Clear Sky Science · ar
إطار تعلم معزز عميق لمشكلة تعظيم التأثير على شبكات اجتماعية واسعة النطاق
لماذا يهم نشر الأفكار على الإنترنت
عندما ينتشر مقطع فيديو أو منتج أو رسالة سياسية فجأة بشكل فيروسي، فالأمر ليس مجرد حظ. غالبًا ما يكون خلف الكواليس عدد قليل من الأشخاص الرئيسيين في شبكة اجتماعية على الإنترنت هم من يشعلون الموجة. الشركات والهيئات الصحية العامة والنشطاء يرغبون جميعًا في معرفة: من هم المستخدمون الذين ينبغي أن يتلقوا الرسالة أولاً كي تصل إلى أكبر عدد ممكن من الآخرين؟ هذه المسألة، المعروفة بتعظيم التأثير، تصبح صعبة للغاية على منصات التواصل الضخمة والمعقدة اليوم. تقدم الورقة إطارًا جديدًا للذكاء الاصطناعي، يسميه المؤلفون MaDGNN، يتعلم كيفية اختيار هذه الحسابات "الناشرة الفائقة" بسرعة وبموثوقية، حتى في شبكات كبيرة ومتنوعة جدًا.
اختيار المراسلين المناسبين
تطرح مسألة تعظيم التأثير سؤالًا بسيطًا: بالنظر إلى ميزانية محدودة من الأشخاص الذين يمكنك التواصل معهم مباشرة، من منهم ينبغي أن تختار لكي تصل رسالتك في نهاية المطاف إلى أكبر عدد من المستخدمين؟ دراسات سابقة صاغت هذا على أنه مسألة تحسين رياضية واقترحت خوارزميات جشعة دقيقة تُحاكي كيف قد يتدفق المعلومات من صديق إلى آخر. تأتي هذه الطرق بضمانات نظرية قوية، لكنها تتطلب أعدادًا هائلة من المحاكاة على شبكات كبيرة، مما يجعلها بطيئة ومكلفة في التطبيق. حاولت أعمال أحدث تسريع العملية باستخدام التعلم العميق، لكن العديد من تلك النماذج تفشل في التعميم بشكل جيد عند الانتقال من رسومات تدريب صغيرة إلى منصات العالم الحقيقي المعقدة ذات الملايين من الروابط.
محرك تعلم لتدفقات الانتشار
يقترح المؤلفون MaDGNN، الذي يتعامل مع تعظيم التأثير كلعبة تُلعب خطوة بخطوة. في كل خطوة، ينظر النظام إلى المستخدمين الذين تم اختيارهم بالفعل كبذور ثم يختار المستخدم التالي للتواصل معه، سعيًا لتعظيم الانتشار النهائي. لفهم بنية الشبكة، يستخدم MaDGNN نوعًا من الشبكات العصبية المصممة خصيصًا للرسوم البيانية. يبتكر هذا المكوّن "الواعي بالتدفق" بصمات رقمية غنية لكل مستخدم تلتقط ليس فقط من هم أصدقاؤهم، ولكن أيضًا كيف من المحتمل أن يتردد التأثير عبر سلاسل من الروابط. تتعقب وحدات فرعية منفصلة ما إذا كان المستخدم نشطًا في التدفق، ومدى قوة تأثيره على الآخرين، ومدى سهولة إقناعه بنفسه.
ترسيخ القرار بتعلم معزز أذكى
فوق هذه البصمات المتعلمة، يستخدم MaDGNN التعلم المعزز—نهج التجربة والخطأ حيث يُكافأ النظام عندما تؤدي اختياراته للبذور إلى انتشار واسع. قد تكون طرق التعلم المعزز الكلاسيكية غير مستقرة: فقد تُبالغ في تقدير قيمة بعض الإجراءات وتنجرف نحو استراتيجيات ضعيفة. لمواجهة ذلك، يُكيّف المؤلفون تقنية حديثة تسمى التعلم المعزز مونشهاوزن، التي تعاقب بلطف الاختيارات المفرطة الثقة وتشجع على استكشاف صحي. كما يضيفون طبقات ضوضائية إلى شبكة القرار، التي تضخ العشوائية مباشرة في معلمات النموذج الداخلية بدلًا من الاعتماد فقط على اختيارات أفعال عشوائية. معًا، تساعد هذه المكونات MaDGNN على الالتقاء بشكل أكثر موثوقية على سياسات اختيار بذور قوية.
