Clear Sky Science · en
A deep reinforcement learning framework for influence maximization problem on large-scale social networks
Why spreading ideas online matters
When a video, product, or political message suddenly goes viral, it is not just luck. Behind the scenes, a few key people in an online social network often ignite the wave. Companies, public‑health agencies, and activists all want to know: which users should receive a message first so that it reaches as many others as possible? This puzzle, known as influence maximization, becomes extremely hard on today’s massive, tangled social platforms. The paper introduces a new artificial intelligence framework, called MaDGNN, that learns how to pick these “super‑spreader” accounts quickly and reliably, even in very large and diverse networks.
Picking the right messengers
Influence maximization asks a simple question: given a limited budget of people you can contact directly, which of them should you choose so that your message ultimately touches the largest number of users? Earlier research formalized this as a mathematical optimization problem and proposed careful greedy algorithms that simulate how information might cascade from friend to friend. These methods come with strong theoretical guarantees, but they require enormous numbers of simulations on large networks, making them slow and costly in practice. More recent work tried to speed things up using deep learning, yet many of those models fail to generalize well when moved from small training graphs to complex, real‑world platforms with millions of connections.
A learning engine for social cascades
The authors propose MaDGNN, which treats influence maximization as a game played step by step. At each step, the system looks at which users are already chosen as seeds and then selects the next user to contact, aiming to maximize the eventual spread. To understand the structure of the network, MaDGNN uses a type of neural network designed specifically for graphs. This “cascade‑aware” module creates rich numerical fingerprints for each user that capture not only who their friends are, but also how influence is likely to ripple through chains of connections. Separate submodules track whether a user is active in the cascade, how strongly they can influence others, and how easily they themselves might be persuaded.
Stabilizing decisions with smarter reinforcement learning
On top of these learned fingerprints, MaDGNN uses reinforcement learning—a trial‑and‑error approach where the system is rewarded when its seed choices lead to wide spread. Classic reinforcement learning methods can be unstable: they may overestimate the value of certain actions and wander into poor strategies. To counter this, the authors adapt a recent technique called Munchausen reinforcement learning, which gently penalizes over‑confident choices and encourages healthy exploration. They also add noisy layers to the decision network, which inject randomness directly into the model’s internal parameters rather than relying only on random action choices. Together, these ingredients help MaDGNN converge more reliably on robust seed‑selection policies.
