Clear Sky Science · fr
Un cadre d'apprentissage par renforcement profond pour le problème de maximisation d'influence sur des réseaux sociaux à grande échelle
Pourquoi la diffusion d'idées en ligne compte
Lorsqu'une vidéo, un produit ou un message politique devient soudainement viral, ce n'est pas juste le fruit du hasard. En coulisses, quelques personnes clés d'un réseau social en ligne déclenchent souvent la vague. Entreprises, organismes de santé publique et militants veulent tous savoir : quels utilisateurs faut‑il cibler en premier pour que le message atteigne le plus grand nombre ? Ce casse‑tête, appelé maximisation d'influence, devient très difficile sur les plateformes sociales massives et complexes d'aujourd'hui. L'article présente un nouveau cadre d'intelligence artificielle, nommé MaDGNN, qui apprend à sélectionner ces comptes « super‑diffuseurs » de manière rapide et fiable, même dans des réseaux très larges et hétérogènes.
Choisir les bons messagers
La maximisation d'influence pose une question simple : avec un budget limité de personnes que vous pouvez contacter directement, lesquelles choisir pour que votre message touche finalement le plus grand nombre d'utilisateurs ? Des travaux antérieurs ont formalisé cela comme un problème d'optimisation mathématique et proposé des algorithmes gloutons soignés qui simulent la façon dont l'information peut se propager de proche en proche. Ces méthodes offrent de fortes garanties théoriques, mais elles exigent un nombre énorme de simulations sur de grands graphes, ce qui les rend lentes et coûteuses en pratique. Des travaux plus récents ont tenté d'accélérer le processus avec l'apprentissage profond, mais beaucoup de ces modèles peinent à généraliser lorsqu'on passe de petits graphes d'entraînement à des plateformes réelles et complexes avec des millions de connexions.
Un moteur d'apprentissage pour les cascades sociales
Les auteurs proposent MaDGNN, qui traite la maximisation d'influence comme un jeu joué étape par étape. À chaque étape, le système regarde quels utilisateurs ont déjà été choisis comme graines puis sélectionne l'utilisateur suivant à contacter, dans le but de maximiser la propagation finale. Pour comprendre la structure du réseau, MaDGNN utilise un type de réseau neuronal spécialement conçu pour les graphes. Ce module « conscient des cascades » crée des empreintes numériques riches pour chaque utilisateur, qui captent non seulement qui sont leurs voisins, mais aussi la façon dont l'influence est susceptible de se propager le long des chaînes de connexions. Des sous‑modules distincts suivent si un utilisateur est actif dans la cascade, à quel point il peut influencer les autres, et à quel point il est lui‑même susceptible d'être convaincu.
Stabiliser les décisions avec un apprentissage par renforcement plus intelligent
Au‑dessus de ces empreintes apprises, MaDGNN utilise l'apprentissage par renforcement — une approche par essai‑erreur où le système est récompensé lorsque ses choix de graines entraînent une large diffusion. Les méthodes classiques d'apprentissage par renforcement peuvent être instables : elles peuvent surestimer la valeur de certaines actions et dériver vers de mauvaises stratégies. Pour y remédier, les auteurs adaptent une technique récente appelée apprentissage par renforcement Munchausen, qui pénalise légèrement les choix excessivement confiants et encourage une exploration saine. Ils ajoutent également des couches bruyantes au réseau de décision, qui injectent de l'aléa directement dans les paramètres internes du modèle plutôt que de ne compter que sur des choix d'action aléatoires. Ensemble, ces ingrédients aident MaDGNN à converger de manière plus fiable vers des politiques robustes de sélection de graines.
