Clear Sky Science · de
Dynamische Erkennung der Kannada-Gebärdensprache auf ressourcenbeschränkten Geräten
Die Gesprächslücke überbrücken
Für viele gehörlose Menschen in Karnataka hängen alltägliche Gespräche von der Kannada-Gebärdensprache (KSL) ab. Die meisten Telefone und Apps verstehen jedoch nur gesprochene und geschriebene Sprachen, sodass KSL-Nutzende von den digitalen Werkzeugen ausgeschlossen sind, die andere für selbstverständlich halten. Diese Studie geht diese Lücke an, indem sie ein System entwickelt, das kurze KSL-Zeichen aus Video erkennt und effizient auf gewöhnlichen Smartphones läuft – und damit schnellere, privatere Kommunikation zwischen Gebärdenden und Nicht-Gebärdenden ermöglicht.
Aufbau einer realen Gebärdenbibliothek
Da keine öffentliche Videodatenbank mit KSL-Wörtern existierte, begannen die Forschenden damit, eine solche von Grund auf zu erstellen. Sie arbeiteten mit Lehrkräften einer Schule für gehörlose Kinder und 38 Freiwilligen aus ganz Karnataka zusammen und nahmen mehr als zweitausend Videos von KSL-Zeichen auf. Der Fokus lag auf 33 alltäglichen Wörtern, die in vier Themen gruppiert waren: Obst, Monate, Wochentage und Tageszeiten bzw. Jahreszeiten. Jedes Wort wurde mehrfach gefilmt, in unterschiedlichem Tempo, an verschiedenen Orten und unter variierenden Lichtverhältnissen. Diese Vielfalt hilft dem System, mit den unordentlichen, unvorhersehbaren Bedingungen des echten Lebens zurechtzukommen, statt nur in perfekten Laborbedingungen zu funktionieren.
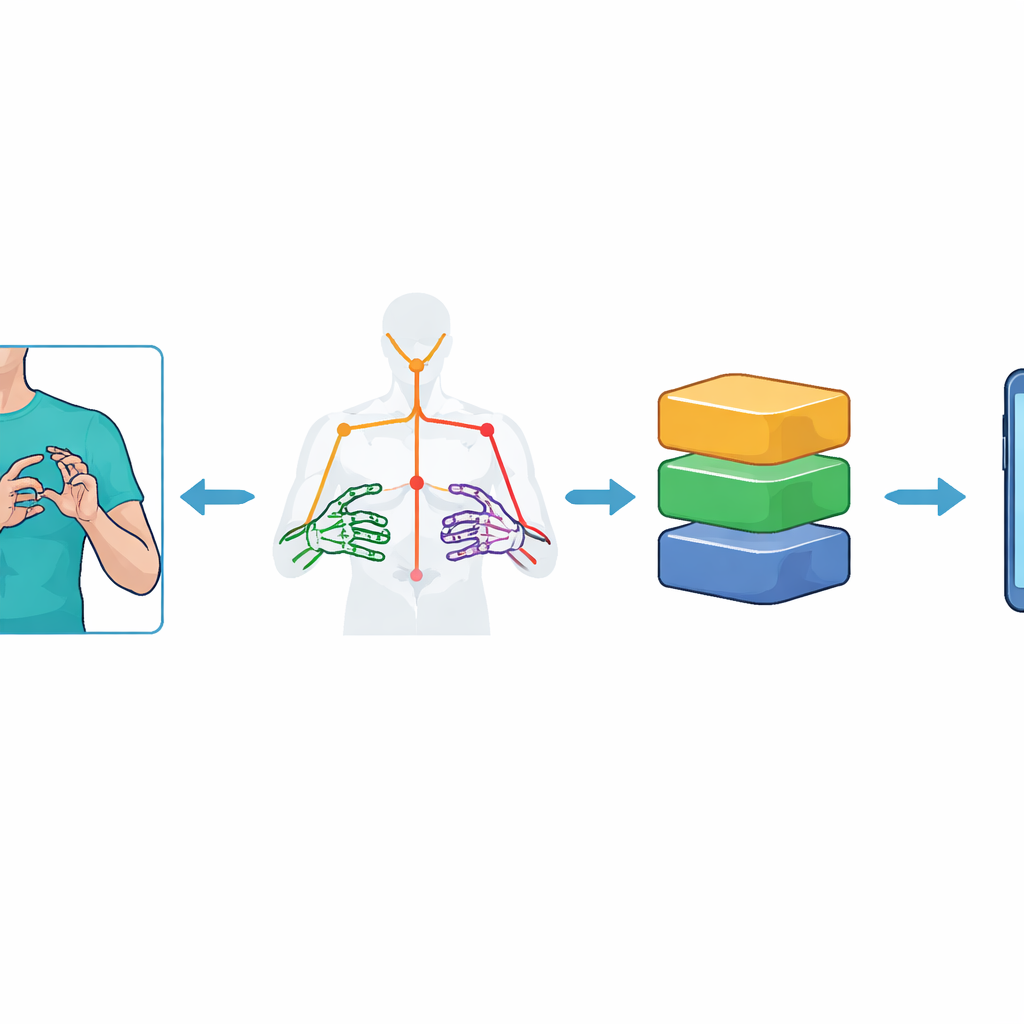
Computern das Sehen von Bewegung beibringen
Anstatt komplette Videobilder in ein schweres Vision-Modell zu speisen, reduziert das System jedes Einzelbild zunächst auf eine Reihe von Schlüsselpunkten, die Oberkörper und Hände der gebärdenden Person repräsentieren. Mit Googles MediaPipe Holistic-Toolkit verfolgen die Forschenden 59 Landmarken – etwa Schulter, Ellbogen, Handgelenk und Fingergelenke – und zeichnen deren 3D-Positionen über die Zeit auf. Das ergibt ein kompaktes „Skelett“ jeder Gestenfolge: 75 Frames pro Video, jeweils mit 177 numerischen Merkmalen. Um das System gegen Störungen zu stärken, erweitern sie den Datensatz durch gezielte Videoaugmentierungen: leichte Kamerakippungen, Änderungen der Beleuchtung, künstliches Rauschen, sowie Beschleunigungen und Verlangsamungen der Bewegung. Diese Schritte helfen den Modellen, das Wesentliche einer Gebärde zu lernen, statt einen bestimmten Hintergrund oder Aufnahmezustand auswendig zu lernen.
