Clear Sky Science · fr
Reconnaissance dynamique de la langue des signes kannada sur appareils à ressources limitées
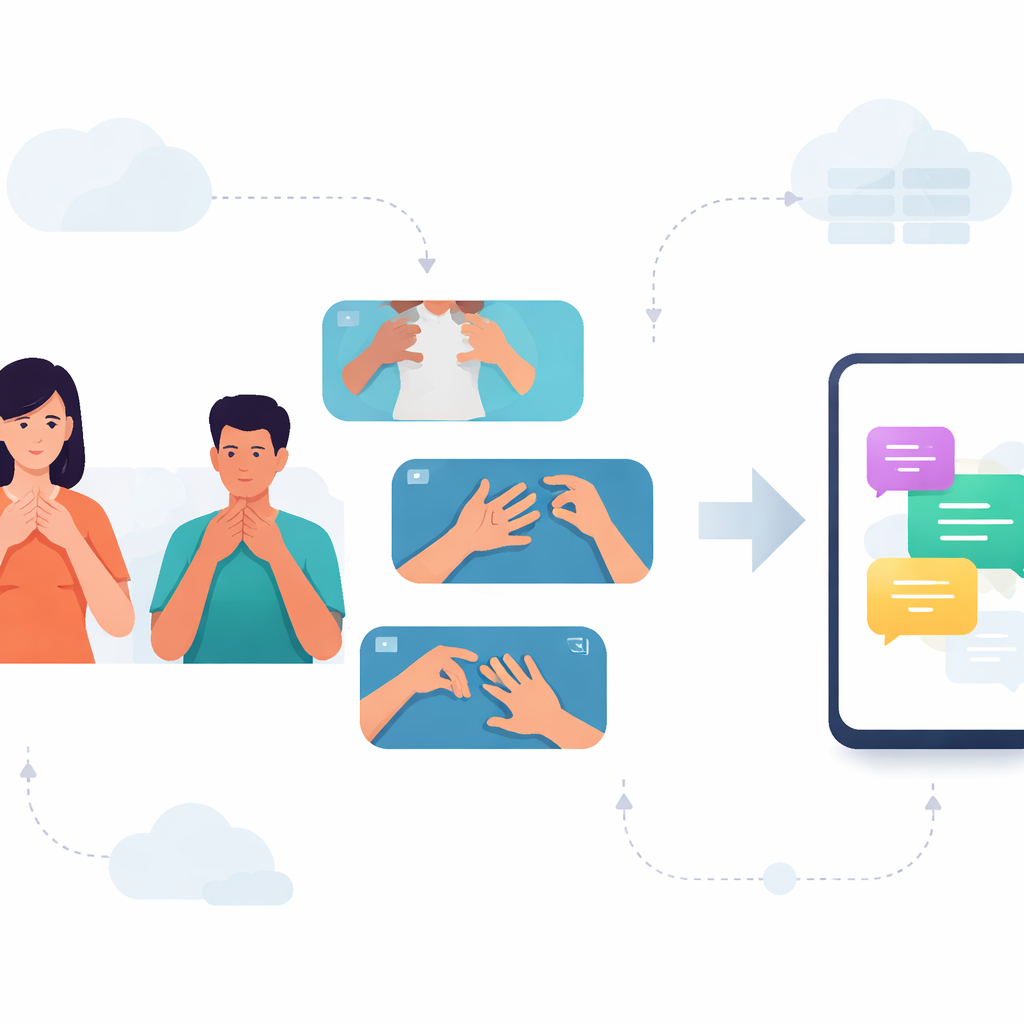
Combler le fossé de la conversation
Pour de nombreuses personnes sourdes au Karnataka, les conversations quotidiennes reposent sur la langue des signes kannada (KSL). Pourtant, la plupart des téléphones et des applications comprennent uniquement les langues parlées et écrites, laissant les utilisateurs de KSL sans les outils numériques dont d'autres disposent. Cette étude s'attaque à ce manque en construisant un système capable de lire de courts signes KSL à partir de vidéos et de fonctionner efficacement sur des smartphones ordinaires, ouvrant la voie à une communication plus rapide et plus privée entre signeurs et non-signeurs.
