Clear Sky Science · pt
Uma estrutura de aprendizado por reforço profundo para o problema de maximização de influência em redes sociais de grande escala
Por que espalhar ideias online é importante
Quando um vídeo, produto ou mensagem política de repente se torna viral, não é apenas sorte. Nos bastidores, algumas pessoas-chave em uma rede social online frequentemente desencadeiam a onda. Empresas, agências de saúde pública e ativistas querem saber: quais usuários devem receber uma mensagem primeiro para que ela alcance o maior número possível de outros? Esse problema, conhecido como maximização de influência, torna-se extremamente difícil nas plataformas sociais massivas e intrincadas de hoje. O artigo apresenta uma nova estrutura de inteligência artificial, chamada MaDGNN, que aprende rapidamente e de forma confiável como escolher essas contas “superdifusoras”, mesmo em redes muito grandes e diversas.
Escolhendo os mensageiros certos
A maximização de influência faz uma pergunta simples: dado um orçamento limitado de pessoas que você pode contatar diretamente, quais delas você deve escolher para que sua mensagem, em última instância, atinja o maior número de usuários? Pesquisas anteriores formalizaram isso como um problema de otimização matemática e propuseram algoritmos guloso cuidadosos que simulam como a informação pode se propagar de amigo para amigo. Esses métodos trazem fortes garantias teóricas, mas exigem um número enorme de simulações em redes grandes, tornando-os lentos e custosos na prática. Trabalhos mais recentes tentaram acelerar o processo usando aprendizado profundo, mas muitos desses modelos não conseguem generalizar bem quando são transferidos de grafos de treinamento pequenos para plataformas do mundo real complexas com milhões de conexões.
Um motor de aprendizado para cascatas sociais
Os autores propõem o MaDGNN, que trata a maximização de influência como um jogo jogado passo a passo. A cada passo, o sistema observa quais usuários já foram escolhidos como sementes e então seleciona o próximo usuário a ser contatado, visando maximizar a disseminação final. Para entender a estrutura da rede, o MaDGNN utiliza um tipo de rede neural projetada especificamente para grafos. Esse módulo “ciente de cascata” cria impressões numéricas ricas para cada usuário que capturam não apenas quem são seus amigos, mas também como a influência provavelmente se propagará por cadeias de conexões. Submódulos separados monitoram se um usuário está ativo na cascata, quão fortemente ele pode influenciar outros e com que facilidade ele próprio pode ser persuadido.
Estabilizando decisões com aprendizado por reforço mais inteligente
Sobre essas impressões aprendidas, o MaDGNN usa aprendizado por reforço — uma abordagem de tentativa e erro em que o sistema é recompensado quando suas escolhas de sementes levam a ampla disseminação. Métodos clássicos de aprendizado por reforço podem ser instáveis: podem superestimar o valor de certas ações e desviar-se para estratégias ruins. Para combater isso, os autores adaptam uma técnica recente chamada aprendizado por reforço Munchausen, que penaliza suavemente escolhas excessivamente confiantes e incentiva uma exploração saudável. Eles também adicionam camadas ruidosas à rede de decisão, que injetam aleatoriedade diretamente nos parâmetros internos do modelo em vez de depender apenas de escolhas de ação aleatórias. Juntos, esses ingredientes ajudam o MaDGNN a convergir de forma mais confiável para políticas robustas de seleção de sementes.
