Clear Sky Science · ja
大規模ソーシャルネットワークにおける影響力最大化問題のための深層強化学習フレームワーク
オンラインでアイデアが広がることが重要な理由
動画や製品、政治的メッセージが突然バイラルになるのは単なる運ではありません。舞台裏では、オンラインのソーシャルネットワーク内の少数の重要な人物が波を引き起こすことが多いのです。企業や公衆衛生機関、活動家はいずれも問います:どのユーザーに最初にメッセージを届ければ、できるだけ多くの人に届くのか?このパズルは影響力最大化として知られ、今日の巨大で入り組んだソーシャルプラットフォームでは非常に難しくなります。論文はMaDGNNと呼ばれる新しい人工知能フレームワークを紹介します。これにより、非常に大規模で多様なネットワークにおいても、迅速かつ確実に「スーパースプレッダー」アカウントを選ぶ方法を学習できます。
適切な伝達者を選ぶ
影響力最大化は単純な問いを投げかけます:直接接触できる人数に限りがあるとき、最終的に最も多くのユーザーに届くように、誰を選ぶべきか?以前の研究はこれを数学的最適化問題として定式化し、情報が友人から友人へと連鎖する様子をシミュレートする注意深い貪欲アルゴリズムを提案しました。これらの手法は強力な理論的保証を伴いますが、大規模ネットワークでは膨大な数のシミュレーションを必要とし、実用上は遅く高コストになります。より最近の研究は深層学習で速度向上を図りましたが、小規模な学習グラフから数百万の接続を持つ複雑な実世界プラットフォームに移すと多くのモデルがうまく一般化できないことがありました。
ソーシャルカスケードのための学習エンジン
著者らはMaDGNNを提案します。これは影響力最大化をステップごとに行うゲームとみなします。各ステップでシステムは既に選ばれたシードユーザーを確認し、その後次に接触するユーザーを選び、最終的な広がりを最大化することを目指します。ネットワークの構造を理解するために、MaDGNNはグラフ専用に設計されたタイプのニューラルネットワークを使用します。この「カスケード認識」モジュールは、各ユーザーについて、誰が友人であるかだけでなく影響がどのように連鎖するかを含めた豊かな数値的指紋を生成します。別個のサブモジュールは、ユーザーがカスケード内で既にアクティブかどうか、他者に影響を与える強さ、そして本人がどれだけ説得されやすいかを追跡します。
より賢い強化学習で意思決定を安定化
これらの学習された指紋に加え、MaDGNNは強化学習を用います—システムがシード選択によって広範な拡散をもたらしたときに報酬を受け取る試行錯誤のアプローチです。古典的な強化学習手法は不安定になりがちで、特定の行動の価値を過大評価して望ましくない戦略に陥ることがあります。これに対抗するため、著者らはMunchausen強化学習と呼ばれる最近の手法を適用し、過度に自信的な選択をやんわりと罰しつつ健全な探索を促します。また、決定ネットワークにノイズを含む層を追加し、単に行動のランダム化に頼るのではなくモデルの内部パラメータに直接ランダム性を注入します。これらを組み合わせることで、MaDGNNはより信頼性高く堅牢なシード選択ポリシーに収束しやすくなります。
