Clear Sky Science · zh
在资源受限设备上实现动态卡纳达手语识别
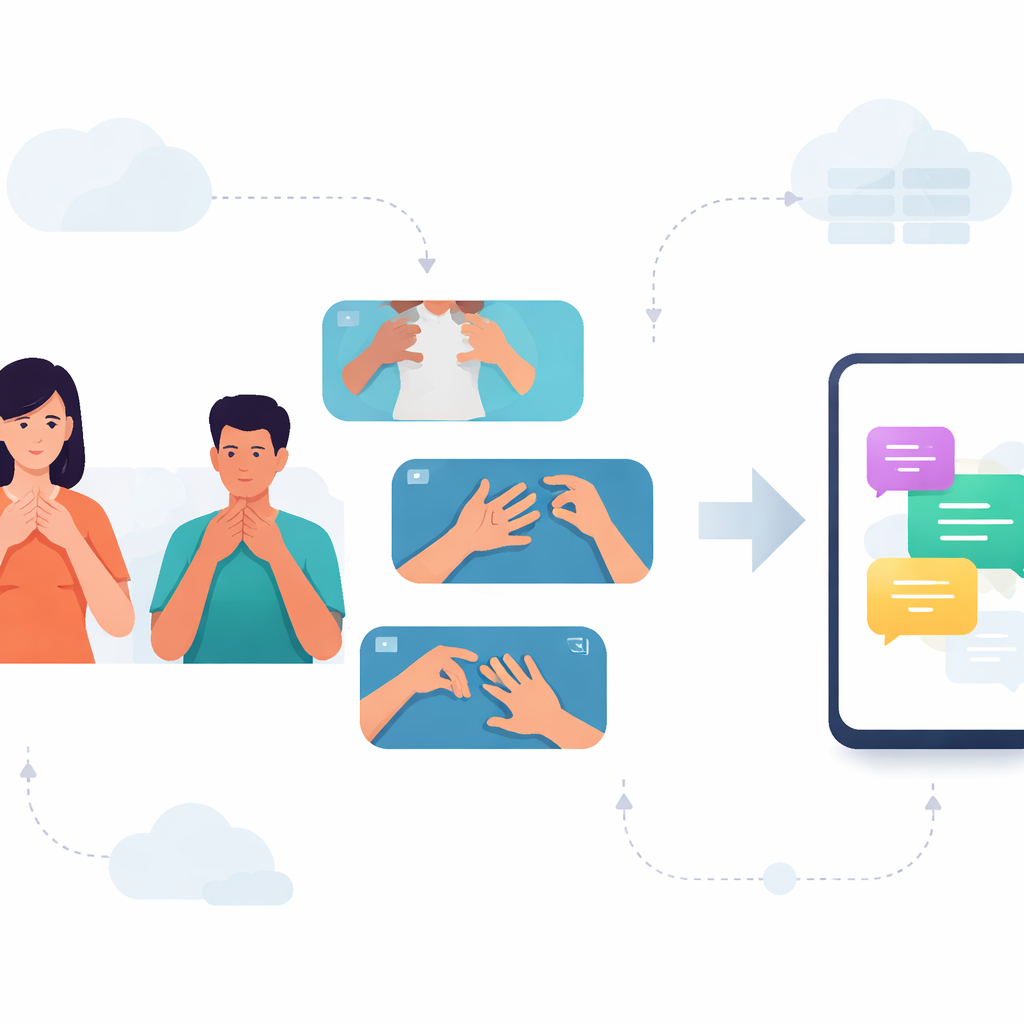
弥合对话鸿沟
对于卡纳塔克邦的许多聋人来说,日常对话依赖卡纳达手语(KSL)。然而大多数手机和应用只理解口语和书面语言,使得使用KSL的人缺乏他人习以为常的数字工具。本研究通过构建一个能够从视频中读取短时KSL手势并能在普通智能手机上高效运行的系统来填补这一空白,从而为手语者与非手语者之间更快速、更私密的交流打开了可能。
构建面向现实世界的手语库
由于不存在公开的KSL词汇视频数据库,研究人员从头开始创建了一个。他们与一所聋童学校的教师以及来自卡纳塔克邦的38名志愿者合作,录制了两千多段KSL手语视频。团队聚焦于33个日常词汇,分为四个主题:水果、月份、一周的日子以及一天中的时段或季节。每个词进行了多次拍摄,速度不同、地点各异、光照条件不同。这样的多样性使系统能够应对生活中混乱且不可预测的情形,而不是只在理想化的实验室条件下工作。
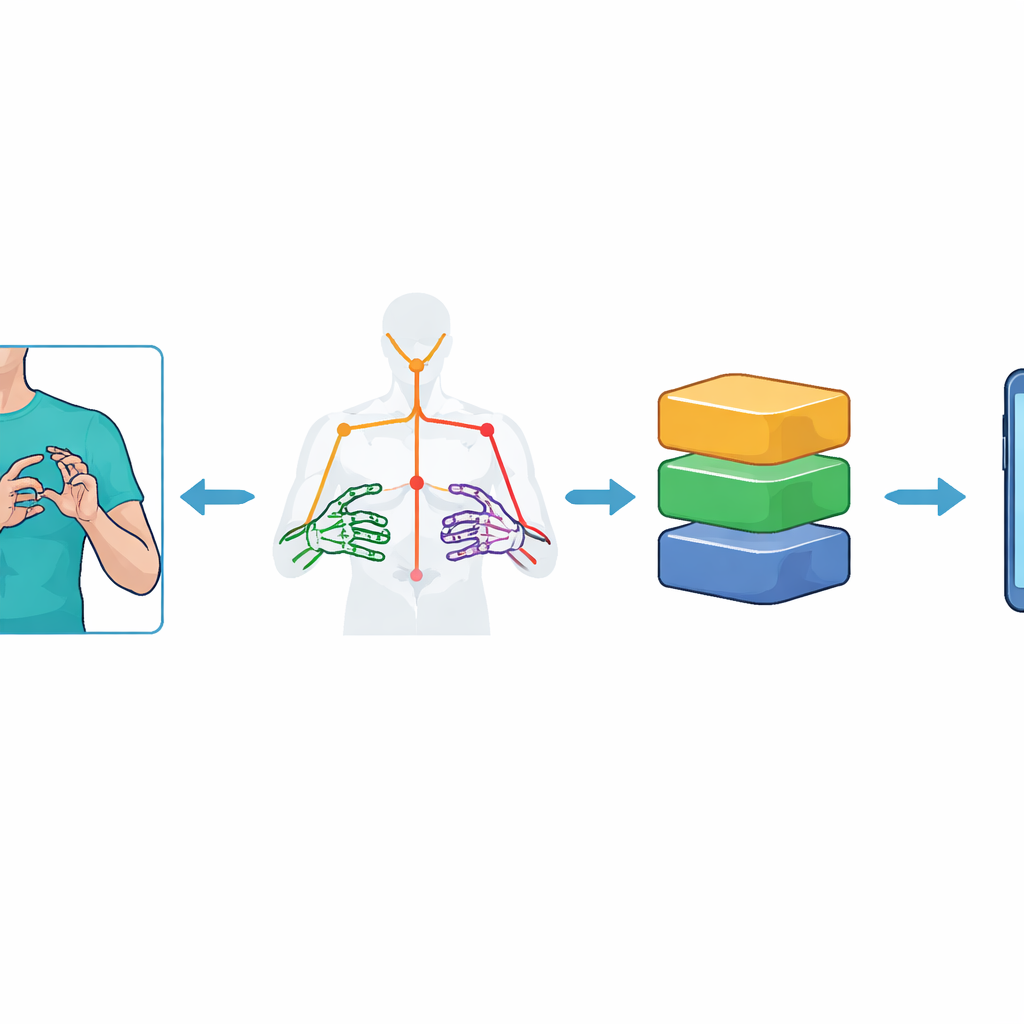
教计算机“看”运动
系统并不将完整视频帧输入笨重的视觉模型,而是先将每帧简化为表示上半身和手部的关键点集合。研究人员使用谷歌的 MediaPipe Holistic 工具包跟踪59个标志点——例如肩膀、肘部、手腕和手指关节——并记录它们随时间变化的三维位置。这样就生成了每个手势序列的紧凑“骨架”:每段视频75帧,每帧包含177个数值特征。为增强系统对噪声的鲁棒性,他们通过精心的视频增强扩展数据集,加入小幅摄像机倾斜、光照变化、人工噪点、运动加速和减速等。这些步骤帮助模型学习手势的本质,而不是记住特定的背景或录制条件。
