Clear Sky Science · es
Un marco de aprendizaje por refuerzo profundo para el problema de maximización de influencia en redes sociales a gran escala
Por qué importa difundir ideas en línea
Cuando un vídeo, un producto o un mensaje político se vuelve viral de repente, no es solo cuestión de suerte. Detrás, unas pocas personas clave en una red social en línea suelen encender la ola. Empresas, agencias de salud pública y activistas quieren saber: ¿a qué usuarios hay que enviarles el mensaje primero para que llegue al mayor número posible de personas? Este rompecabezas, conocido como maximización de influencia, se vuelve extremadamente difícil en las plataformas sociales masivas y enmarañadas de hoy. El artículo presenta un nuevo marco de inteligencia artificial, llamado MaDGNN, que aprende a elegir estas cuentas “súper‑difusoras” con rapidez y fiabilidad, incluso en redes muy grandes y heterogéneas.
Elegir a los mensajeros adecuados
La maximización de influencia plantea una pregunta simple: dado un presupuesto limitado de personas a las que se puede contactar directamente, ¿a cuáles conviene escoger para que el mensaje finalmente alcance al mayor número de usuarios? Investigaciones anteriores formalizaron esto como un problema de optimización matemática y propusieron algoritmos voraces cuidadosos que simulan cómo la información podría propagarse de amigo a amigo. Estos métodos ofrecen fuertes garantías teóricas, pero requieren un número enorme de simulaciones en redes grandes, lo que los hace lentos y costosos en la práctica. Trabajos más recientes intentaron acelerar el proceso usando aprendizaje profundo, pero muchos de esos modelos no generalizan bien al pasar de grafos de entrenamiento pequeños a plataformas complejas del mundo real con millones de conexiones.
Un motor de aprendizaje para cascadas sociales
Los autores proponen MaDGNN, que trata la maximización de influencia como un juego jugado paso a paso. En cada paso, el sistema observa qué usuarios ya han sido elegidos como semillas y luego selecciona al siguiente usuario a contactar, con el objetivo de maximizar la difusión eventual. Para entender la estructura de la red, MaDGNN utiliza un tipo de red neuronal diseñada específicamente para grafos. Este módulo “consciente de la cascada” crea ricas huellas numéricas para cada usuario que capturan no solo quiénes son sus amigos, sino también cómo es probable que la influencia se propague a través de cadenas de conexiones. Submódulos separados rastrean si un usuario está activo en la cascada, cuán fuertemente puede influir en otros y con qué facilidad él o ella podría ser persuadido.
Estabilizar las decisiones con un aprendizaje por refuerzo más inteligente
Sobre estas huellas aprendidas, MaDGNN usa aprendizaje por refuerzo —un enfoque de ensayo y error donde el sistema recibe recompensa cuando sus elecciones de semillas conducen a una amplia difusión. Los métodos clásicos de aprendizaje por refuerzo pueden ser inestables: pueden sobreestimar el valor de ciertas acciones y derivar hacia estrategias pobres. Para contrarrestarlo, los autores adaptan una técnica reciente llamada aprendizaje por refuerzo Munchausen, que penaliza suavemente las elecciones demasiado confiadas y fomenta una exploración saludable. También añaden capas ruidosas a la red de decisión, que inyectan aleatoriedad directamente en los parámetros internos del modelo en lugar de depender solo de elecciones de acción aleatorias. En conjunto, estos ingredientes ayudan a MaDGNN a converger de forma más fiable hacia políticas robustas de selección de semillas.