Constituer une bibliothèque de signes en conditions réelles
Comme il n'existait aucune base vidéo publique de mots KSL, les chercheurs ont commencé par en créer une de toutes pièces. Ils ont travaillé avec des enseignants d'une école pour enfants sourds et 38 bénévoles venus de tout le Karnataka pour enregistrer plus de deux mille vidéos de signes KSL. L'équipe s'est concentrée sur 33 mots du quotidien regroupés en quatre thèmes : fruits, mois, jours de la semaine et moments de la journée ou saisons. Chaque mot a été filmé plusieurs fois, à des vitesses différentes, dans divers lieux et sous des éclairages variés. Cette diversité aide le système à faire face aux conditions désordonnées et imprévisibles de la vie réelle plutôt qu'à ne fonctionner que dans un laboratoire parfait.
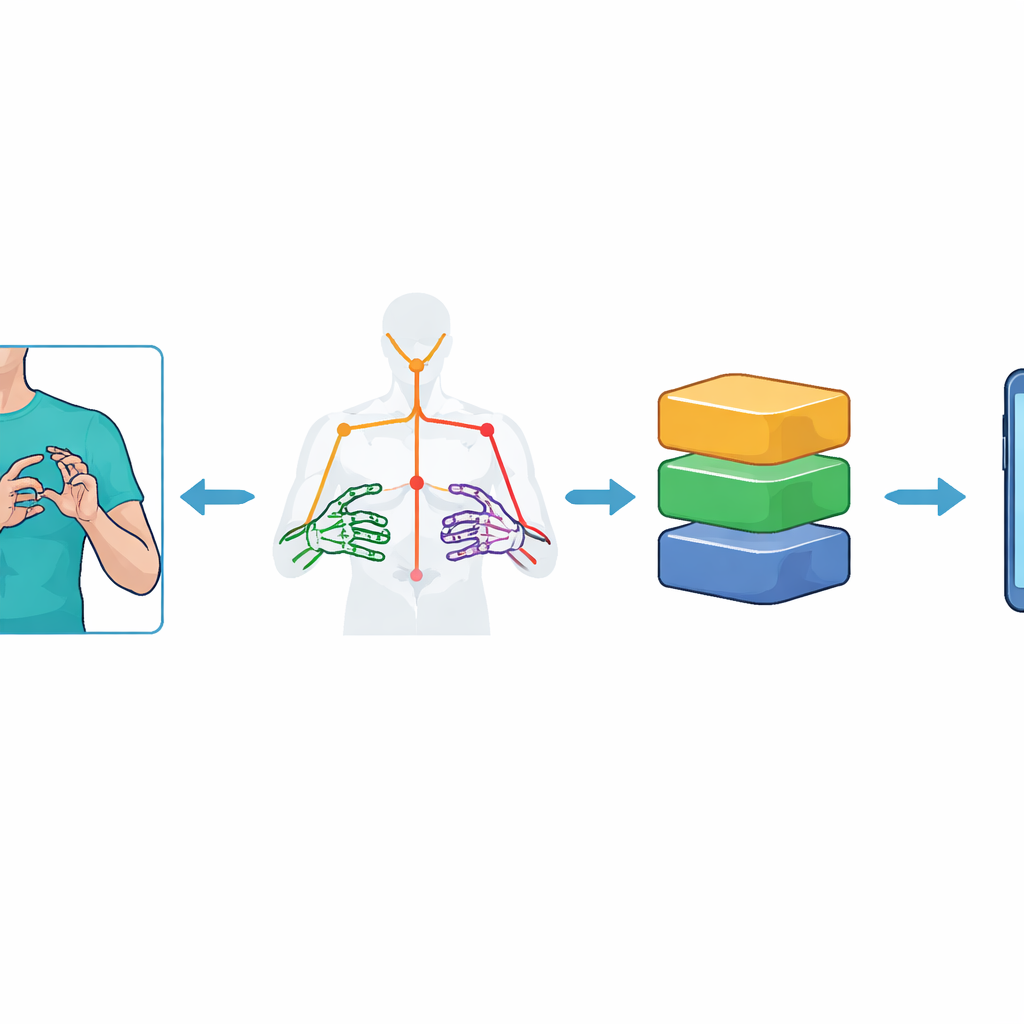
Apprendre aux ordinateurs à voir le mouvement
Au lieu d'alimenter de lourdes images vidéo dans un modèle de vision massif, le système réduit d'abord chaque image à un ensemble de points clés représentant le haut du corps et les mains du signeur. En utilisant l'outil MediaPipe Holistic de Google, les chercheurs suivent 59 repères — tels que épaule, coude, poignet et articulations des doigts — et enregistrent leurs positions 3D dans le temps. Cela produit un « squelette » compact de chaque séquence de geste : 75 images par vidéo, chacune avec 177 caractéristiques numériques. Pour renforcer le système contre le bruit, ils élargissent le jeu de données par des augmentations vidéo soigneuses, ajoutant de légers inclinaisons de caméra, des changements d'éclairage, des taches artificielles, des accélérations et ralentissements du mouvement. Ces étapes aident les modèles à apprendre l'essence d'un signe plutôt qu'à mémoriser un arrière-plan ou des conditions d'enregistrement spécifiques.
