Clear Sky Science · nl
Dynamische herkenning van Kannada-gebarentaal op apparaten met beperkte middelen
De kloof in het gesprek overbruggen
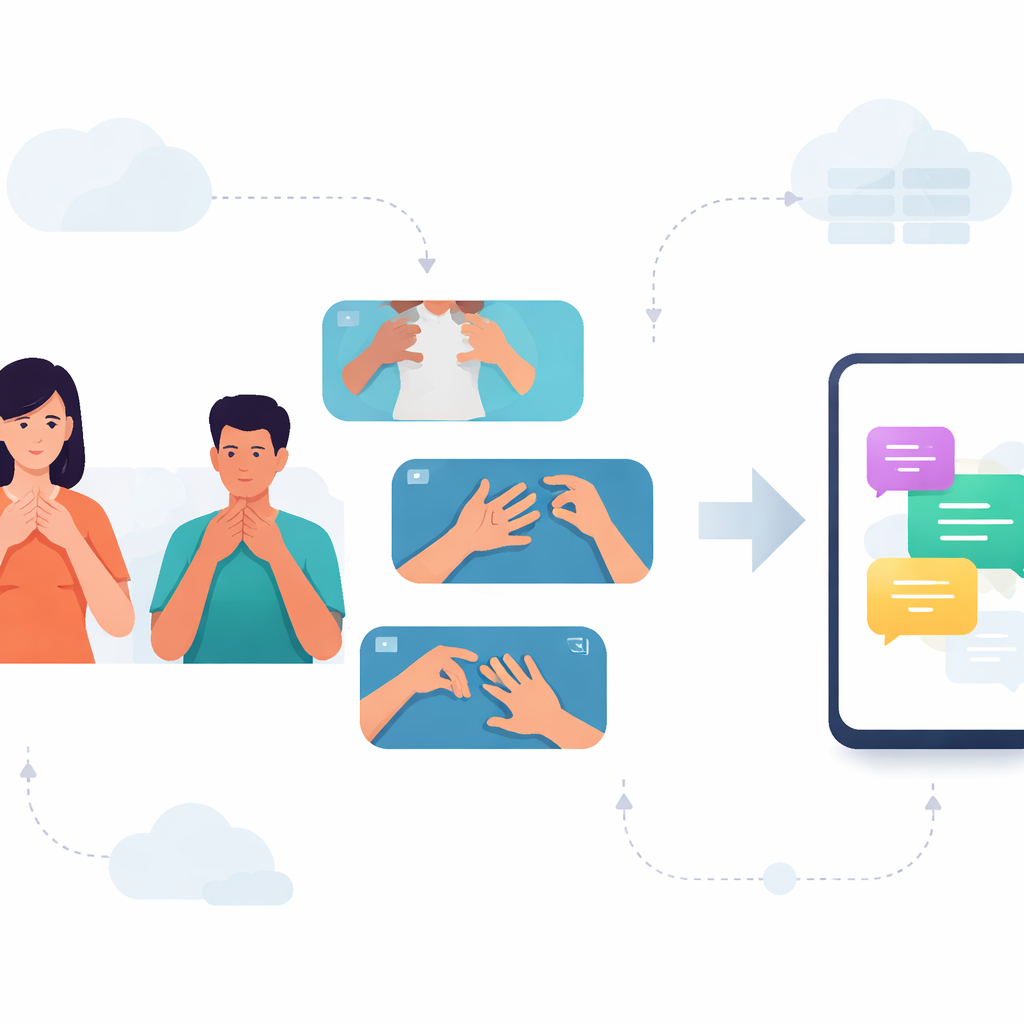
Voor veel dove mensen in Karnataka draaien alledaagse gesprekken om Kannada-gebarentaal (KSL). Toch begrijpen de meeste telefoons en apps alleen gesproken en geschreven talen, waardoor KSL-gebruikers de digitale hulpmiddelen missen die anderen normaal vinden. Deze studie pakt die kloof aan door een systeem te bouwen dat korte KSL-gebaren uit video kan lezen en efficiënt kan draaien op gewone smartphones, waardoor snellere en privĂŠdere communicatie tussen gebarenden en niet-gebarenden mogelijk wordt.
