Clear Sky Science · es
Reconocimiento dinámico de la lengua de signos Kannada en dispositivos con recursos limitados
Acortando la brecha en la conversación
Para muchas personas sordas en Karnataka, las conversaciones cotidianas dependen de la Lengua de Signos Kannada (KSL). Sin embargo, la mayoría de los teléfonos y aplicaciones solo entienden idiomas hablados y escritos, dejando a las personas usuarias de KSL sin las herramientas digitales que otros dan por sentadas. Este estudio aborda esa brecha construyendo un sistema capaz de leer signos cortos de KSL a partir de vídeo y que funciona de forma eficiente en teléfonos inteligentes normales, abriendo la puerta a una comunicación más rápida y privada entre signantes y oyentes.
Creación de una biblioteca de signos en el mundo real
Como no existía una base de datos pública de vídeos de palabras en KSL, los investigadores empezaron por crearla desde cero. Trabajaron con docentes de una escuela para niños sordos y 38 voluntarios de todo Karnataka para grabar más de dos mil vídeos de signos KSL. El equipo se centró en 33 palabras de uso diario agrupadas en cuatro temas: frutas, meses, días de la semana y momentos del día o estaciones. Cada palabra se filmó muchas veces, a distintas velocidades, en diferentes ubicaciones y con iluminación variada. Esta variedad ayuda al sistema a manejar las condiciones desordenadas e impredecibles de la vida real en lugar de funcionar solo en un entorno de laboratorio perfecto.
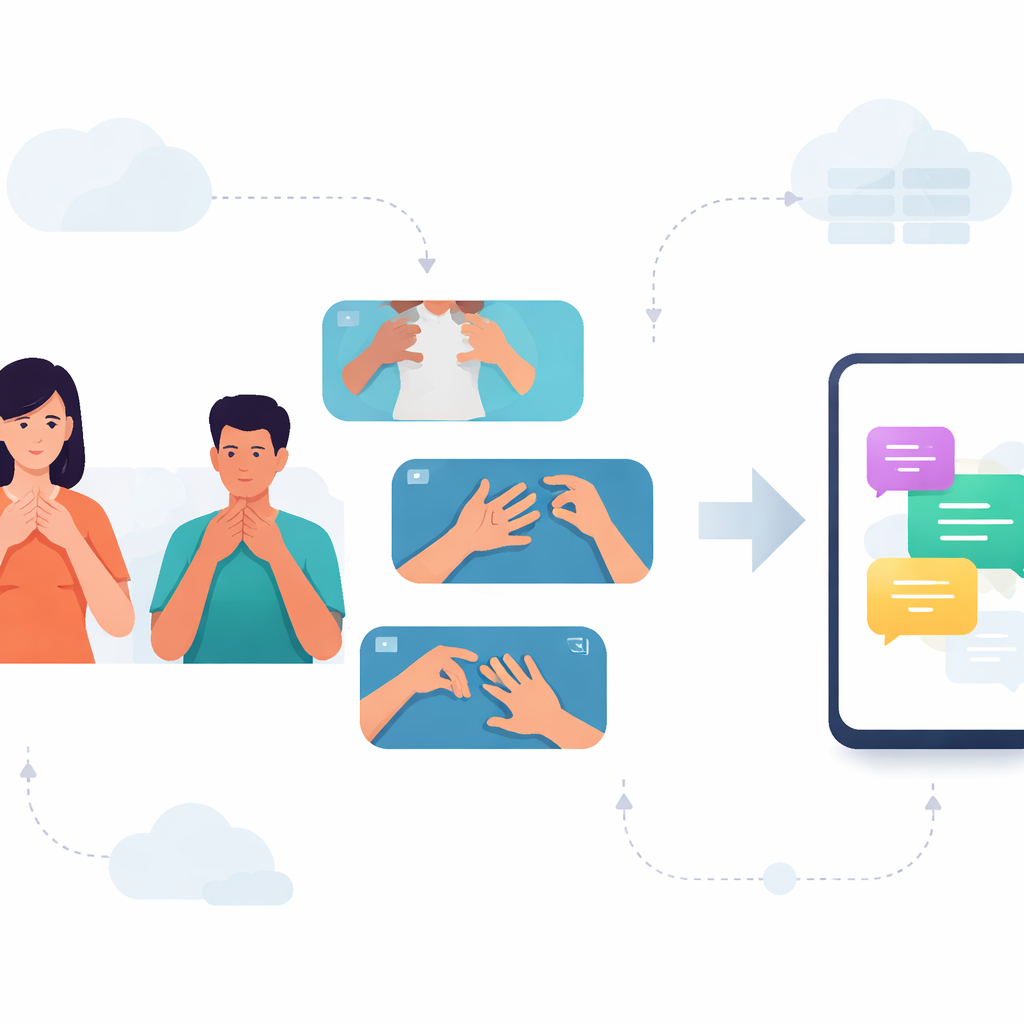
Enseñar a las máquinas a ver el movimiento
En lugar de alimentar imágenes de vídeo completas a un pesado modelo de visión, el sistema primero reduce cada fotograma a un conjunto de puntos clave que representan la parte superior del cuerpo y las manos del signante. Utilizando la herramienta MediaPipe Holistic de Google, los investigadores rastrean 59 marcas —como hombro, codo, muñeca y articulaciones de los dedos— y registran sus posiciones 3D a lo largo del tiempo. Esto produce un «esqueleto» compacto de cada secuencia de gestos: 75 fotogramas por vídeo, cada uno con 177 características numéricas. Para robustecer el sistema frente al ruido, amplían el conjunto de datos con aumentos cuidadosos de los vídeos, añadiendo pequeñas inclinaciones de cámara, cambios de iluminación, motas artificiales y variaciones de velocidad. Estos pasos ayudan a los modelos a aprender la esencia de un signo en lugar de memorizar un fondo o condición de grabación específicos.