三种读取动态手势的方法
在这种更简洁的运动表示下,团队比较了三种用于识别每个手语词的深度学习方法。第一种是 LSTM,一种设计用于逐帧跟踪序列、在记住重要细节的同时忘掉干扰的网络。第二种是 BiLSTM,从过去到未来和从未来到过去两个方向观察手势,为运动提供更丰富的视角。第三种是仅编码器的 Transformer,它通过注意力机制将所有帧相互关联起来:不是严格按顺序扫描,而是学习手势中哪些时刻彼此最相关。三种模型都使用相同的数据划分为训练、验证和测试集,并被调优以仅从运动模式对33个词进行分类。
将强大模型压缩到微型设备
高精度模型通常对中端手机等资源受限设备来说过于庞大和缓慢。为此,作者采用了基于 TinyML 的优化并使用 TensorFlow Lite。通过降低内部权重的数值精度(称为训练后量化),他们将每个训练好的模型转换为更小的版本。尝试了几种方案,包括动态范围量化、float16 以及全整数量化变体。这些精简后的模型被嵌入到基于 Flutter 的 Android 应用中。由于目前在 Flutter 中无法直接在手机上运行 MediaPipe Holistic,研究团队使用一个外部的轻量级服务器提取关键点,并仅将紧凑的运动数据发送回应用,应用在设备端执行最终识别。
手中的快速、准确的手语识别