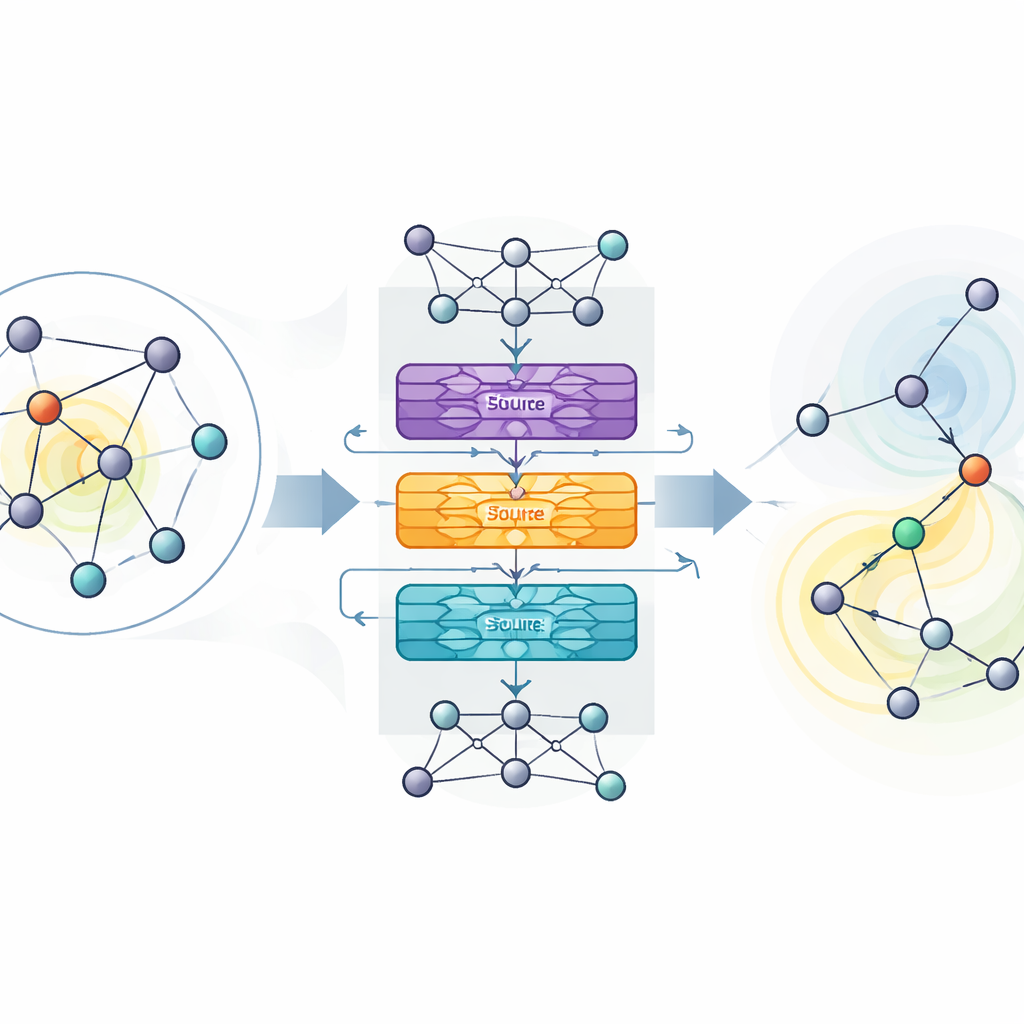
Superando a herramientas existentes en redes reales
Para evaluar MaDGNN, los investigadores primero lo entrenaron en grafos artificiales pequeños y luego lo probaron en ocho redes sociales e informativas reales, incluidos sitios de reseñas de productos, intercambios de correo electrónico y grafos de amistad de Facebook, cada uno con miles hasta cientos de miles de usuarios. En la mayoría de los conjuntos de datos y bajo una variedad de supuestos sobre la facilidad con que la influencia viaja de un usuario a otro, MaDGNN seleccionó de forma consistente conjuntos de semillas que produjeron cascadas mayores que varias referencias sólidas, incluidos algoritmos populares basados en muestreo y otros métodos de aprendizaje por refuerzo profundo. A menudo consiguió estas mejoras con tiempos de ejecución comparables o incluso menores, y su ventaja se mantuvo tras pruebas estadísticas cuidadosas.
Analizando su diseño y más allá
El equipo también diseccionó el diseño de MaDGNN. Reemplazar la regla de aprendizaje estándar por la variante Munchausen mejoró la difusión de influencia sin aumentar significativamente el tiempo de ejecución. Inicializar las representaciones de los nodos con una técnica de incrustación de grafos consolidada condujo a mayores ganancias, y las capas ruidosas mejoraron el rendimiento al favorecer una mejor exploración. Es importante que, cambiando solo la forma en que se calculan las recompensas, la misma arquitectura funcionó bajo diferentes modelos de adopción de información, lo que sugiere que MaDGNN captura señales estructurales generales en lugar de sobreajustarse a una única regla de difusión. Los autores señalan desafíos pendientes, como ajustar ciertos parámetros de estabilidad y escalar a redes con decenas de millones de aristas, donde podrían hacerse necesarios trucos adicionales como el particionado de grafos.
Qué significa esto para campañas del mundo real
En términos sencillos, este trabajo muestra que un sistema de aprendizaje bien diseñado puede convertirse en un estratega poderoso para la difusión viral. En lugar de simular exhaustivamente cada escenario posible, MaDGNN aprende por experiencia qué patrones de conexiones tienden a desencadenar grandes cascadas y aplica ese conocimiento a redes nuevas y mucho más grandes. Para los profesionales, esto se traduce en un uso más eficaz de recursos limitados—ya sea al elegir qué clientes recibir acceso anticipado a un producto, qué miembros de una comunidad involucrar en una campaña de salud o qué cuentas vigilar para el control de rumores. Aunque no es una panacea y aún enfrenta límites de escalabilidad en las mayores escalas, MaDGNN ofrece una nueva referencia prometedora para convertir la geometría desordenada de las redes sociales en planes accionables para difundir información.
Cita: Yang, F., Wang, Y., Shu, N. et al. A deep reinforcement learning framework for influence maximization problem on large-scale social networks. Sci Rep 16, 11515 (2026). https://doi.org/10.1038/s41598-026-41731-9
Palabras clave: maximización de influencia, redes sociales, redes neuronales de grafos, aprendizaje por refuerzo, difusión de información