Clear Sky Science · pl
Dynamiczne rozpoznawanie języka migowego kannada na urządzeniach o ograniczonych zasobach
Zmniejszanie bariery w komunikacji
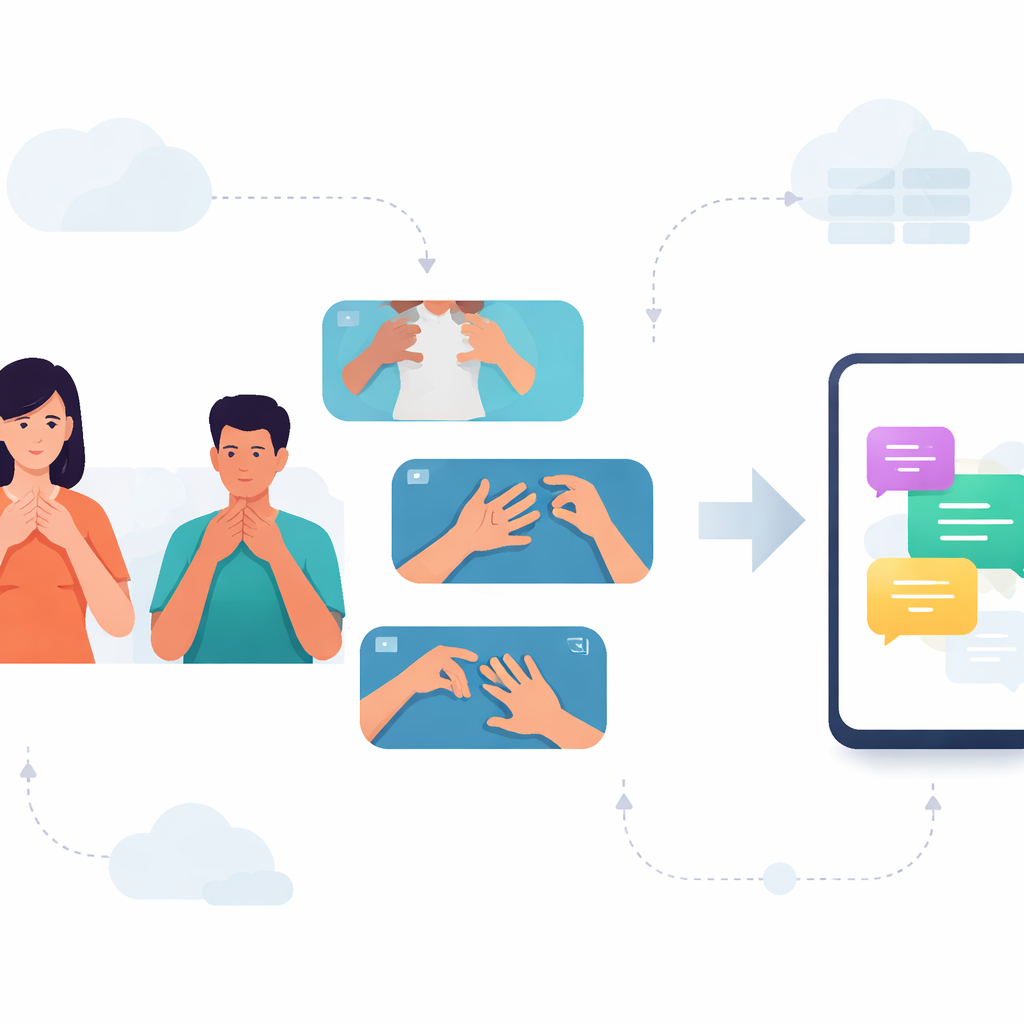
Dla wielu osób Głuchych w Karnatace codzienne rozmowy opierają się na języku migowym kannada (KSL). Tymczasem większość telefonów i aplikacji rozumie jedynie języki mówione i pisane, pozostawiając użytkowników KSL bez cyfrowych narzędzi, które inni uważają za oczywiste. Badanie to wypełnia tę lukę, tworząc system potrafiący odczytywać krótkie znaki KSL z wideo i działać wydajnie na zwykłych smartfonach, otwierając drogę do szybszej i bardziej prywatnej komunikacji między migającymi a niemigającymi.
Budowanie biblioteki znaków w warunkach rzeczywistych
Ponieważ nie istniała publiczna baza wideo z słowami KSL, badacze zaczęli od stworzenia takiej od podstaw. Współpracowali z nauczycielami w szkole dla dzieci Głuchych oraz 38 wolontariuszami z całej Karnataki, nagrywając ponad dwa tysiące wideo ze znakami KSL. Zespół skupił się na 33 codziennych słowach pogrupowanych w cztery tematy: owoce, miesiące, dni tygodnia oraz pory dnia lub pory roku. Każde słowo było filmowane wielokrotnie, z różną prędkością, w różnych miejscach i przy zmiennym oświetleniu. Taka różnorodność pomaga systemowi radzić sobie z chaotycznymi, nieprzewidywalnymi warunkami rzeczywistymi, zamiast działać tylko w idealnym środowisku laboratoryjnym.