尽管为了速度和尺寸进行了裁剪,表现最好的模型仍然保持了令人印象深刻的性能:在33个KSL词上的测试准确率约为94%–96%。动态量化的 BiLSTM 达到最高准确率 95.71%,而量化后的 Transformer 模型则提供了最快的手机端预测——每个手势约16毫秒,模型大小仅略超1 MB。LSTM 在大小、速度和准确率之间取得了中间折衷。三者在 CPU 和内存使用上都很适中,表明实时的 KSL 识别即使在日常智能手机上、无需持续联网或昂贵硬件也能实用。
这对日常生活意味着什么
简言之,这项工作表明有可能赋予普通智能手机从短视频中“理解”一组核心 KSL 词的能力,做到可靠且快速。通过构建专门的 KSL 视频数据集、将手势提炼为身体与手部骨架,并将现代序列模型压缩以在边缘设备上高效运行,研究人员为面向区域语言的可及手语识别技术提供了蓝图。尽管当前系统仅处理33个独立词并仍依赖于用于特征提取的小型服务器,但它标志着朝着更丰富、完全在设备上运行的工具迈出的实质性一步,这些工具可能帮助数十万名 KSL 用户更顺畅地与听力人群交流。
引用: V, U., K S, N., K S, N. et al. Dynamic Kannada Sign Language Recognition on Resource Constrained Devices. Sci Rep 16, 11186 (2026). https://doi.org/10.1038/s41598-026-40181-7
关键词: 卡纳达手语, 移动手语识别, TinyML, 手势识别, 辅助技术