci społecznościowe, grafowe sieci neuronowe, uczenie ze wzmocnieniem, dyfuzja informacji