Clear Sky Science · nl
Een deep reinforcement learning-kader voor het probleem van influence maximization op grootschalige sociale netwerken
Waarom het verspreiden van ideeën online ertoe doet
Wanneer een video, product of politieke boodschap plotseling viraal gaat, is dat niet louter geluk. Achter de schermen ontbranden vaak een paar sleutelpersonen in een online sociaal netwerk de golf. Bedrijven, gezondheidsinstanties en activisten willen allemaal weten: welke gebruikers moeten een boodschap als eerste ontvangen zodat die zoveel mogelijk anderen bereikt? Dit vraagstuk, bekend als influence maximization, wordt buitengewoon moeilijk op de omvangrijke, verwarde sociale platformen van vandaag. In het artikel wordt een nieuw kunstmatig-intelligentiekader geïntroduceerd, MaDGNN genaamd, dat leert hoe het deze “superspreiders”-accounts snel en betrouwbaar kan kiezen, zelfs in zeer grote en heterogene netwerken.
De juiste boodschappers kiezen
Influence maximization stelt een eenvoudige vraag: gegeven een beperkt budget aan mensen die u rechtstreeks kunt benaderen, wie daarvan moet u kiezen zodat uw boodschap uiteindelijk het grootste aantal gebruikers bereikt? Eerder onderzoek formaliseerde dit als een wiskundig optimaliseringsprobleem en stelde zorgvuldige greedy-algoritmen voor die simuleren hoe informatie van vriend naar vriend zou kunnen overslaan. Deze methoden hebben sterke theoretische garanties, maar ze vergen enorme aantallen simulaties op grote netwerken, wat ze in de praktijk traag en kostbaar maakt. Recente werken probeerden het proces te versnellen met deep learning, maar veel van die modellen generaliseren slecht wanneer ze van kleine trainingsgrafen naar complexe, real-world platformen met miljoenen verbindingen worden verplaatst.
Een leerengine voor sociale cascades
De auteurs stellen MaDGNN voor, dat influence maximization behandelt als een stap-voor-stap spel. In elke stap kijkt het systeem welke gebruikers al als seeds zijn gekozen en selecteert vervolgens de volgende gebruiker om te benaderen, met als doel de uiteindelijke verspreiding te maximaliseren. Om de structuur van het netwerk te begrijpen, gebruikt MaDGNN een type neuraal netwerk dat specifiek voor grafen is ontworpen. Deze “cascade-bewuste” module creëert rijke numerieke vingerafdrukken voor elke gebruiker die niet alleen vastleggen wie hun vrienden zijn, maar ook hoe invloed waarschijnlijk door ketens van verbindingen zal doorwerken. Verschillende submodules volgen of een gebruiker actief is in de cascade, hoe sterk zij anderen kunnen beïnvloeden en hoe ontvankelijk zij zelf zijn voor beïnvloeding.
Besluiten stabiliseren met slimmer reinforcement learning
Bovenop deze geleerde vingerafdrukken gebruikt MaDGNN reinforcement learning—een proef-en-foutbenadering waarbij het systeem beloond wordt wanneer zijn seed-keuzes leiden tot brede verspreiding. Klassieke reinforcement-learningmethoden kunnen instabiel zijn: ze kunnen de waarde van bepaalde acties overschatten en in slechte strategieën vervallen. Om dit tegen te gaan passen de auteurs een recente techniek aan, Munchausen reinforcement learning, die overmatig zelfverzekerde keuzes licht straft en gezonde exploratie aanmoedigt. Ze voegen ook noisy layers toe aan het beslissingsnetwerk, die willekeur direct in de interne parameters van het model injecteren in plaats van alleen op willekeurige actiekeuzes te vertrouwen. Samen helpen deze ingrediënten MaDGNN om betrouwbaarder te convergeren naar robuuste seed-selectiebeleid.
