Clear Sky Science · pt
Reconhecimento Dinâmico da Língua de Sinais Kannada em Dispositivos com Recursos Limitados
Fechando a Lacuna na Conversa
Para muitas pessoas surdas em Karnataka, as conversas cotidianas dependem da Língua de Sinais Kannada (KSL). Ainda assim, a maioria dos telefones e aplicativos só entende línguas faladas e escritas, deixando os usuários de KSL sem as ferramentas digitais que outros consideram óbvias. Este estudo enfrenta essa lacuna construindo um sistema capaz de ler sinais curtos de KSL a partir de vídeo e rodar de forma eficiente em smartphones comuns, abrindo caminho para uma comunicação mais rápida e privada entre sinalizadores e ouvintes.
Construindo uma Biblioteca de Sinais do Mundo Real
Como não existia um banco de vídeos público de palavras em KSL, os pesquisadores começaram criando um do zero. Trabalharam com professores de uma escola para crianças surdas e com 38 voluntários de toda Karnataka para gravar mais de dois mil vídeos de sinais em KSL. A equipe concentrou-se em 33 palavras do dia a dia agrupadas em quatro temas: frutas, meses, dias da semana e momentos do dia ou estações. Cada palavra foi filmada muitas vezes, em velocidades diferentes, em locais distintos e