Clear Sky Science · ru
Распознавание динамического каннада-жеста на устройствах с ограниченными ресурсами
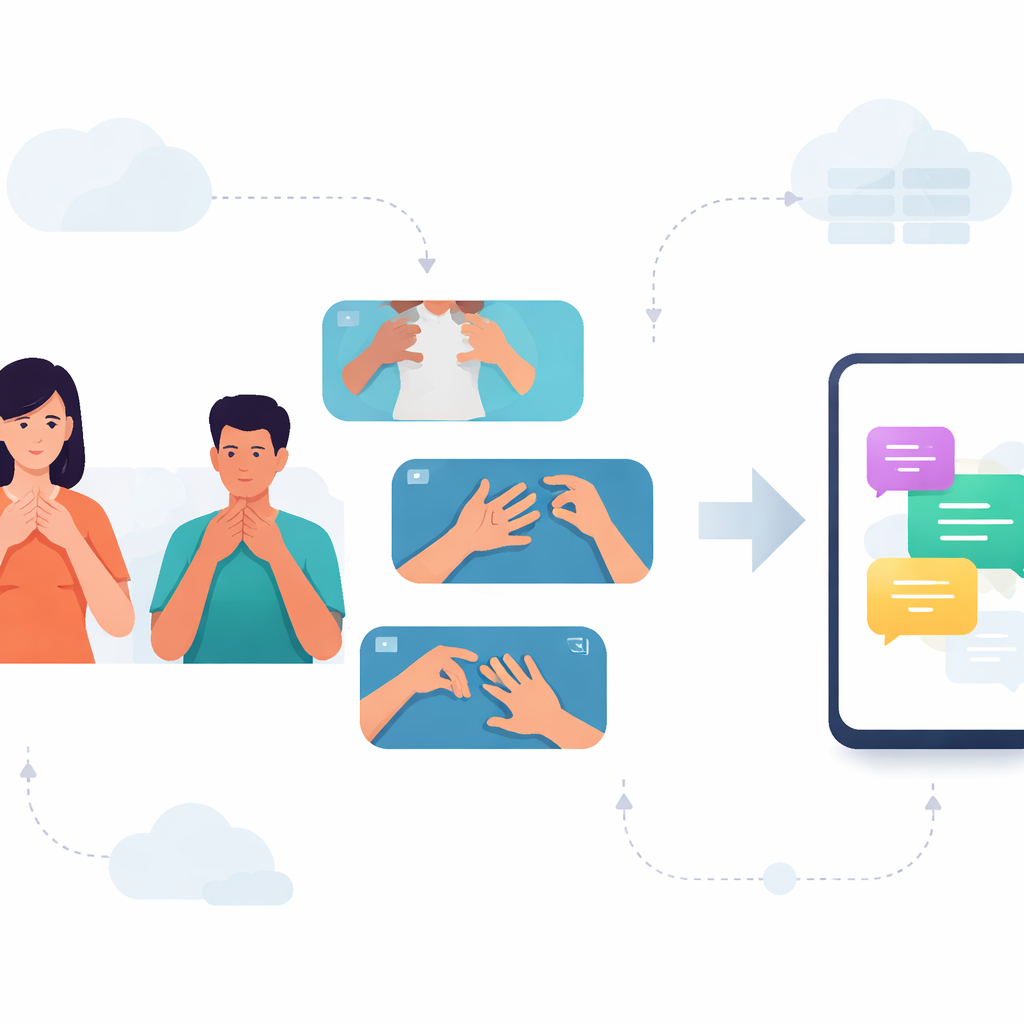
Преодоление барьера в общении
Для многих глухих людей в Карнатаке повседневные разговоры зависят от каннада-жестового языка (KSL). Однако большинство телефонов и приложений понимают только устные и письменные языки, оставляя пользователей KSL без тех цифровых инструментов, которыми пользуются другие. В этом исследовании решается эта проблема: создают систему, способную распознавать короткие знаки KSL по видео и эффективно работать на обычных смартфонах, что открывает путь к более быстрому и приватному общению между жестующими и слышащими.