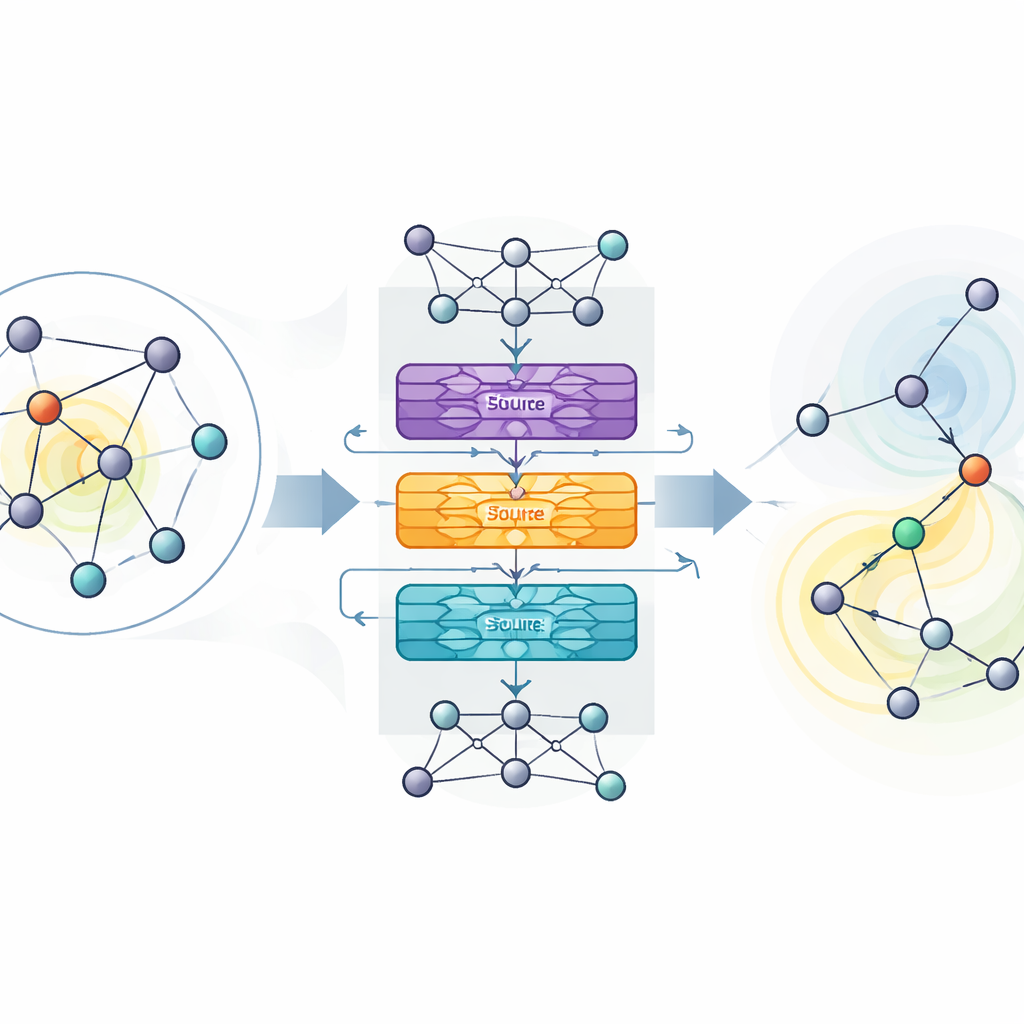
Surpasser les outils existants sur des réseaux réels
Pour tester MaDGNN, les chercheurs l'ont d'abord entraîné sur de petits graphes artificiels puis l'ont évalué sur huit réseaux sociaux et d'information réels, comprenant des sites d'avis de produits, des échanges d'e-mails et des graphes d'amitié Facebook, chacun comptant de quelques milliers à plusieurs centaines de milliers d'utilisateurs. Sur la plupart des jeux de données et sous diverses hypothèses sur la facilité de transmission de l'influence d'un utilisateur à l'autre, MaDGNN a systématiquement sélectionné des ensembles de graines produisant des cascades plus importantes que plusieurs références solides, y compris des algorithmes populaires basés sur l'échantillonnage et d'autres méthodes d'apprentissage par renforcement profond. Il atteignait souvent ces gains avec des temps d'exécution comparables voire inférieurs, et son avantage a été confirmé par des tests statistiques rigoureux.
Regarder sous le capot et au‑delà
L'équipe a aussi disséqué la conception de MaDGNN. Remplacer la règle d'apprentissage standard par la variante Munchausen a amélioré la diffusion d'influence sans augmenter significativement le temps d'exécution. Initialiser les représentations de nœuds avec une technique d'encodage de graphe bien établie a conduit à des gains supplémentaires, et les couches bruyantes ont amélioré les performances en favorisant une meilleure exploration. Fait important, en changeant seulement la manière dont les récompenses sont calculées, la même architecture a fonctionné sous différents modèles d'adoption de l'information, ce qui suggère que MaDGNN capture des indices structurels généraux plutôt que de sur‑adapter à une unique règle de diffusion. Les auteurs notent des défis restants, comme le réglage de certains paramètres de stabilité et la mise à l'échelle vers des réseaux de dizaines de millions d'arêtes, où des astuces supplémentaires comme le partitionnement de graphe pourraient être nécessaires.
Ce que cela signifie pour les campagnes réelles
En termes simples, ce travail montre qu'un système d'apprentissage conçu avec soin peut devenir un stratège puissant pour la diffusion virale. Plutôt que de simuler exhaustivement chaque scénario possible, MaDGNN apprend par l'expérience quels motifs de connexions tendent à déclencher de grandes cascades, puis applique ce savoir à de nouveaux réseaux beaucoup plus larges. Pour les praticiens, cela signifie une utilisation plus efficace des ressources limitées — qu'il s'agisse de choisir quels clients recevoir un accès anticipé à un produit, quels membres de la communauté impliquer dans une campagne de santé, ou quels comptes surveiller pour la lutte contre les rumeurs. Bien que cela ne soit pas une solution miracle et que des limites de scalabilité persistent aux toutes plus grandes échelles, MaDGNN offre une nouvelle référence prometteuse pour transformer la géométrie complexe des réseaux sociaux en plans d'action concrets pour la diffusion de l'information.
Citation: Yang, F., Wang, Y., Shu, N. et al. A deep reinforcement learning framework for influence maximization problem on large-scale social networks. Sci Rep 16, 11515 (2026). https://doi.org/10.1038/s41598-026-41731-9
Mots-clés: maximisation de l'influence, réseaux sociaux, réseaux neuronaux sur graphes, apprentissage par renforcement, diffusion de l'information