Clear Sky Science · de
Ein Deep‑Reinforcement‑Learning‑Rahmenwerk für das Influence‑Maximization‑Problem in großflächigen sozialen Netzwerken
Warum sich das Verbreiten von Ideen online lohnt
Wenn ein Video, ein Produkt oder eine politische Botschaft plötzlich viral geht, ist das nicht nur Zufall. Hinter den Kulissen entfachen in einem Online‑Sozialnetzwerk oft einige wenige Schlüsselfiguren die Welle. Unternehmen, Gesundheitsbehörden und Aktivisten wollen alle wissen: Welche Nutzer sollten eine Botschaft zuerst erhalten, damit sie möglichst viele andere erreicht? Dieses Rätsel, bekannt als Influence‑Maximization, wird auf den heutigen riesigen, verwobenen Plattformen extrem schwierig. Die Studie stellt ein neues KI‑Rahmenwerk namens MaDGNN vor, das lernt, solche „Super‑Verbreiter“ schnell und verlässlich auszuwählen, selbst in sehr großen und heterogenen Netzwerken.
Die richtigen Vermittler auswählen
Influence‑Maximization stellt eine einfache Frage: Angenommen, Sie haben ein begrenztes Budget an Personen, die Sie direkt kontaktieren können — welche davon sollten Sie auswählen, damit Ihre Botschaft schließlich die größtmögliche Zahl von Nutzern erreicht? Frühere Arbeit formalisierte dies als mathematisches Optimierungsproblem und schlug sorgfältige Greedy‑Algorithmen vor, die simulieren, wie Information von Freund zu Freund weitergegeben werden könnte. Diese Methoden bieten starke theoretische Garantien, benötigen jedoch enorm viele Simulationen auf großen Netzwerken, was sie in der Praxis langsam und kostspielig macht. Neuere Ansätze versuchten, mit Deep Learning zu beschleunigen, doch viele dieser Modelle generalisieren schlecht, wenn sie von kleinen Trainingsgraphen auf komplexe Real‑World‑Plattformen mit Millionen von Verbindungen übertragen werden.
Eine Lernmaschine für soziale Kaskaden
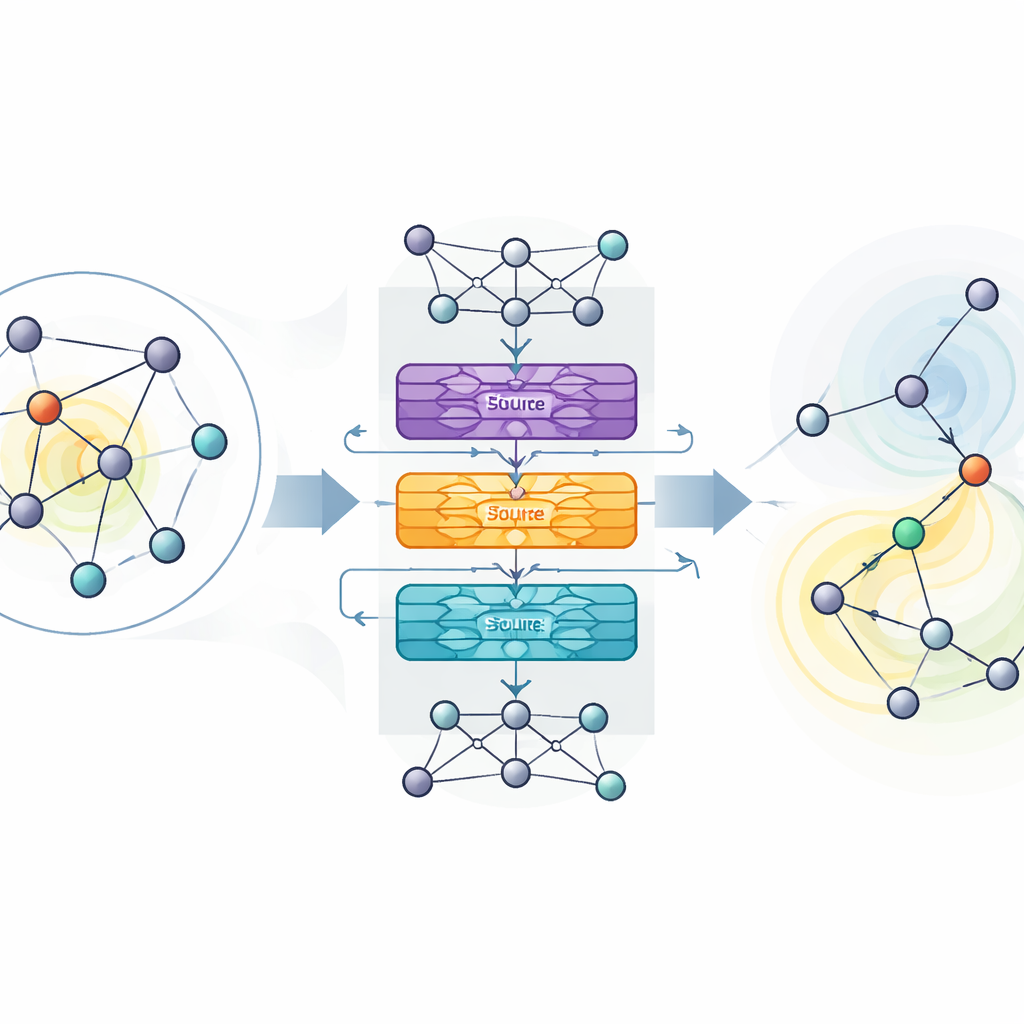
Die Autoren schlagen MaDGNN vor, das Influence‑Maximization als ein Spiel behandelt, das Schritt für Schritt gespielt wird. In jedem Schritt betrachtet das System, welche Nutzer bereits als Seeds ausgewählt sind, und wählt dann den nächsten Nutzer aus, um die letztendliche Verbreitung zu maximieren. Um die Struktur des Netzwerks zu erfassen, verwendet MaDGNN eine spezielle Form neuronaler Netze, die für Graphen entwickelt wurde. Dieses „kaskaden‑bewusste“ Modul erzeugt reichhaltige numerische Fingerabdrücke für jeden Nutzer, die nicht nur zeigen, wer deren Freunde sind, sondern auch, wie Einfluss voraussichtlich entlang von Verbindungsketten durchschlagen wird. Separate Teilmodule verfolgen, ob ein Nutzer in der Kaskade aktiv ist, wie stark er andere beeinflussen kann und wie leicht er selbst zu überzeugen ist.