sob iluminação variada. Essa variedade ajuda o sistema a lidar com as condições imprevisíveis e desordenadas da vida real, em vez de funcionar apenas em um ambiente perfeito de laboratório.
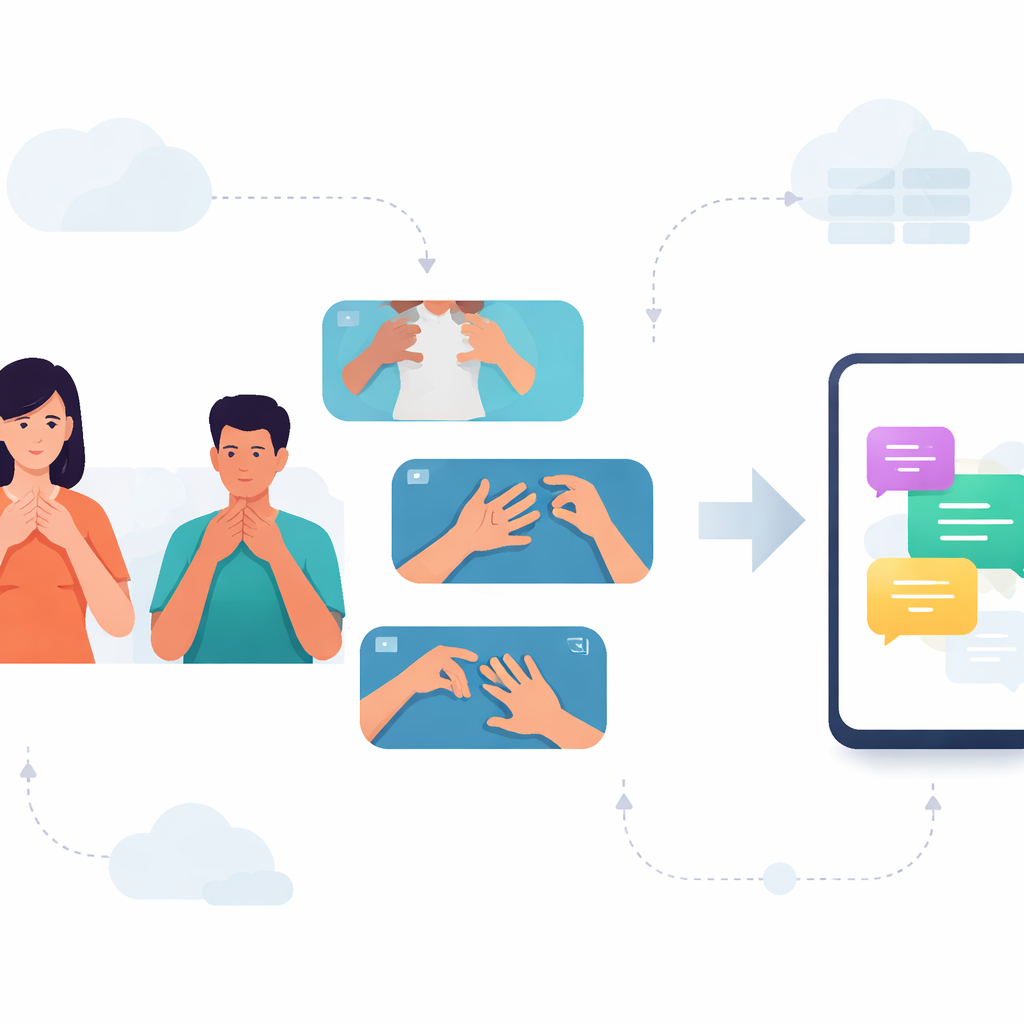
Ensinando Computadores a Ver Movimento
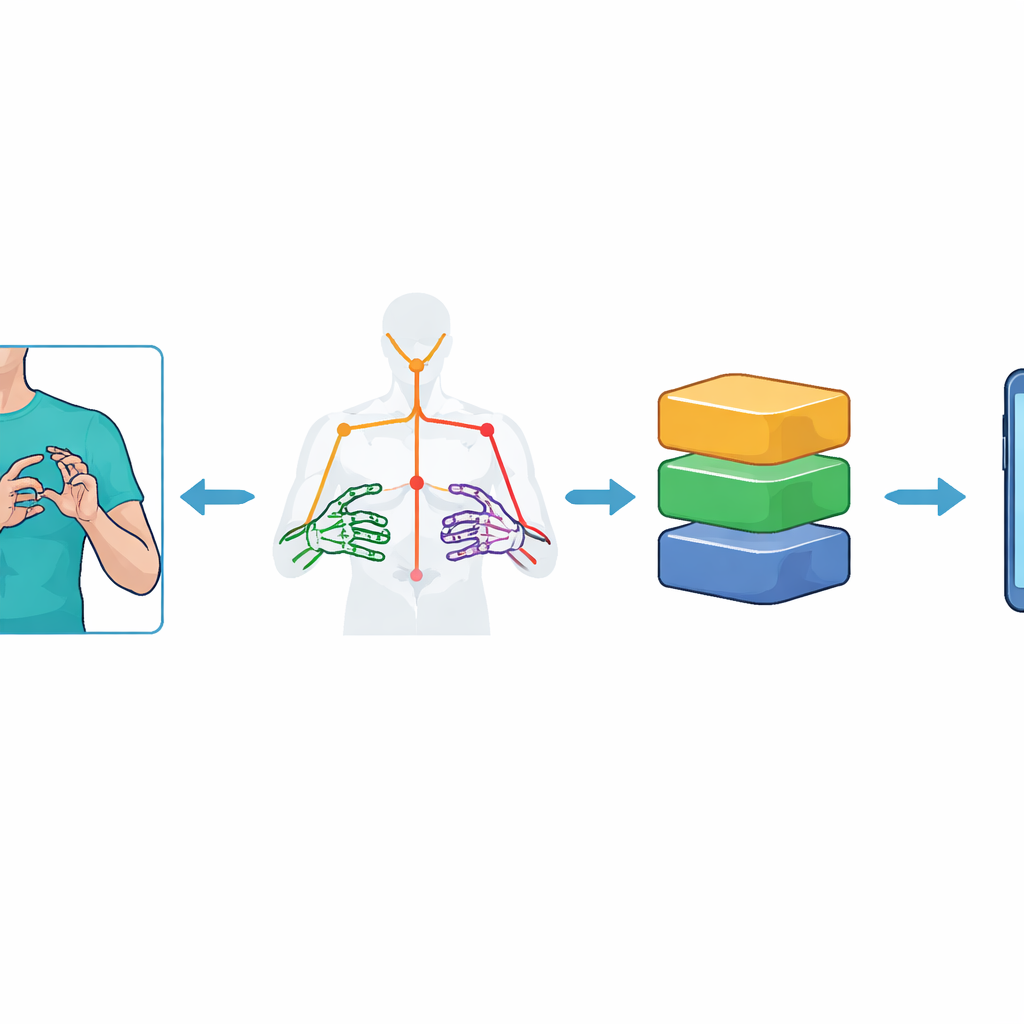
Em vez de alimentar imagens de vídeo completas em um modelo de visão pesado, o sistema reduz primeiro cada quadro a um conjunto de pontos-chave que representam a parte superior do corpo e as mãos do sinalizador. Usando o kit de ferramentas MediaPipe Holistic do Google, os pesquisadores rastreiam 59 marcos — como ombro, cotovelo, pulso e articulações dos dedos — e registram suas posições 3D ao longo do tempo. Isso produz um “esqueleto” compacto de cada sequência de gestos: 75 quadros por vídeo, cada um com 177 características numéricas. Para fortalecer o sistema contra ruído, eles ampliam o conjunto de dados com cuidadosas ampliações de vídeo, adicionando pequenas inclinações de câmera, mudanças de iluminação, pontos artificiais, aceleração e desaceleração de movimento. Essas etapas ajudam os modelos a aprender a essência de um sinal, em vez de memorizar um fundo ou condição de gravação específicos.