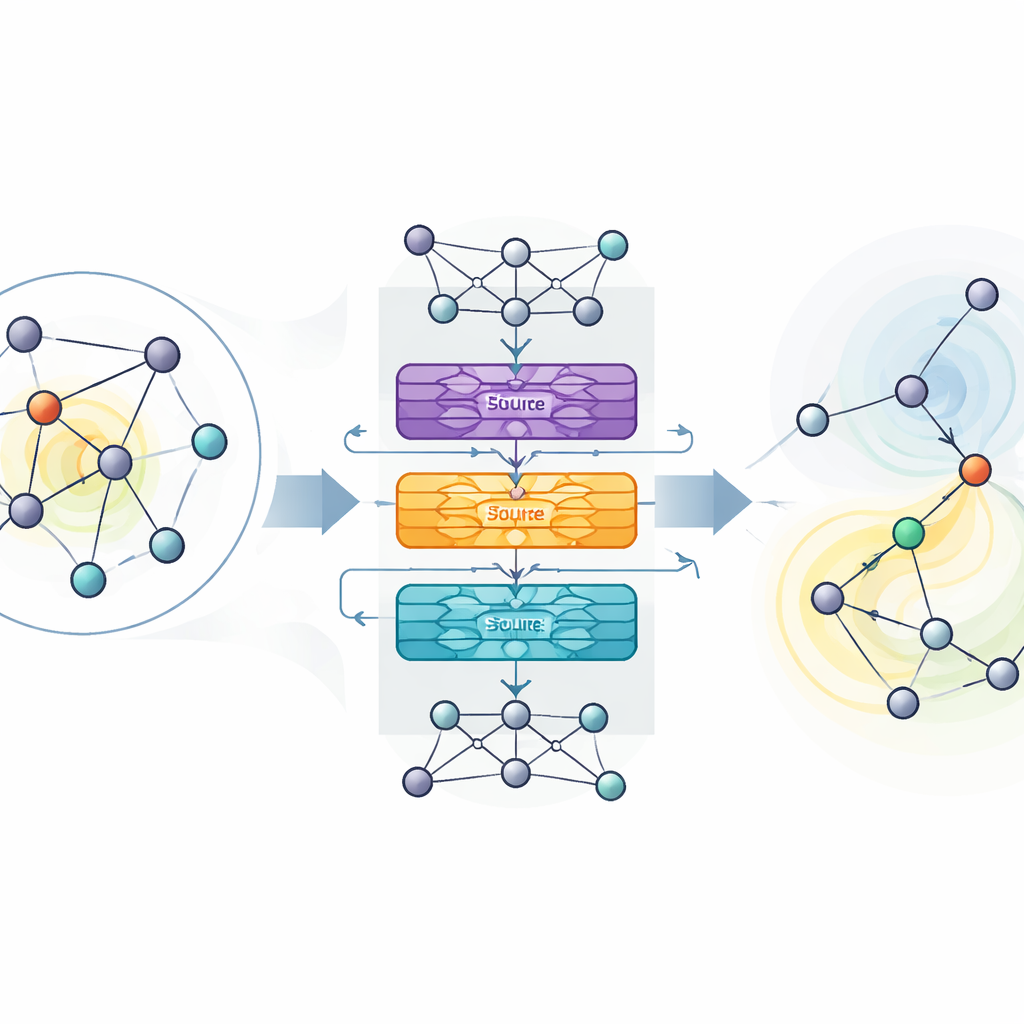
実ネットワークで既存手法を上回る
MaDGNNを評価するため、研究者らはまず小規模な人工グラフで訓練し、次に製品レビューサイト、電子メールのやり取り、Facebookの友人グラフなど、数千から数十万ユーザーを持つ8つの実際のソーシャル/情報ネットワークで評価しました。ほとんどのデータセットと、ユーザー間の影響がどれほど伝播しやすいかに関する様々な仮定のもとで、MaDGNNは一般的なサンプリングベースのアルゴリズムや他の深層強化学習手法などいくつかの強力なベースラインを上回るシード集合を一貫して選び、より大きなカスケードを生み出しました。しばしば、同等かそれ以下の実行時間でこれらの利得を達成し、その優位性は慎重な統計検定でも維持されました。
内部の解析と今後の展開
チームはMaDGNNの設計を詳細に解析しました。標準的な学習則をMunchausen変種に置き換えると、実行時間をほとんど増やさずに影響拡大が改善されました。既存のグラフ埋め込み手法でノード表現を初期化するとさらなる改善が得られ、ノイズ層はより良い探索を促して性能を押し上げました。重要なのは、報酬の計算方法だけを変えることで、同じアーキテクチャが人々が情報を採用する異なるモデルの下でも機能した点であり、MaDGNNが一つの拡散規則に過剰適合するのではなく一般的な構造的手がかりを捉えていることを示唆します。残る課題として、特定の安定性パラメータの調整や、数千万エッジ規模のネットワークへのスケーリングが挙げられ、グラフ分割のような追加的な工夫が必要になる場合があると著者らは指摘しています。
現実のキャンペーンにとっての意味
簡潔に言えば、本研究は慎重に設計された学習システムがバイラルな広報の強力な戦略家になり得ることを示しています。あらゆるシナリオを総当たりでシミュレートする代わりに、MaDGNNは経験からどのような接続パターンが大きなカスケードを起こしやすいかを学び、それを新しいより大規模なネットワークに応用します。実務者にとっては、限られた資源をより効果的に使うことが可能になります—例えば製品の早期アクセスを提供すべき顧客の選定、保健キャンペーンに関わらせるコミュニティメンバーの選定、あるいは流言対策で監視すべきアカウントの特定などです。万能薬ではなく、非常に大規模なスケールでは依然として限界がありますが、MaDGNNはソーシャルネットワークの複雑な構造を情報拡散の実行可能な計画に変えるための有望な新たな基準を提供します。
引用: Yang, F., Wang, Y., Shu, N. et al. A deep reinforcement learning framework for influence maximization problem on large-scale social networks. Sci Rep 16, 11515 (2026). https://doi.org/10.1038/s41598-026-41731-9
キーワード: 影響力最大化, ソーシャルネットワーク, グラフニューラルネットワーク, 強化学習, 情報拡散