Entscheidungen stabilisieren mit smarterem Reinforcement Learning
Auf Basis dieser gelernten Fingerabdrücke nutzt MaDGNN Reinforcement Learning — einen Trial‑and‑Error‑Ansatz, bei dem das System belohnt wird, wenn seine Seed‑Wahl zu großer Verbreitung führt. Klassische Reinforcement‑Learning‑Methoden können instabil sein: Sie überschätzen möglicherweise den Wert bestimmter Aktionen und verfallen in schlechte Strategien. Um dem entgegenzuwirken, adaptieren die Autoren eine jüngere Technik namens Munchausen Reinforcement Learning, die übermäßig selbstsichere Entscheidungen sanft bestraft und gesunde Exploration fördert. Zusätzlich fügen sie dem Entscheidungsnetzwerk verrauschte Schichten hinzu, die Zufälligkeit direkt in die internen Parameter des Modells einspeisen, statt sich nur auf zufällige Aktionswahl zu stützen. Zusammengenommen helfen diese Zutaten MaDGNN, verlässlichere und robustere Seed‑Auswahlstrategien zu finden.
Bestehende Werkzeuge in realen Netzwerken übertreffen
Um MaDGNN zu testen, trainierten die Forscher es zunächst auf kleinen künstlichen Graphen und evaluierten es dann auf acht realen sozialen und Informationsnetzwerken, darunter Produktbewertungsseiten, E‑Mail‑Austausche und Facebook‑Freundschaftsgraphen, jeweils mit Tausenden bis Hunderttausenden von Nutzern. In den meisten Datensätzen und unter einer Reihe von Annahmen darüber, wie leicht sich Einfluss von einem Nutzer zum anderen überträgt, wählte MaDGNN durchweg Seed‑Mengen, die größere Kaskaden erzeugten als mehrere starke Baselines, inklusive populärer sampling‑basierter Algorithmen und anderer Deep‑Reinforcement‑Learning‑Methoden. Häufig erzielte es diese Verbesserungen bei vergleichbaren oder sogar kürzeren Laufzeiten, und sein Vorteil hielt sich unter sorgfältigen statistischen Tests.
Unter die Haube und darüber hinaus schauen
Das Team zerlegte außerdem MaDGNNs Aufbau. Der Ersatz der Standard‑Lernregel durch die Munchausen‑Variante verbesserte die Verbreitung, ohne die Laufzeit merklich zu erhöhen. Die Initialisierung von Knotendarstellungen mit einer etablierten Graph‑Embedding‑Technik führte zu weiteren Verbesserungen, und die verrauschten Schichten steigerten die Leistung durch bessere Exploration. Wichtig ist, dass die gleiche Architektur durch alleinige Änderung der Belohnungsberechnung unter verschiedenen Modellen der Informationsannahme funktionierte, was darauf hindeutet, dass MaDGNN allgemeine strukturelle Hinweise erfasst, statt sich an eine einzelne Diffusionsregel zu überanpassen. Die Autoren nennen verbleibende Herausforderungen, etwa das Abstimmen bestimmter Stabilitätsparameter und das Skalieren auf Netzwerke mit mehreren zehn Millionen Kanten, wo zusätzliche Tricks wie Graph‑Partitionierung nötig sein könnten.
Was das für reale Kampagnen bedeutet
Ganz praktisch zeigt diese Arbeit, dass ein sorgfältig gestaltetes Lernsystem zu einem starken Strategen für virale Outreach‑Kampagnen werden kann. Anstatt jede mögliche Situation erschöpfend zu simulieren, lernt MaDGNN aus Erfahrung, welche Verbindungsmuster tendenziell große Kaskaden auslösen, und wendet dieses Wissen dann auf neue, deutlich größere Netzwerke an. Für Praktiker bedeutet das effektivere Nutzung knapper Ressourcen — sei es bei der Auswahl von Kunden für frühen Zugang zu einem Produkt, bei der Einbeziehung von Community‑Mitgliedern in eine Gesundheitskampagne oder bei der Überwachung von Konten zur Bekämpfung von Gerüchten. Zwar ist MaDGNN kein Allheilmittel und stößt bei den allergrößten Skalen noch an Grenzen, bietet aber eine vielversprechende neue Referenz dafür, wie sich die komplexe Geometrie sozialer Netzwerke in konkrete Pläne zur Verbreitung von Informationen verwandeln lässt.
Zitation: Yang, F., Wang, Y., Shu, N. et al. A deep reinforcement learning framework for influence maximization problem on large-scale social networks. Sci Rep 16, 11515 (2026). https://doi.org/10.1038/s41598-026-41731-9
Schlüsselwörter: Einflussmaximierung, soziale Netzwerke, Graph‑Neuronale Netze, Reinforcement Learning, Informationsdiffusion