Nauczanie komputerów widzenia ruchu
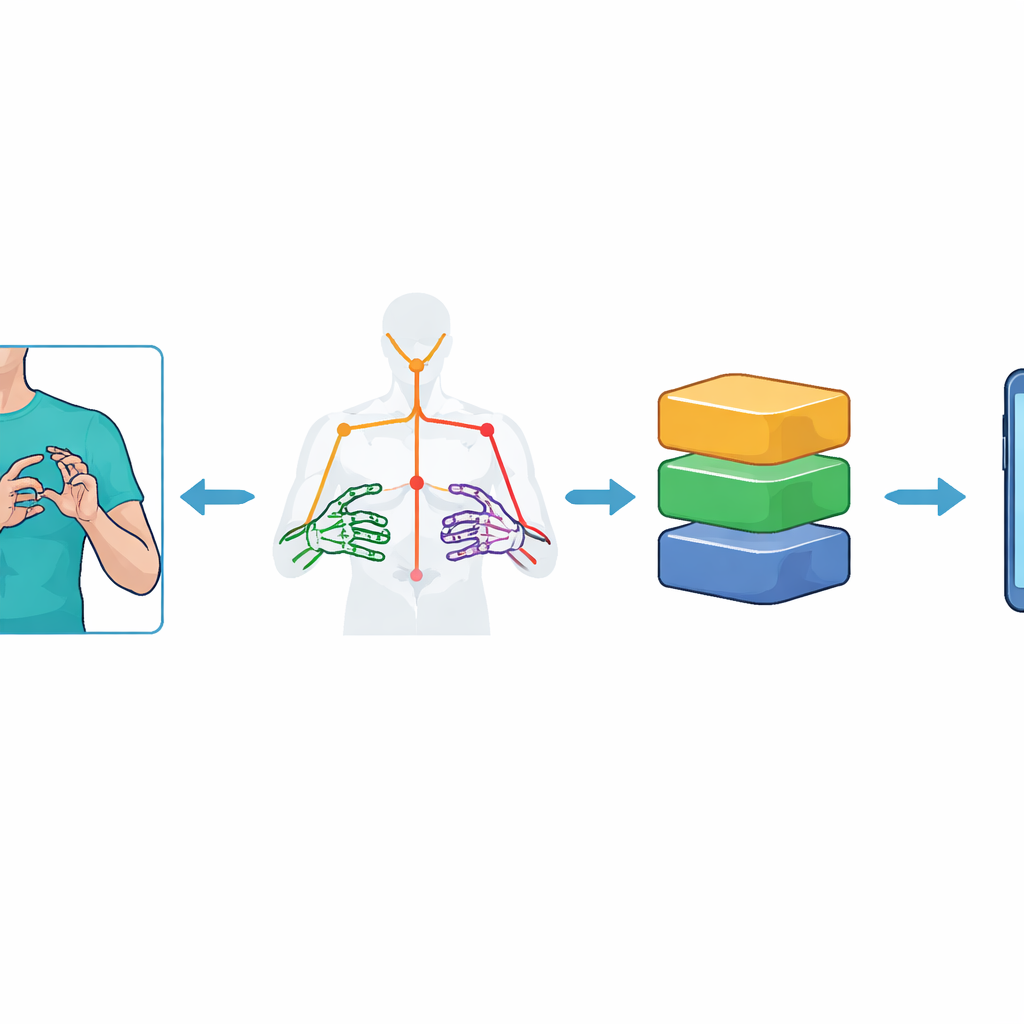
Zamiast podawać pełne obrazy wideo ciężkiemu modelowi wizji, system najpierw redukuje każdą klatkę do zbioru punktów kluczowych reprezentujących górną część ciała i dłonie osoby migającej. Korzystając z narzędzia MediaPipe Holistic firmy Google, badacze śledzą 59 punktów orientacyjnych — takich jak bark, łokieć, nadgarstek i stawy palców — i rejestrują ich trójwymiarowe pozycje w czasie. Powstaje w ten sposób kompaktowy „szkielet” każdej sekwencji gestów: 75 klatek na wideo, z każdą zawierającą 177 cech numerycznych. Aby wzmocnić odporność systemu na szumy, rozszerzają zbiór danych za pomocą starannie dobranych augmentacji wideo, dodając niewielkie przechylenia kamery, zmiany oświetlenia, sztuczne „plamki”, przyspieszenia i zwolnienia ruchu. Te kroki pomagają modelom uczyć się istoty znaku, zamiast zapamiętywać specyficzne tło czy warunki nagrania.
