Clear Sky Science · it
Riconoscimento dinamico della lingua dei segni kannada su dispositivi con risorse limitate
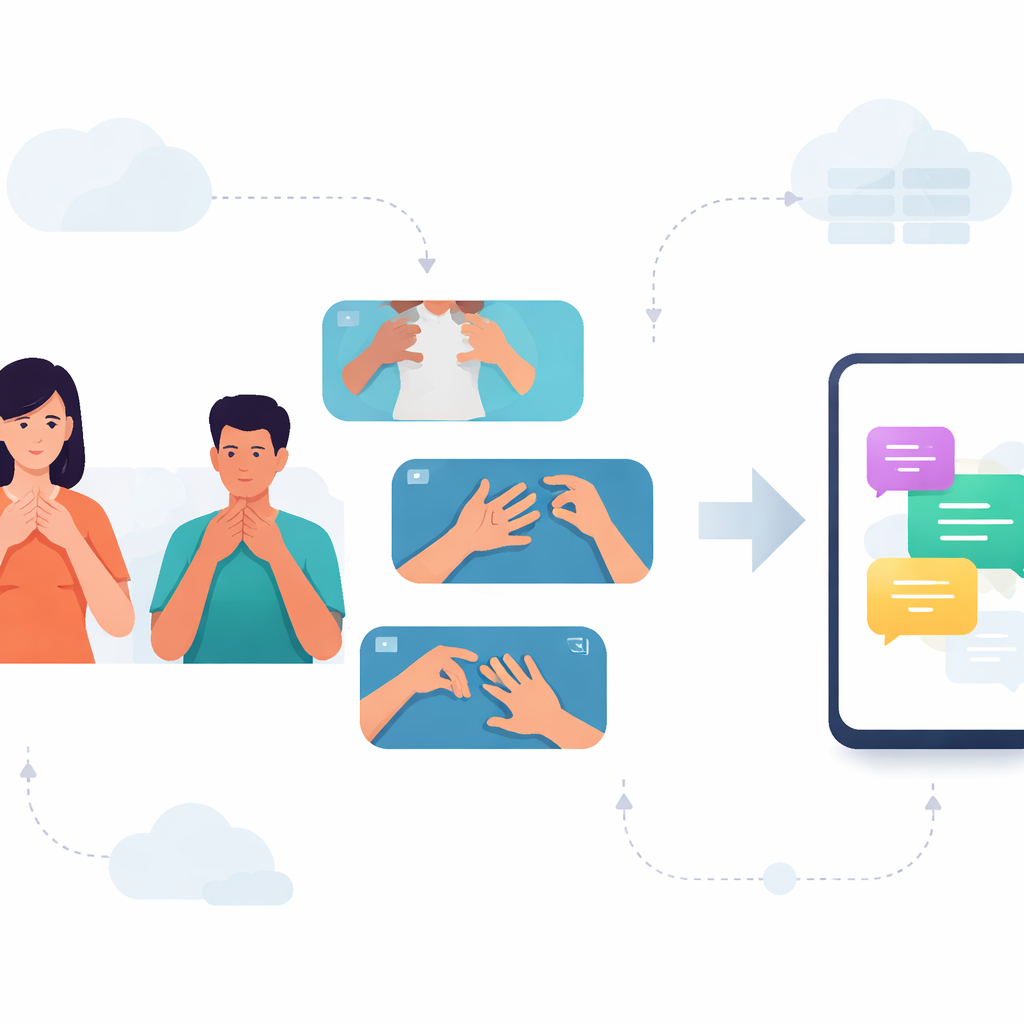
Colmare il divario comunicativo
Per molte persone sorde in Karnataka, le conversazioni quotidiane dipendono dalla lingua dei segni kannada (KSL). Eppure la maggior parte dei telefoni e delle app comprende solo lingue parlate e scritte, lasciando gli utenti KSL senza gli strumenti digitali che gli altri danno per scontati. Questo studio affronta quella lacuna costruendo un sistema in grado di leggere brevi segni KSL dai video e di funzionare in modo efficiente su smartphone comuni, aprendo la strada a comunicazioni più rapide e più private tra chi usa i segni e chi non li conosce.