Создание библиотеки жестов для реального мира
Поскольку публичной видеобазы слов KSL не существовало, исследователи начали с нуля. Они сотрудничали с учителями в школе для глухих детей и 38 волонтёрами со всей Карнатаки, записав более двух тысяч видео жестов KSL. Команда сосредоточилась на 33 повседневных словах, сгруппированных по четырём темам: фрукты, месяцы, дни недели и времена дня или сезоны. Каждое слово снимали многократно, в разном темпе, в разных местах и при различном освещении. Такое разнообразие помогает системе справляться с неидеальными, непредсказуемыми условиями реальной жизни, а не только в лабораторных условиях.
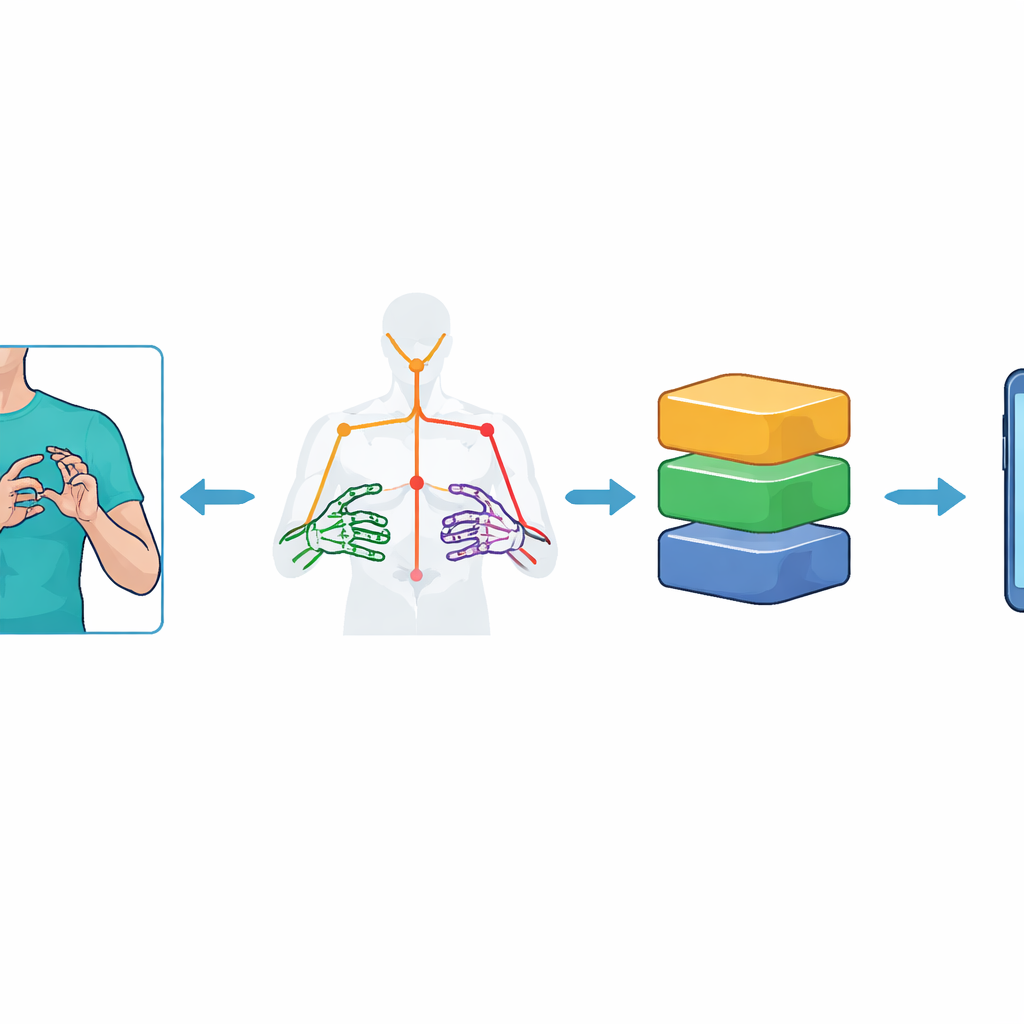
Обучение компьютеров видеть движение
Вместо подачи полноценных видеокадров в тяжёлую модель зрения система сначала сводит каждый кадр к набору ключевых точек, представляющих верхнюю часть тела и руки жестующего. С помощью набора инструментов MediaPipe Holistic от Google исследователи отслеживают 59 ориентиров — таких как плечо, локоть, запястье и суставы пальцев — и фиксируют их 3D-позиции во времени. Это даёт компактный «скелет» каждой последовательности жеста: 75 кадров на видео, каждый с 177 числовыми признаками. Чтобы повысить устойчивость к шуму, они расширяют набор данных аккуратными аугментациями видео — добавляют небольшие наклоны камеры, изменения освещения, искусственные помехи, ускорение и замедление движения. Эти шаги помогают моделям выучить сущность жеста, а не запоминать конкретный фон или условия записи.