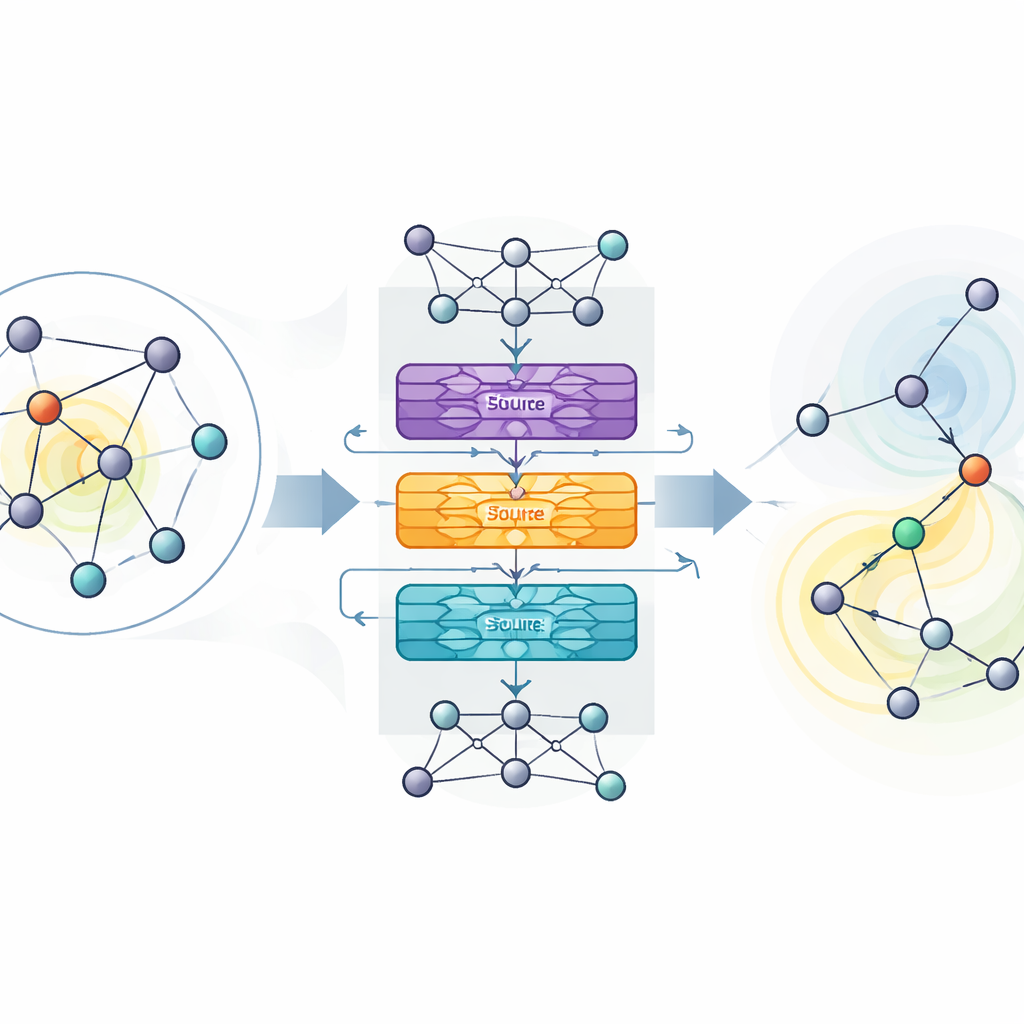
Outperforming existing tools on real networks
To test MaDGNN, the researchers first trained it on small artificial graphs and then evaluated it on eight real social and information networks, including product‑review sites, email exchanges, and Facebook friendship graphs, each with thousands to hundreds of thousands of users. Across most datasets and under a range of assumptions about how easily influence travels from one user to another, MaDGNN consistently selected seed sets that produced larger cascades than several strong baselines, including popular sampling‑based algorithms and other deep reinforcement learning methods. It often achieved these gains with comparable or even lower running time, and its advantage held up under careful statistical testing.
Looking under the hood and beyond
The team also dissected MaDGNN’s design. Replacing the standard learning rule with the Munchausen variant improved influence spread without meaningfully increasing runtime. Initializing node representations with an established graph embedding technique led to further gains, and the noisy layers boosted performance by encouraging better exploration. Importantly, by changing only how rewards are computed, the same architecture worked under different models of how people adopt information, suggesting that MaDGNN captures general structural cues rather than overfitting to one diffusion rule. The authors note remaining challenges, such as tuning certain stability parameters and scaling to networks with tens of millions of edges, where additional tricks like graph partitioning may be needed.
What this means for real‑world campaigns
In plain terms, this work shows that a carefully designed learning system can become a powerful strategist for viral outreach. Instead of exhaustively simulating every possible scenario, MaDGNN learns from experience which patterns of connections tend to spark large cascades and then applies that knowledge to new, much larger networks. For practitioners, this means more effective use of limited resources—whether choosing which customers receive early access to a product, which community members to involve in a health campaign, or which accounts to monitor for rumor control. While not a silver bullet and still facing scalability limits at the very largest scales, MaDGNN offers a promising new baseline for turning the messy geometry of social networks into actionable plans for spreading information.
Citation: Yang, F., Wang, Y., Shu, N. et al. A deep reinforcement learning framework for influence maximization problem on large-scale social networks. Sci Rep 16, 11515 (2026). https://doi.org/10.1038/s41598-026-41731-9
Keywords: influence maximization, social networks, graph neural networks, reinforcement learning, information diffusion