Três Maneiras de Ler um Sinal em Movimento
Com essa representação mais enxuta do movimento, a equipe compara três abordagens de deep learning para reconhecer cada palavra sinalizada. A primeira é uma LSTM, uma rede projetada para acompanhar sequências quadro a quadro, lembrando detalhes importantes enquanto esquece distrações. A segunda, uma BiLSTM, observa o gesto tanto do passado para o futuro quanto do futuro para o passado, oferecendo uma visão mais rica do movimento. A terceira é um Transformer apenas com encoder, que examina todos os quadros em relação uns aos outros usando um mecanismo de atenção: em vez de varrer em ordem estrita, ele aprende quais momentos do sinal dependem mais entre si. Todos os três modelos utilizam os mesmos dados divididos em conjuntos de treinamento, validação e teste, e são ajustados para classificar as 33 palavras apenas a partir dos padrões de movimento.
Encolhendo Modelos Potentes para Dispositivos Pequenos
Modelos de alta precisão costumam ser grandes e lentos demais para dispositivos com recursos limitados, como celulares de gama média. Para resolver isso, os autores aplicam otimizações no estilo TinyML usando TensorFlow Lite. Eles convertem cada modelo treinado em versões menores reduzindo a precisão numérica dos pesos internos — um processo conhecido como quantização pós-treinamento. Vários esquemas são testados, incluindo alcance dinâmico, float16 e variantes inteiras completas. Esses modelos enxutos são então incorporados em um aplicativo Android baseado em Flutter. Como ainda não há suporte nativo para rodar o MediaPipe Holistic diretamente no telefone dentro do Flutter, um servidor externo leve extrai os keypoints e envia apenas os dados de movimento compactos de volta ao app, que realiza o reconhecimento final no dispositivo.
Leitura de Sinais Rápida e Precisa na Palma da Mão
Apesar de reduzidos para ganho de velocidade e tamanho, os melhores modelos mantêm desempenho impressionante: cerca de 94–96% de acurácia no teste para as 33 palavras de KSL. A BiLSTM quantizada dinamicamente atinge a maior acurácia, com 95,71%, enquanto o modelo Transformer quantizado oferece as previsões mais rápidas no telefone — cerca de 16 milissegundos por sinal — com um tamanho de modelo pouco acima de 1 MB. A LSTM oferece um meio-termo entre tamanho, velocidade e acurácia. Os três rodam com uso moderado de CPU e memória, sugerindo que o reconhecimento em tempo real de KSL pode ser prático mesmo em smartphones comuns, sem acesso constante à internet ou hardware caro.
O Que Isso Significa para o Dia a Dia
Em termos simples, este trabalho mostra que é possível dar a um smartphone comum a capacidade de “entender” um conjunto central de palavras em KSL a partir de vídeos curtos, de forma confiável e rápida. Ao criar um conjunto de dados de vídeos dedicado ao KSL, destilar gestos em esqueletos de corpo e mão, e comprimir modelos de sequência modernos para rodar eficientemente na borda, os pesquisadores fornecem um roteiro para tecnologia de reconhecimento de sinais acessível e adaptada a uma língua regional. Embora o sistema atual trate apenas 33 palavras isoladas e ainda dependa de um pequeno servidor para extração de características, ele marca um passo concreto rumo a ferramentas mais ricas e totalmente no dispositivo que podem ajudar centenas de milhares de usuários de KSL a se comunicar com mais fluidez com o mundo ouvinte.
Citação: V, U., K S, N., K S, N. et al. Dynamic Kannada Sign Language Recognition on Resource Constrained Devices. Sci Rep 16, 11186 (2026). https://doi.org/10.1038/s41598-026-40181-7
Palavras-chave: Língua de Sinais Kannada, reconhecimento de sinais móvel, TinyML, reconhecimento de gestos, tecnologia assistiva