Trzy sposoby odczytu ruchomego znaku
Dzięki tej uproszczonej reprezentacji ruchu zespół porównuje trzy podejścia głębokiego uczenia do rozpoznawania każdego znaku. Pierwsze to LSTM — sieć zaprojektowana do śledzenia sekwencji klatka po klatce, pamiętając istotne szczegóły i zapominając rozpraszające elementy. Drugie, BiLSTM, analizuje gest zarówno od przeszłości do przyszłości, jak i odwrotnie, co daje bogatszy obraz ruchu. Trzecie to enkoderowy Transformer, który bada wszystkie klatki w relacji wzajemnej, używając mechanizmu uwagi: zamiast skanować w ścisłej kolejności, uczy się, które momenty w znaku najbardziej na siebie wpływają. Wszystkie trzy modele otrzymują te same dane podzielone na zestawy treningowy, walidacyjny i testowy i są dostrojone do klasyfikacji 33 słów wyłącznie na podstawie wzorców ruchu.
Zmniejszanie potęgi modeli dla urządzeń Tiny
Modele o wysokiej dokładności często są zbyt duże i wolne dla urządzeń z ograniczonymi zasobami, takich jak telefony średniej klasy. Aby to rozwiązać, autorzy stosują optymalizacje w stylu TinyML z użyciem TensorFlow Lite. Konwertują każdy wytrenowany model na mniejsze wersje poprzez redukcję precyzji numerycznej wag wewnętrznych — proces znany jako kwantyzacja po treningu. Wypróbowano kilka schematów, w tym kwantyzację zakresu dynamicznego, float16 oraz pełno‑całkowitoliczbowe warianty. Tak przycięte modele są następnie osadzane w aplikacji Android opartej na Flutterze. Ponieważ w Flutterze nie ma jeszcze wbudowanego wsparcia do uruchamiania MediaPipe Holistic bezpośrednio na telefonie, lekki serwer zewnętrzny wyodrębnia punkty kluczowe i wysyła do aplikacji jedynie skompresowane dane ruchu, a końcowe rozpoznawanie odbywa się na urządzeniu.
Szybkie, dokładne odczytywanie znaków w twojej dłoni
Mimo że modele zostały uproszczone pod kątem szybkości i rozmiaru, najlepsze utrzymują imponującą wydajność: około 94–96% dokładności testowej na 33 słowach KSL. Dynamicznie kwantyzowany BiLSTM osiąga najwyższą dokładność — 95,71%, podczas gdy skwantyzowany model Transformer oferuje najszybsze predykcje na telefonie — około 16 milisekund na znak — przy rozmiarze modelu nieco ponad 1 MB. LSTM zajmuje środek pomiędzy rozmiarem, szybkością i dokładnością. Wszystkie trzy działają przy umiarkowanym wykorzystaniu CPU i pamięci, co sugeruje, że rozpoznawanie KSL w czasie rzeczywistym jest praktyczne nawet na codziennych smartfonach bez stałego dostępu do internetu czy drogiego sprzętu.
Co to oznacza dla codziennego życia
Mówiąc prosto, praca ta pokazuje, że możliwe jest wyposażenie zwykłego smartfona w zdolność „rozumienia” podstawowego zestawu słów KSL z krótkich wideo — w sposób niezawodny i szybki. Tworząc dedykowany zbiór wideo KSL, sprowadzając gesty do szkieletów ciała i dłoni oraz kompresując nowoczesne modele sekwencyjne tak, aby działały wydajnie na brzegu sieci, badacze przedstawiają plan budowy dostępnej technologii rozpoznawania znaków dostosowanej do języka regionalnego. Choć obecny system obsługuje tylko 33 izolowane słowa i wciąż polega na małym serwerze do ekstrakcji cech, jest to konkretny krok w stronę bogatszych, w pełni działających na urządzeniu narzędzi, które mogłyby pomóc setkom tysięcy użytkowników KSL w płynniejszej komunikacji ze słyszącym światem.
Cytowanie: V, U., K S, N., K S, N. et al. Dynamic Kannada Sign Language Recognition on Resource Constrained Devices. Sci Rep 16, 11186 (2026). https://doi.org/10.1038/s41598-026-40181-7
Słowa kluczowe: język migowy kannada, mobilne rozpoznawanie mowy migowej, TinyML, rozpoznawanie gestów, technologia wspomagająca