Creare una libreria di segni reale
Poiché non esisteva un database video pubblico di parole KSL, i ricercatori hanno iniziato creandone uno da zero. Hanno collaborato con insegnanti di una scuola per bambini sordi e 38 volontari provenienti da tutto il Karnataka per registrare più di duemila video di segni KSL. Il team si è concentrato su 33 parole quotidiane raggruppate in quattro temi: frutta, mesi, giorni della settimana e momenti del giorno o stagioni. Ogni parola è stata filmata molte volte, a velocità diverse, in luoghi differenti e con illuminazioni variabili. Questa varietà aiuta il sistema a far fronte alle condizioni reali, disordinate e imprevedibili, invece di funzionare solo in un ambiente di laboratorio perfetto.
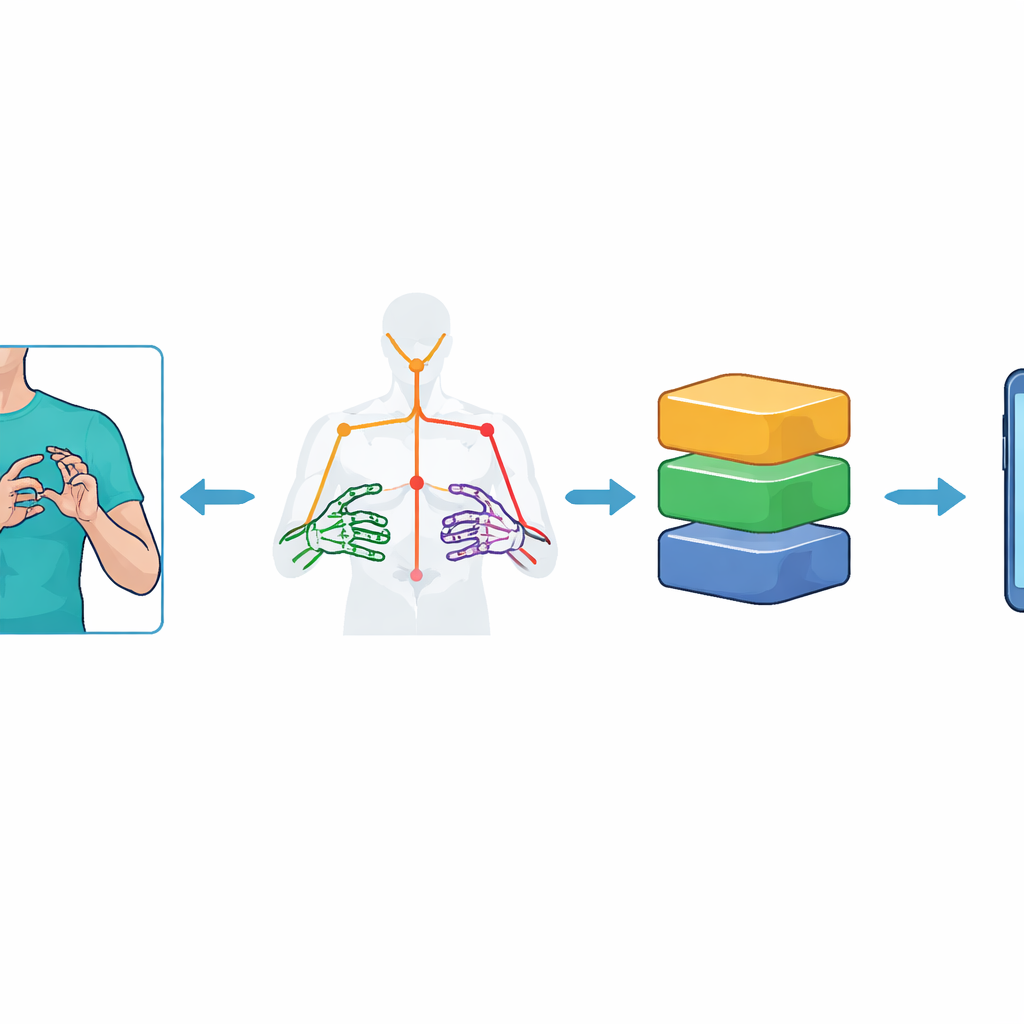
Insegnare ai computer a vedere il movimento
Invece di fornire al modello visivo immagini video complete e pesanti, il sistema riduce prima ogni fotogramma a un insieme di punti chiave che rappresentano la parte superiore del corpo e le mani del segnante. Utilizzando il toolkit MediaPipe Holistic di Google, i ricercatori tracciano 59 punti di riferimento — come spalla, gomito, polso e articolazioni delle dita — e registrano le loro posizioni 3D nel tempo. Questo produce uno “scheletro” compatto di ogni sequenza di gesto: 75 fotogrammi per video, ciascuno con 177 caratteristiche numeriche. Per rendere il sistema più robusto al rumore, ampliano il dataset con accurate aumentazioni video, aggiungendo piccoli inclinamenti della camera, variazioni di illuminazione, puntini artificiali, accelerazioni e rallentamenti del movimento. Questi passaggi aiutano i modelli a imparare l’essenza di un segno anziché memorizzare uno sfondo o una condizione di registrazione specifica.