Trois manières de lire un signe en mouvement
Avec cette représentation du mouvement plus épurée, l'équipe compare trois approches d'apprentissage profond pour reconnaître chaque mot signé. La première est une LSTM, un réseau conçu pour suivre des séquences image par image, retenant les détails importants tout en oubliant les distractions. La seconde, une BiLSTM, examine le geste du passé vers le futur et du futur vers le passé, lui offrant une vision plus riche du mouvement. La troisième est un Transformer en encodage seul, qui examine toutes les images en relation les unes avec les autres grâce à un mécanisme d'attention : au lieu de parcourir strictement dans l'ordre, il apprend quels instants du signe dépendent le plus les uns des autres. Les trois modèles utilisent les mêmes données réparties en ensembles d'entraînement, de validation et de test, et sont ajustés pour classer les 33 mots à partir des seuls schémas de mouvement.
Réduire des modèles puissants pour de petits appareils
Les modèles à haute précision sont souvent trop volumineux et lents pour des appareils aux ressources limitées comme des téléphones milieu de gamme. Pour résoudre ce problème, les auteurs appliquent des optimisations de type TinyML en utilisant TensorFlow Lite. Ils convertissent chaque modèle entraîné en versions plus petites en réduisant la précision numérique des poids internes — un processus connu sous le nom de quantification post-entraînement. Plusieurs schémas sont testés, dont la plage dynamique, le float16 et des variantes entières complètes. Ces modèles allégés sont ensuite intégrés dans une application Android basée sur Flutter. Parce qu'il n'existe pas encore de prise en charge directe pour exécuter MediaPipe Holistic sur le téléphone depuis Flutter, un serveur externe léger extrait les points clés et renvoie uniquement les données de mouvement compactes à l'application, qui effectue la reconnaissance finale sur l'appareil.
Lecture de signes rapide et précise dans votre main
Malgré leur réduction en vitesse et en taille, les meilleurs modèles conservent des performances impressionnantes : environ 94–96 % de précision au test sur les 33 mots KSL. La BiLSTM quantifiée dynamiquement atteint la plus haute précision à 95,71 %, tandis que le modèle Transformer quantifié offre les prédictions les plus rapides sur téléphone — environ 16 millisecondes par signe — avec une taille de modèle juste supérieure à 1 Mo. L'LSTM trouve un compromis entre taille, vitesse et précision. Les trois s'exécutent avec une utilisation modeste du CPU et de la mémoire, ce qui suggère que la reconnaissance KSL en temps réel peut être pratique même sur des smartphones courants sans accès Internet permanent ni matériel coûteux.
Ce que cela signifie pour la vie quotidienne
En termes simples, ce travail montre qu'il est possible de donner à un smartphone ordinaire la capacité de « comprendre » un ensemble de base de mots KSL à partir de courtes vidéos, de manière fiable et rapide. En créant un jeu de données vidéo dédié au KSL, en distillant les gestes en squelettes du corps et des mains, et en compressant des modèles de séquence modernes pour qu'ils s'exécutent efficacement en périphérie, les chercheurs fournissent une feuille de route pour une technologie de reconnaissance des signes accessible et adaptée à une langue régionale. Bien que le système actuel ne traite que 33 mots isolés et dépende encore d'un petit serveur pour l'extraction des caractéristiques, il représente une avancée concrète vers des outils plus riches, entièrement sur l'appareil, qui pourraient aider des centaines de milliers d'utilisateurs de KSL à communiquer plus facilement avec le monde entendant.
Citation: V, U., K S, N., K S, N. et al. Dynamic Kannada Sign Language Recognition on Resource Constrained Devices. Sci Rep 16, 11186 (2026). https://doi.org/10.1038/s41598-026-40181-7
Mots-clés: langue des signes kannada, reconnaissance de signes mobile, TinyML, reconnaissance de gestes, technologie d'assistance