Tres maneras de interpretar un signo en movimiento
Con esta representación más limpia del movimiento, el equipo compara tres enfoques de aprendizaje profundo para reconocer cada palabra signada. El primero es un LSTM, una red diseñada para seguir secuencias fotograma a fotograma, recordando detalles importantes y olvidando distracciones. El segundo, un BiLSTM, observa el gesto tanto de pasado a futuro como de futuro a pasado, lo que le proporciona una visión más rica del movimiento. El tercero es un Transformer solo con codificador, que examina todos los fotogramas en relación unos con otros mediante un mecanismo de atención: en lugar de escanear en un orden estricto, aprende qué momentos del signo dependen más entre sí. Los tres modelos ven los mismos datos divididos en conjuntos de entrenamiento, validación y prueba, y se ajustan para clasificar las 33 palabras únicamente a partir de los patrones de movimiento.
Reducir modelos potentes para dispositivos diminutos
Los modelos de alta precisión suelen ser demasiado grandes y lentos para dispositivos con recursos limitados, como teléfonos de gama media. Para resolver esto, los autores aplican optimizaciones al estilo TinyML usando TensorFlow Lite. Convierten cada modelo entrenado en versiones más pequeñas reduciendo la precisión numérica de los pesos internos —un proceso conocido como cuantización post-entrenamiento. Se prueban varios esquemas, incluidos rango dinámico, float16 y variantes de entero completo. Estos modelos recortados se integran luego en una aplicación Android basada en Flutter. Dado que aún no hay soporte incorporado para ejecutar MediaPipe Holistic directamente en el teléfono dentro de Flutter, un servidor externo ligero extrae los puntos clave y envía solo los datos de movimiento compactos a la aplicación, que realiza el reconocimiento final en el dispositivo.