Tre modi per leggere un segno in movimento
Con questa rappresentazione più pulita del movimento, il team confronta tre approcci di deep learning per riconoscere ogni parola firmata. Il primo è una LSTM, una rete progettata per seguire sequenze fotogramma per fotogramma, ricordando dettagli importanti e dimenticando distrazioni. Il secondo, una BiLSTM, osserva il gesto sia dal passato verso il futuro sia dal futuro verso il passato, offrendo una visione più ricca del movimento. Il terzo è un Transformer solo encoder, che esamina tutti i fotogrammi in relazione l’uno con l’altro tramite un meccanismo di attenzione: invece di scansionare in ordine rigoroso, impara quali momenti del segno dipendono maggiormente l’uno dall’altro. Tutti e tre i modelli vedono gli stessi dati suddivisi in set di addestramento, validazione e test, e sono ottimizzati per classificare le 33 parole a partire solo dai pattern di movimento.
Ridurre modelli potenti per dispositivi Tiny
I modelli ad alta accuratezza sono spesso troppo grandi e lenti per dispositivi con risorse limitate come telefoni di fascia media. Per risolvere questo problema, gli autori applicano ottimizzazioni in stile TinyML usando TensorFlow Lite. Convertono ogni modello addestrato in versioni più piccole riducendo la precisione numerica dei pesi interni — un processo noto come quantizzazione post-addestramento. Sono provati diversi schemi, inclusi dynamic range, float16 e varianti a intero completo. Questi modelli alleggeriti vengono poi integrati in un’app Android basata su Flutter. Dal momento che non esiste ancora supporto integrato per eseguire MediaPipe Holistic direttamente sul telefono all’interno di Flutter, un server esterno e leggero estrae i punti chiave e invia all’app solo i dati di movimento compatti, che esegue il riconoscimento finale on-device.
Lettura dei segni rapida e accurata nella tua mano
Nonostante la riduzione per velocità e dimensione, i migliori modelli mantengono prestazioni impressionanti: circa 94–96% di accuratezza nel test sulle 33 parole KSL. La BiLSTM quantizzata dinamicamente raggiunge la massima accuratezza al 95,71%, mentre il modello Transformer quantizzato offre le predizioni più veloci sul telefono — circa 16 millisecondi per segno — con una dimensione del modello poco superiore a 1 MB. La LSTM trova un compromesso tra dimensione, velocità e accuratezza. Tutti e tre funzionano con un uso modesto di CPU e memoria, suggerendo che il riconoscimento KSL in tempo reale può essere praticabile anche su smartphone di uso quotidiano senza accesso costante a Internet o hardware costoso.
Cosa significa per la vita quotidiana
In termini semplici, questo lavoro dimostra che è possibile dotare uno smartphone comune della capacità di “capire” un insieme di parole core della KSL a partire da brevi video, in modo affidabile e rapido. Creando un dataset video dedicato alla KSL, distillando i gesti in scheletri di corpo e mani e comprimendo modelli di sequenza moderni per funzionare efficacemente al bordo, i ricercatori forniscono un modello per una tecnologia di riconoscimento dei segni accessibile e adattata a una lingua regionale. Pur gestendo attualmente solo 33 parole isolate e facendo ancora leva su un piccolo server per l’estrazione delle feature, rappresenta un passo concreto verso strumenti più ricchi e completamente on-device che potrebbero aiutare centinaia di migliaia di utenti KSL a comunicare più agevolmente con il mondo udente.
Citazione: V, U., K S, N., K S, N. et al. Dynamic Kannada Sign Language Recognition on Resource Constrained Devices. Sci Rep 16, 11186 (2026). https://doi.org/10.1038/s41598-026-40181-7
Parole chiave: lingua dei segni kannada, riconoscimento dei segni mobile, TinyML, riconoscimento dei gesti, tecnologia assistiva