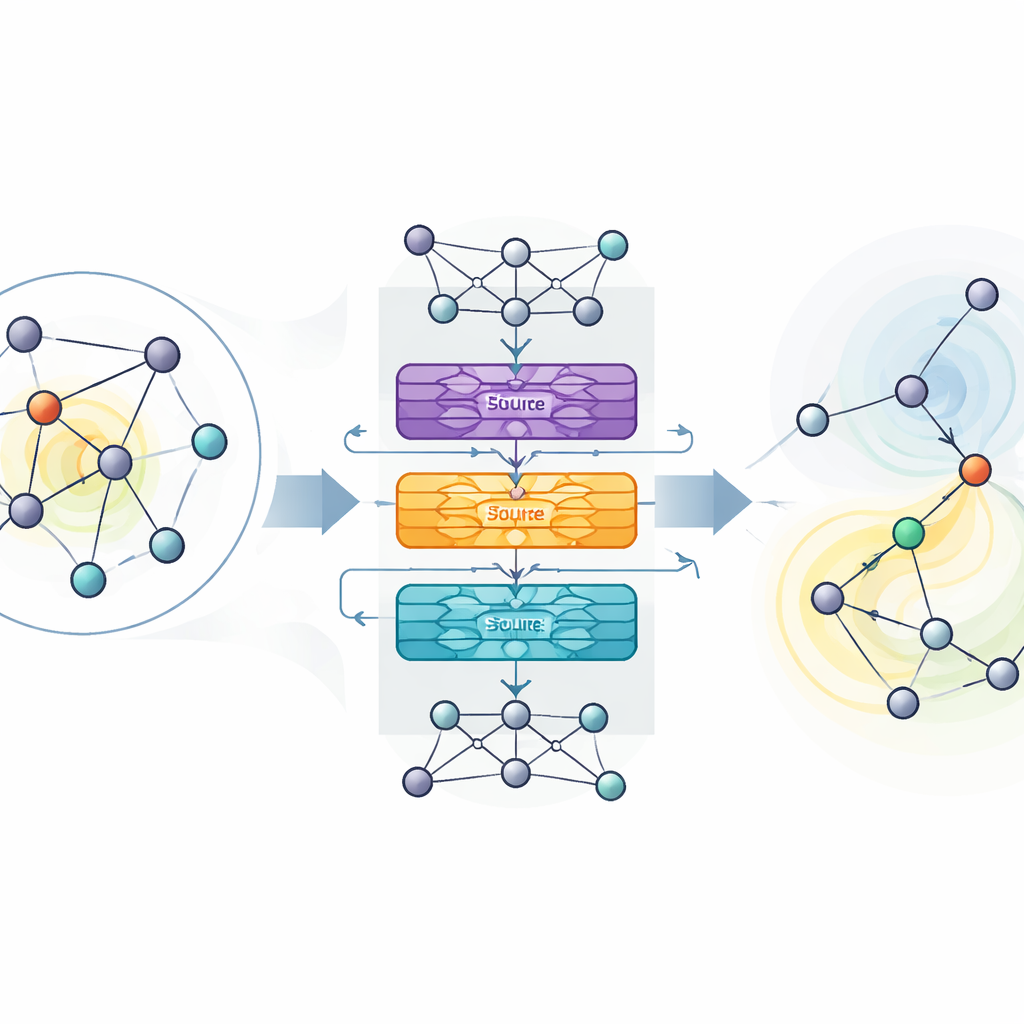
تفوق على الأدوات الحالية في شبكات حقيقية
لاختبار MaDGNN، درّبه الباحثون أولًا على رسومات صناعية صغيرة ثم قيّموه على ثماني شبكات اجتماعية ومعلوماتية حقيقية، بما في ذلك مواقع مراجعات المنتجات، وتبادلات البريد الإلكتروني، ورسومات صداقات فيسبوك، كل منها تحتوي على آلاف إلى مئات الآلاف من المستخدمين. عبر معظم مجموعات البيانات وتحت مجموعة من الافتراضات حول مدى سهولة انتقال التأثير من مستخدم لآخر، اختار MaDGNN باستمرار مجموعات بذور أفضت إلى تدفقات أكبر مقارنة بعدة معايير قوية، بما في ذلك خوارزميات أخذ عينات شائعة وطرق أخرى للتعلم المعزز العميق. غالبًا ما حقق هذه المكاسب بزمن تشغيل قابل للمقارنة أو حتى أقل، وبقيت ميزته قائمة بعد اختبارات إحصائية دقيقة.