Drei Wege, eine bewegte Gebärde zu lesen
Mit dieser kompakteren Darstellung der Bewegung vergleicht das Team drei Deep-Learning-Ansätze zur Erkennung jedes gebärdeten Wortes. Der erste ist ein LSTM, ein Netzwerk, das darauf ausgelegt ist, Sequenzen Frame für Frame zu verfolgen, sich wichtige Details zu merken und Ablenkungen zu vergessen. Der zweite, ein BiLSTM, betrachtet die Geste sowohl von Vergangenheit zu Zukunft als auch umgekehrt und erhält so eine reichere Sicht auf die Bewegung. Der dritte ist ein reiner Encoder-Transformer, der alle Frames zueinander in Beziehung setzt mittels eines Aufmerksamkeitsmechanismus: statt strikt der Reihenfolge zu folgen, lernt er, welche Momente der Gebärde besonders voneinander abhängen. Alle drei Modelle erhalten die gleichen Daten, aufgeteilt in Trainings-, Validierungs- und Testmengen, und werden darauf abgestimmt, die 33 Wörter allein aus den Bewegungsmustern zu klassifizieren.
Leistungsfähige Modelle für winzige Geräte schrumpfen
Hochgenaue Modelle sind oft zu groß und zu langsam für ressourcenbeschränkte Geräte wie Mittelklasse-Smartphones. Um dies zu lösen, wenden die Autorinnen und Autoren TinyML-ähnliche Optimierungen mit TensorFlow Lite an. Sie konvertieren jedes trainierte Modell in kleinere Versionen, indem sie die numerische Präzision der internen Gewichte reduzieren – ein Verfahren, das als Post-Training-Quantisierung bekannt ist. Es werden mehrere Schemata getestet, darunter dynamischer Bereich, Float16 und vollinteger Varianten. Diese geschrumpften Modelle werden dann in eine Flutter-basierte Android-App eingebettet. Da es derzeit keine eingebaute Unterstützung gibt, um MediaPipe Holistic direkt innerhalb von Flutter auf dem Telefon auszuführen, extrahiert ein externes, leichtgewichtiges Servermodul die Schlüsselpunktdaten und sendet nur die kompakten Bewegungsdaten zurück an die App, die die finale Erkennung lokal auf dem Gerät durchführt.
Schnelle, genaue Gebärdenerkennung in der Hand
Trotz der Reduktion zugunsten von Geschwindigkeit und Größe behalten die besten Modelle eine beeindruckende Leistung: rund 94–96 % Testgenauigkeit bei den 33 KSL-Wörtern. Das dynamisch quantisierte BiLSTM erreicht mit 95,71 % die höchste Genauigkeit, während das quantisierte Transformer-Modell die schnellsten Vorhersagen auf dem Telefon bietet – etwa 16 Millisekunden pro Gebärde – bei einer Modellgröße von knapp über 1 MB. Das LSTM bildet einen Kompromiss zwischen Größe, Geschwindigkeit und Genauigkeit. Alle drei laufen mit moderatem CPU- und Speicherverbrauch, was darauf hindeutet, dass Echtzeit-KSL-Erkennung praktisch selbst auf Alltags-Smartphones möglich ist, ohne ständige Internetverbindung oder teure Hardware.
Was das für den Alltag bedeutet
Einfach ausgedrückt zeigt diese Arbeit, dass es möglich ist, einem normalen Smartphone die Fähigkeit zu geben, eine Kernmenge von KSL-Wörtern aus kurzen Videos zuverlässig und schnell zu "verstehen". Durch den Aufbau eines dedizierten KSL-Video-Datensatzes, das Destillieren von Gesten zu Körper- und Handskeletten und das Komprimieren moderner Sequenzmodelle für effizientes Edge-Computing liefern die Forschenden eine Blaupause für zugängliche Gebärdensprachtechnologie, die an eine regionale Sprache angepasst ist. Zwar verarbeitet das aktuelle System nur 33 isolierte Wörter und ist noch auf einen kleinen Server zur Merkmalsextraktion angewiesen, doch es ist ein konkreter Schritt hin zu reichhaltigeren, vollständig auf dem Gerät laufenden Werkzeugen, die Hunderttausenden KSL-Nutzenden eine flüssigere Kommunikation mit Hörenden ermöglichen könnten.
Zitation: V, U., K S, N., K S, N. et al. Dynamic Kannada Sign Language Recognition on Resource Constrained Devices. Sci Rep 16, 11186 (2026). https://doi.org/10.1038/s41598-026-40181-7
Schlüsselwörter: Kannada-Gebärdensprache, mobile Gebärdenspracherkennung, TinyML, Gestenerkennung, assistive Technologie