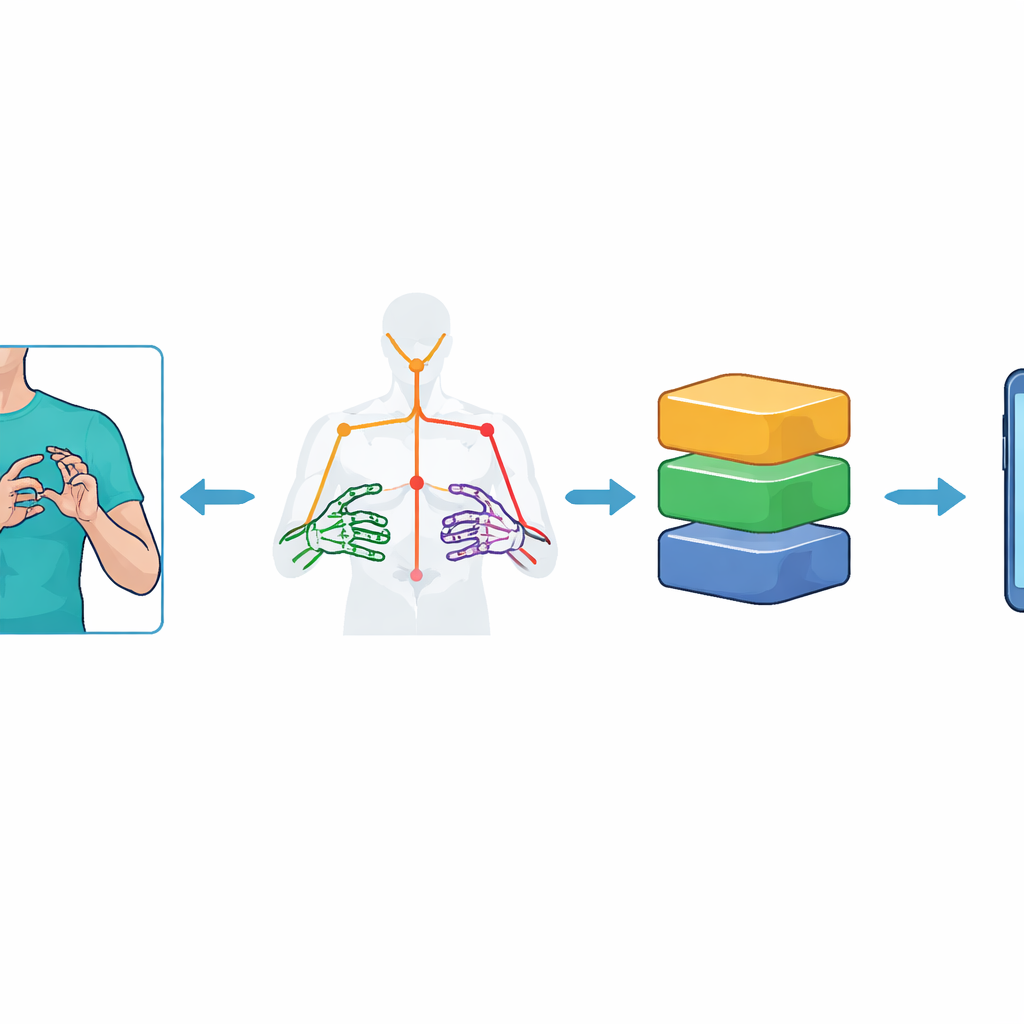
Lectura de signos rápida y precisa en la palma de la mano
Aunque están simplificados para velocidad y tamaño, los mejores modelos mantienen un rendimiento impresionante: alrededor de 94–96 % de precisión en prueba sobre las 33 palabras de KSL. El BiLSTM con cuantización dinámica alcanza la mayor precisión con un 95,71 %, mientras que el modelo Transformer cuantizado ofrece las predicciones más rápidas en el teléfono —unos 16 milisegundos por signo— con un tamaño de modelo de poco más de 1 MB. El LSTM ocupa un punto intermedio entre tamaño, velocidad y precisión. Los tres funcionan con un uso moderado de CPU y memoria, lo que sugiere que el reconocimiento de KSL en tiempo real puede ser práctico incluso en teléfonos cotidianos sin necesidad de conexión constante a Internet o hardware caro.
Qué significa esto para la vida cotidiana
En términos prácticos, este trabajo demuestra que es posible dotar a un smartphone común de la capacidad de «entender» un conjunto básico de palabras de KSL a partir de vídeos cortos, de forma fiable y rápida. Al crear un conjunto de datos de vídeo dedicado a KSL, destilar los gestos hasta esqueletos de cuerpo y manos, y comprimir modelos de secuencia modernos para que funcionen eficientemente en el borde, los investigadores proporcionan una hoja de ruta para una tecnología de reconocimiento de signos accesible y adaptada a una lengua regional. Aunque el sistema actual solo maneja 33 palabras aisladas y todavía depende de un pequeño servidor para la extracción de características, representa un paso concreto hacia herramientas más ricas y totalmente en dispositivo que podrían ayudar a cientos de miles de usuarios de KSL a comunicarse con mayor fluidez con el mundo oyente.
Cita: V, U., K S, N., K S, N. et al. Dynamic Kannada Sign Language Recognition on Resource Constrained Devices. Sci Rep 16, 11186 (2026). https://doi.org/10.1038/s41598-026-40181-7
Palabras clave: lengua de signos Kannada, reconocimiento de signos móvil, TinyML, reconocimiento de gestos, tecnología asistencial