نظرة تحت الغطاء وما بعده
حلل الفريق أيضًا تصميم MaDGNN. استبدال قاعدة التعلم القياسية بنسخة مونشهاوزن حسّن انتشار التأثير دون زيادة ذات دلالة في وقت التشغيل. أدى تهيئة تمثيلات العقد باستخدام تقنية تضمين رسومي معروفة إلى مكاسب إضافية، وعززت الطبقات الضوضائية الأداء من خلال تشجيع استكشاف أفضل. والأهم من ذلك، بأن تغييرًا بسيطًا في طريقة حساب المكافآت جعل نفس البنية تعمل تحت نماذج مختلفة لكيفية تبني الناس للمعلومات، ما يشير إلى أن MaDGNN يلتقط مؤشرات هيكلية عامة بدلًا من الإفراط في التخصيص لقاعدة نشر واحدة. يشير المؤلفون إلى تحديات متبقية، مثل ضبط بعض معلمات الاستقرار والتوسع إلى شبكات بها عشرات الملايين من الحواف، حيث قد تكون حيل إضافية مثل تقسيم الرسم ضرورية.
ماذا يعني هذا للحملات في العالم الحقيقي
بعبارة بسيطة، تُظهر هذه الدراسة أن نظام تعلم مصمم بعناية يمكن أن يصبح استراتيجيًا قويًا للتوعية الفيروسية. بدلًا من محاكاة كل سيناريو ممكن استنفادًا، يتعلم MaDGNN من التجربة أي أنماط الروابط تميل إلى إشعال تدفقات كبيرة ثم يطبّق تلك المعرفة على شبكات جديدة وأكبر بكثير. بالنسبة للممارسين، يعني هذا استخدامًا أكثر فعالية للموارد المحدودة—سواء كان اختيار أي العملاء يمنحون وصولًا مبكرًا لمنتج، أو أي أفراد المجتمع يتم إشراكهم في حملة صحية، أو أي حسابات ينبغي مراقبتها للسيطرة على الشائعات. ومع أنه ليس حلاً سحريًا ولا يزال يواجه حدودًا في قابلية التوسع على أضخم المقاييس، يقدم MaDGNN معيارًا واعدًا لتحويل الهندسة المعقدة للشبكات الاجتماعية إلى خطط قابلة للتنفيذ لنشر المعلومات.
الاستشهاد: Yang, F., Wang, Y., Shu, N. et al. A deep reinforcement learning framework for influence maximization problem on large-scale social networks. Sci Rep 16, 11515 (2026). https://doi.org/10.1038/s41598-026-41731-9
الكلمات المفتاحية: تعظيم التأثير, الشبكات الاجتماعية, الشبكات العصبية الرسومية, التعلم المعزز, انتشار المعلومات