Три подхода к распознаванию движущегося жеста
Имея более компактное представление движения, команда сравнивает три подхода глубокого обучения для распознавания каждого жеста. Первый — LSTM, сеть, спроектированная для последовательной обработки кадров, запоминания важных деталей и отбрасывания отвлекающей информации. Второй, BiLSTM, рассматривает жест и в направлении «прошлое→будущее», и «будущее→прошлое», что даёт более богатое представление движения. Третий — энкодер-only Transformer, который соотносит все кадры друг с другом с помощью механизма внимания: вместо строгого сканирования в порядке кадров он учится, какие моменты жеста наиболее взаимосвязаны. Все три модели обучались на одинаковом разбиении данных на тренировочную, валидационную и тестовую выборки и настраивались для классификации 33 слов только по паттернам движения.
Уменьшение объёма мощных моделей для малых устройств
Модели с высокой точностью часто слишком велики и медленны для устройств с ограниченными ресурсами, таких как смартфоны среднего уровня. Чтобы решить эту проблему, авторы применили оптимизации в стиле TinyML с использованием TensorFlow Lite. Они конвертировали каждую обученную модель в уменьшенные версии, снижая числовую точность внутренних весов — процесс, известный как квантизация после обучения. Были опробованы несколько схем, включая динамический диапазон, float16 и полную целочисленную квантизацию. Эти уменьшенные модели затем встроили в Android-приложение на базе Flutter. Поскольку пока нет встроенной поддержки запуска MediaPipe Holistic прямо на телефоне внутри Flutter, лёгкий внешний сервер извлекает ключевые точки и передаёт в приложение только компактные данные о движении, а финальное распознавание выполняется непосредственно на устройстве.
Быстрое и точное чтение жестов в вашем кармане
Несмотря на сокращение ради скорости и размера, лучшие модели сохраняют впечатляющую производительность: примерно 94–96% точности на тесте для 33 слов KSL. Динамически квантизированный BiLSTM достигает наивысшей точности — 95.71%, тогда как квантизированная модель Transformer обеспечивает самые быстрые предсказания на телефоне — около 16 миллисекунд на жест — при размере модели чуть более 1 МБ. LSTM занимает промежуточную позицию по размеру, скорости и точности. Все три модели работают с умеренным использованием CPU и памяти, что указывает на то, что распознавание KSL в реальном времени может быть практичным даже на обычных смартфонах без постоянного доступа в интернет или дорогостоящего оборудования.
Что это значит для повседневной жизни
Говоря просто, эта работа показывает, что обычному смартфону можно дать способность «понимать» базовый набор слов KSL по коротким видео — надёжно и быстро. Создав специализированный видеонабор KSL, сведя жесты к скелетам тела и рук и сжав современные последовательные модели для эффективной работы на устройстве, исследователи предложили план по созданию доступной технологии распознавания жестов, ориентированной на региональный язык. Хотя текущая система обрабатывает только 33 изолированных слова и по-прежнему опирается на небольшой сервер для извлечения признаков, это конкретный шаг к более богатым полностью локальным инструментам, которые могли бы помочь сотням тысяч пользователей KSL легче общаться с слышащим миром.
Цитирование: V, U., K S, N., K S, N. et al. Dynamic Kannada Sign Language Recognition on Resource Constrained Devices. Sci Rep 16, 11186 (2026). https://doi.org/10.1038/s41598-026-40181-7
Ключевые слова: жестовый язык каннада, мобильное распознавание жестов, TinyML, распознавание жестов, помогающие технологии