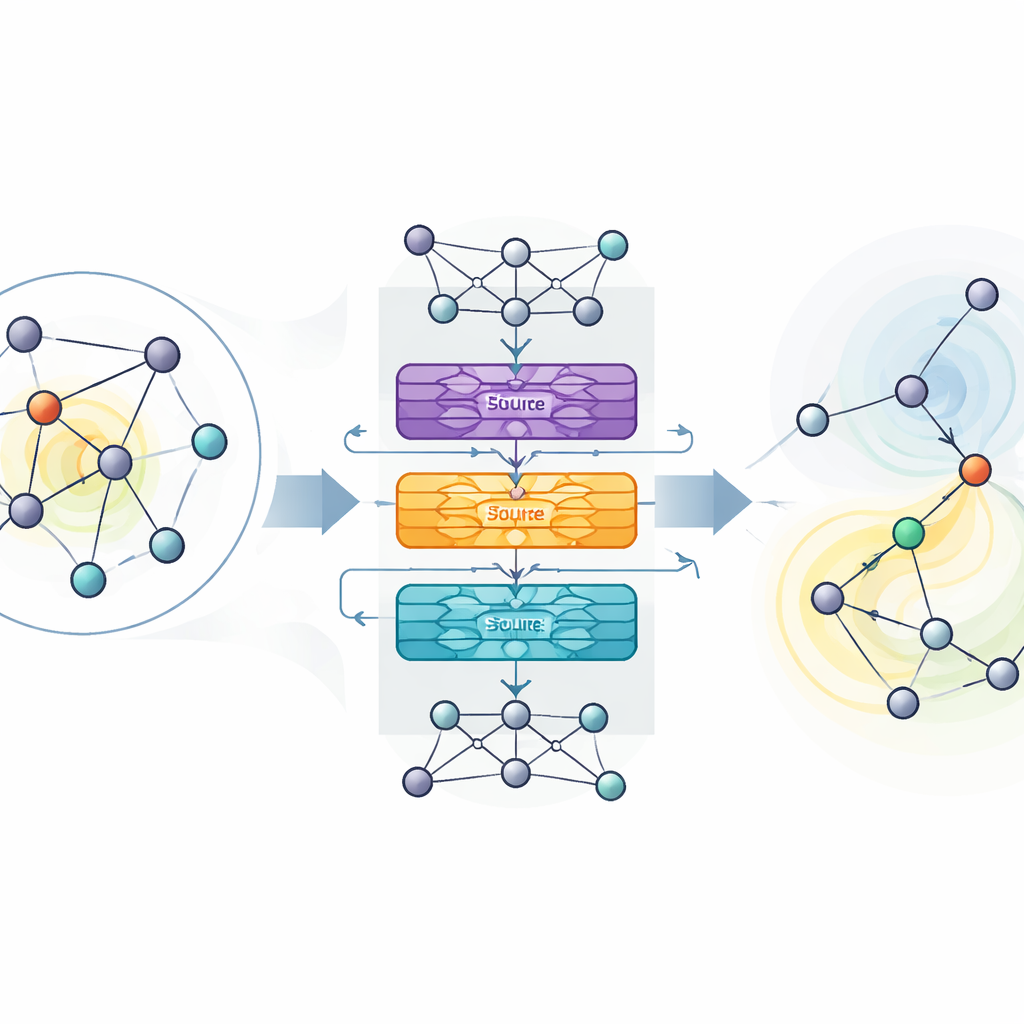
Superando ferramentas existentes em redes reais
Para testar o MaDGNN, os pesquisadores primeiro o treinaram em grafos artificiais pequenos e depois o avaliaram em oito redes sociais e de informação reais, incluindo sites de avaliação de produtos, trocas de e-mail e grafos de amizade do Facebook, cada um com milhares a centenas de milhares de usuários. Na maioria dos conjuntos de dados e sob uma variedade de hipóteses sobre quão facilmente a influência se propaga de um usuário para outro, o MaDGNN selecionou consistentemente conjuntos de sementes que produziram cascatas maiores do que várias linhas de base fortes, incluindo algoritmos populares baseados em amostragem e outros métodos de aprendizado por reforço profundo. Frequentemente alcançou esses ganhos com tempo de execução comparável ou até menor, e sua vantagem se manteve sob testes estatísticos cuidadosos.
Olhando por dentro e além
A equipe também dissecou o projeto do MaDGNN. Substituir a regra de aprendizado padrão pela variante Munchausen melhorou a propagação de influência sem aumentar significativamente o tempo de execução. Inicializar as representações de nós com uma técnica estabelecida de embedding de grafos conduziu a ganhos adicionais, e as camadas ruidosas aumentaram o desempenho ao incentivar uma exploração melhor. Importante, ao mudar apenas a forma como as recompensas são calculadas, a mesma arquitetura funcionou sob diferentes modelos de adoção de informação, sugerindo que o MaDGNN captura pistas estruturais gerais em vez de superajustar a uma única regra de difusão. Os autores apontam desafios remanescentes, como ajustar certos parâmetros de estabilidade e escalar para redes com dezenas de milhões de arestas, onde truques adicionais como particionamento de grafos podem ser necessários.
O que isso significa para campanhas do mundo real
Em termos simples, este trabalho mostra que um sistema de aprendizado cuidadosamente projetado pode se tornar um estrategista poderoso para divulgação viral. Em vez de simular exaustivamente todos os cenários possíveis, o MaDGNN aprende pela experiência quais padrões de conexão tendem a desencadear grandes cascatas e então aplica esse conhecimento a redes novas e muito maiores. Para profissionais, isso significa uso mais eficaz de recursos limitados — seja na escolha de quais clientes receberão acesso antecipado a um produto, quais membros de uma comunidade envolver em uma campanha de saúde ou quais contas monitorar para controle de boatos. Embora não seja uma solução mágica e ainda enfrente limites de escalabilidade nas maiores escalas, o MaDGNN oferece uma nova linha de base promissora para transformar a geometria desordenada das redes sociais em planos acionáveis para disseminação de informação.
Citação: Yang, F., Wang, Y., Shu, N. et al. A deep reinforcement learning framework for influence maximization problem on large-scale social networks. Sci Rep 16, 11515 (2026). https://doi.org/10.1038/s41598-026-41731-9
Palavras-chave: maximização de influência, redes sociais, redes neurais em grafos, aprendizado por reforço, difusão de informação