Een praktijkgerichte bibliotheek met gebaren bouwen
Aangezien er geen publieke videodatabase van KSL-woorden bestond, begonnen de onderzoekers met het zelf opzetten daarvan. Ze werkten samen met docenten van een school voor dove kinderen en 38 vrijwilligers uit heel Karnataka om meer dan tweeduizend video’s van KSL-gebaren op te nemen. Het team richtte zich op 33 alledaagse woorden, gegroepeerd in vier thema’s: fruit, maanden, weekdagen en tijden van de dag of seizoenen. Elk woord werd meerdere keren gefilmd, in verschillende snelheden, op verschillende locaties en onder wisselende verlichting. Deze variatie helpt het systeem om te gaan met de rommelige, onvoorspelbare omstandigheden van het echte leven in plaats van alleen in een perfecte laboratoriumopstelling te werken.
Computers leren beweging te zien
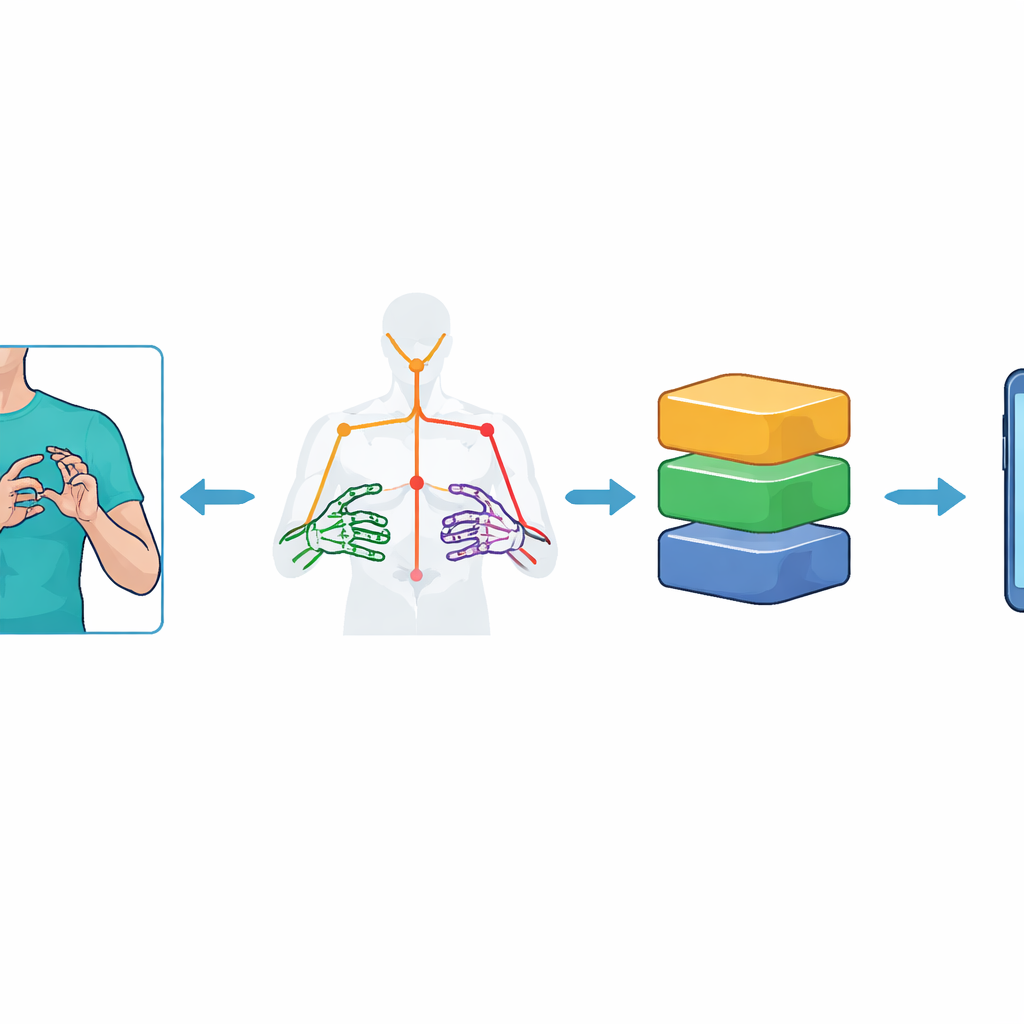
In plaats van volledige videoframes in een zwaar beeldmodel te voeren, reduceert het systeem elk frame eerst tot een set sleutelpunten die het bovenlichaam en de handen van de gebarende weergeven. Met behulp van Google’s MediaPipe Holistic toolkit volgen de onderzoekers 59 landmerken—zoals schouder, elleboog, pols en vingergewrichten—en leggen ze hun 3D-posities in de tijd vast. Dit levert een compact "skelet" van elke gebaarreeks op: 75 frames per video, elk met 177 numerieke kenmerken. Om het systeem robuuster te maken tegen ruis, vergroten ze de dataset met zorgvuldige videoaugmentaties, waarbij kleine camerakantelingen, lichtveranderingen, kunstmatige spikkels en versnellingen en vertragingen van beweging worden toegevoegd. Deze stappen helpen de modellen de essentie van een gebaar te leren in plaats van een specifieke achtergrond of opnameconditie te memoriseren.