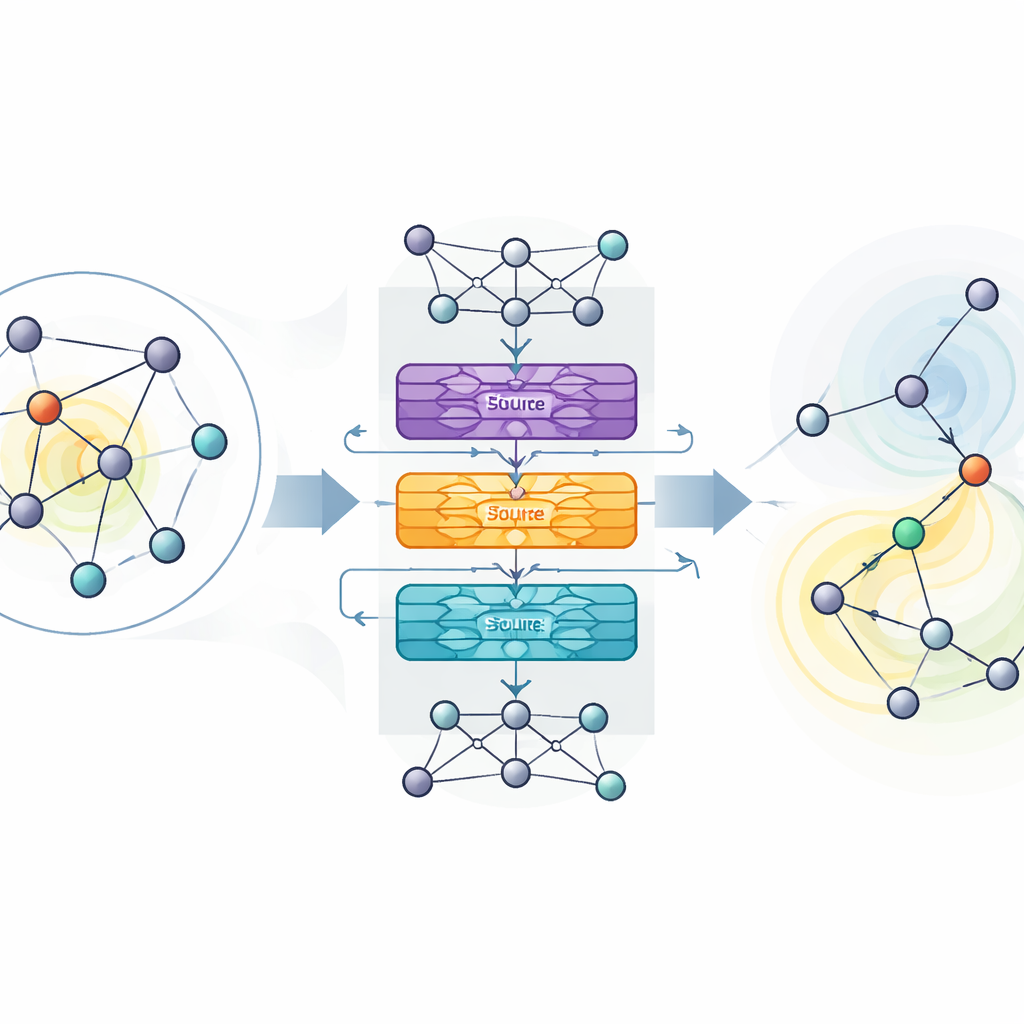
Beter presteren dan bestaande tools op echte netwerken
Om MaDGNN te testen, trainden de onderzoekers het eerst op kleine kunstmatige grafen en evalueerden het vervolgens op acht echte sociale en informatie-netwerken, waaronder productbeoordelingssites, e-mailuitwisselingen en Facebook-vriendschapsgrafen, elk met duizenden tot honderduizenden gebruikers. Over de meeste datasets en onder uiteenlopende aannames over hoe gemakkelijk invloed van de ene gebruiker naar de andere reist, koos MaDGNN consequent seed-sets die grotere cascades produceerden dan verschillende sterke baselines, waaronder populaire sampling-gebaseerde algoritmen en andere deep reinforcement learning-methoden. Het behaalde deze verbeteringen vaak met vergelijkbare of zelfs lagere runtimes, en het voordeel hield stand bij zorgvuldige statistische tests.
Onder de motorkap kijken en verder
Het team ontleedde ook het ontwerp van MaDGNN. Het vervangen van de standaardleerregel door de Munchausen-variant verbeterde de verspreiding van invloed zonder de runtime wezenlijk te verhogen. Het initialiseren van knooprepresentaties met een gevestigde graph-embeddingtechniek leidde tot verdere winst, en de noisy layers verhoogden de prestatie door betere exploratie te stimuleren. Belangrijk is dat, door alleen te veranderen hoe beloningen worden berekend, dezelfde architectuur onder verschillende modellen van informatieadoptie werkte, wat suggereert dat MaDGNN algemene structurele aanwijzingen opvangt in plaats van te overfiten op één diffusiewet. De auteurs wijzen op resterende uitdagingen, zoals het afstemmen van bepaalde stabiliteitsparameters en het opschalen naar netwerken met tientallen miljoenen randen, waar extra trucs zoals grafpartitionering nodig kunnen zijn.
Wat dit betekent voor campagnes in de praktijk
In eenvoudige bewoordingen laat dit werk zien dat een zorgvuldig ontworpen leersysteem een krachtige strateeg kan worden voor virale outreach. In plaats van elke mogelijke scenario uitgebreid te simuleren, leert MaDGNN uit ervaring welke verbindingspatronen de neiging hebben grote cascades te ontketenen en past die kennis vervolgens toe op nieuwe, veel grotere netwerken. Voor praktijkmensen betekent dit effectiever gebruik van beperkte middelen—of het nu gaat om het kiezen welke klanten vroegtijdige toegang tot een product krijgen, welke gemeenschapsleden bij een gezondheidscampagne betrokken moeten worden, of welke accounts gemonitord moeten worden voor geruchtenbestrijding. Hoewel geen wondermiddel en nog steeds beperkt in schaalbaarheid op de aller grootste schalen, biedt MaDGNN een veelbelovende nieuwe referentie voor het omzetten van de rommelige geometrie van sociale netwerken in uitvoerbare plannen voor informatieverspreiding.
Bronvermelding: Yang, F., Wang, Y., Shu, N. et al. A deep reinforcement learning framework for influence maximization problem on large-scale social networks. Sci Rep 16, 11515 (2026). https://doi.org/10.1038/s41598-026-41731-9
Trefwoorden: influence maximization, sociale netwerken, graph neural networks, reinforcement learning, informatieverspreiding