Drie manieren om een bewegend gebaar te lezen
Met deze schonere bewegingsrepresentatie vergelijkt het team drie deep-learningbenaderingen voor het herkennen van elk getekend woord. De eerste is een LSTM, een netwerk dat is ontworpen om sequenties frame voor frame te volgen, belangrijke details te onthouden en afleidingen te vergeten. De tweede, een BiLSTM, bekijkt het gebaar zowel van verleden naar toekomst als van toekomst naar verleden, wat een rijker beeld van de beweging geeft. De derde is een encoder-only Transformer, die alle frames in relatie tot elkaar onderzoekt met een aandachtmechanisme: in plaats van strikt in volgorde te scannen, leert hij welke momenten in het gebaar het meest op elkaar betrekking hebben. Alle drie de modellen krijgen dezelfde data verdeeld in trainings-, validatie- en testsets en worden afgestemd om de 33 woorden alleen uit de bewegingspatronen te classificeren.
Krachtige modellen verkleinen voor kleine apparaten
Modellen met hoge nauwkeurigheid zijn vaak te groot en traag voor apparaten met beperkte middelen, zoals telefoons uit het middensegment. Om dit op te lossen passen de auteurs TinyML-achtige optimalisaties toe met TensorFlow Lite. Ze zetten elk getraind model om in kleinere versies door de numerieke precisie van de interne gewichten te verlagen—een proces dat na-training-quantisatie wordt genoemd. Er worden verschillende schema’s geprobeerd, waaronder dynamic range, float16 en full-integer varianten. Deze ingekorte modellen worden vervolgens ingebed in een Flutter-gebaseerde Android-app. Omdat er nog geen ingebouwde ondersteuning is om MediaPipe Holistic direct op de telefoon binnen Flutter uit te voeren, extraheert een externe, lichte server de sleutelpunten en stuurt alleen de compacte bewegingsdata terug naar de app, die de uiteindelijke herkenning op het apparaat uitvoert.
Snel en nauwkeurig gebaarlezen in je hand
Ondanks dat ze zijn teruggebracht voor snelheid en formaat, behouden de beste modellen indrukwekkende prestaties: ongeveer 94–96% testnauwkeurigheid op de 33 KSL-woorden. De dynamisch gequantiseerde BiLSTM bereikt de hoogste nauwkeurigheid met 95,71%, terwijl het gequantiseerde Transformer-model de snelste voorspellingen op de telefoon biedt—ongeveer 16 milliseconden per gebaar—met een modelgrootte net boven 1 MB. De LSTM vormt een middenweg tussen formaat, snelheid en nauwkeurigheid. Alle drie werken met bescheiden CPU- en geheugenverbruik, wat erop wijst dat realtime KSL-herkenning praktisch kan zijn, zelfs op alledaagse smartphones zonder constante internetverbinding of dure hardware.
Wat dit betekent voor het dagelijks leven
Simpel gezegd laat dit werk zien dat het mogelijk is een gewone smartphone het vermogen te geven een kernset KSL-woorden uit korte video’s te "begrijpen", betrouwbaar en snel. Door een toegewijde KSL-videodataset te creëren, gebaren te destilleren tot lichaam- en handskeletten en moderne sequentiemodellen te comprimeren zodat ze efficiënt aan de rand kunnen draaien, bieden de onderzoekers een blauwdruk voor toegankelijke gebarenherkenningstechnologie toegespitst op een regionale taal. Hoewel het huidige systeem slechts 33 geïsoleerde woorden afhandelt en nog afhankelijk is van een kleine server voor feature-extractie, is het een concrete stap richting rijkere, volledig on-device hulpmiddelen die honderden duizenden KSL-gebruikers zouden kunnen helpen beter te communiceren met de horende wereld.
Bronvermelding: V, U., K S, N., K S, N. et al. Dynamic Kannada Sign Language Recognition on Resource Constrained Devices. Sci Rep 16, 11186 (2026). https://doi.org/10.1038/s41598-026-40181-7
Trefwoorden: Kannada-gebarentaal, mobiele gebarenherkenning, TinyML, gebaarherkenning, hulpmiddelen technologie