Clear Sky Science · sv
Dynamisk kannada teckenspråksigenkänning på resursbegränsade enheter
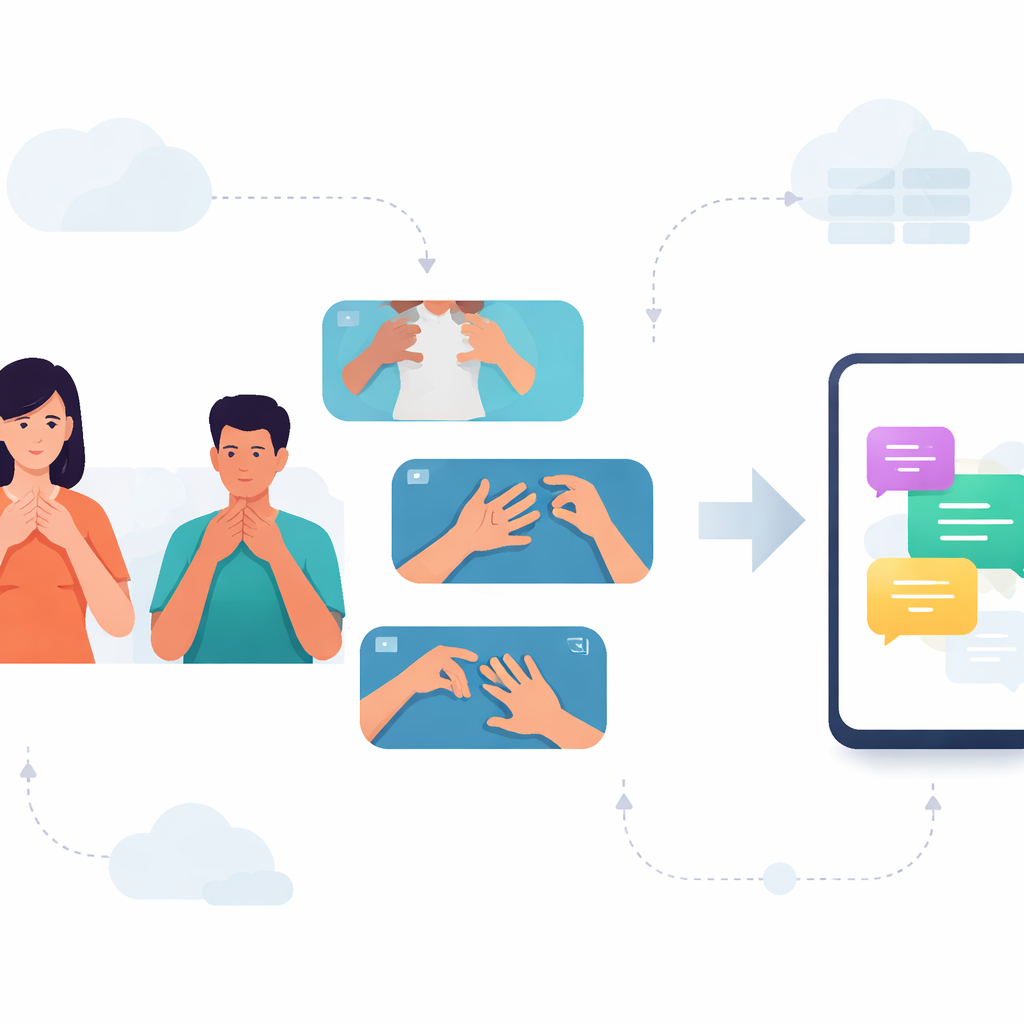
Att överbrygga samtalsklyftan
För många döva i Karnataka är vardagliga samtal beroende av kannada teckenspråk (KSL). Ändå förstår de flesta telefoner och appar endast talade och skrivna språk, vilket lämnar KSL-användare utan de digitala verktyg andra tar för givna. Denna studie tar sig an den luckan genom att bygga ett system som kan läsa korta KSL-tecken från video och köras effektivt på vanliga smartphones, vilket öppnar dörren för snabbare, mer privat kommunikation mellan teckenspråkiga och icke-teckenspråkiga.
Att bygga ett bibliotek av tecken för verkliga förhållanden
Eftersom det inte fanns någon offentlig videodatabas med KSL-ord började forskarna med att skapa en från grunden. De samarbetade med lärare vid en skola för döva barn och 38 volontärer från hela Karnataka för att spela in mer än tvåtusen videor med KSL-tecken. Teamet fokuserade på 33 vardagsord indelade i fyra teman: frukter, månader, veckodagar och tid på dygnet eller årstider. Varje ord filmades många gånger, i olika hastigheter, på olika platser och under varierande ljusförhållanden. Denna variation hjälper systemet att hantera de röriga, oförutsägbara förhållanden som finns i verkliga livet i stället för att bara fungera i en perfekt labbmiljö.
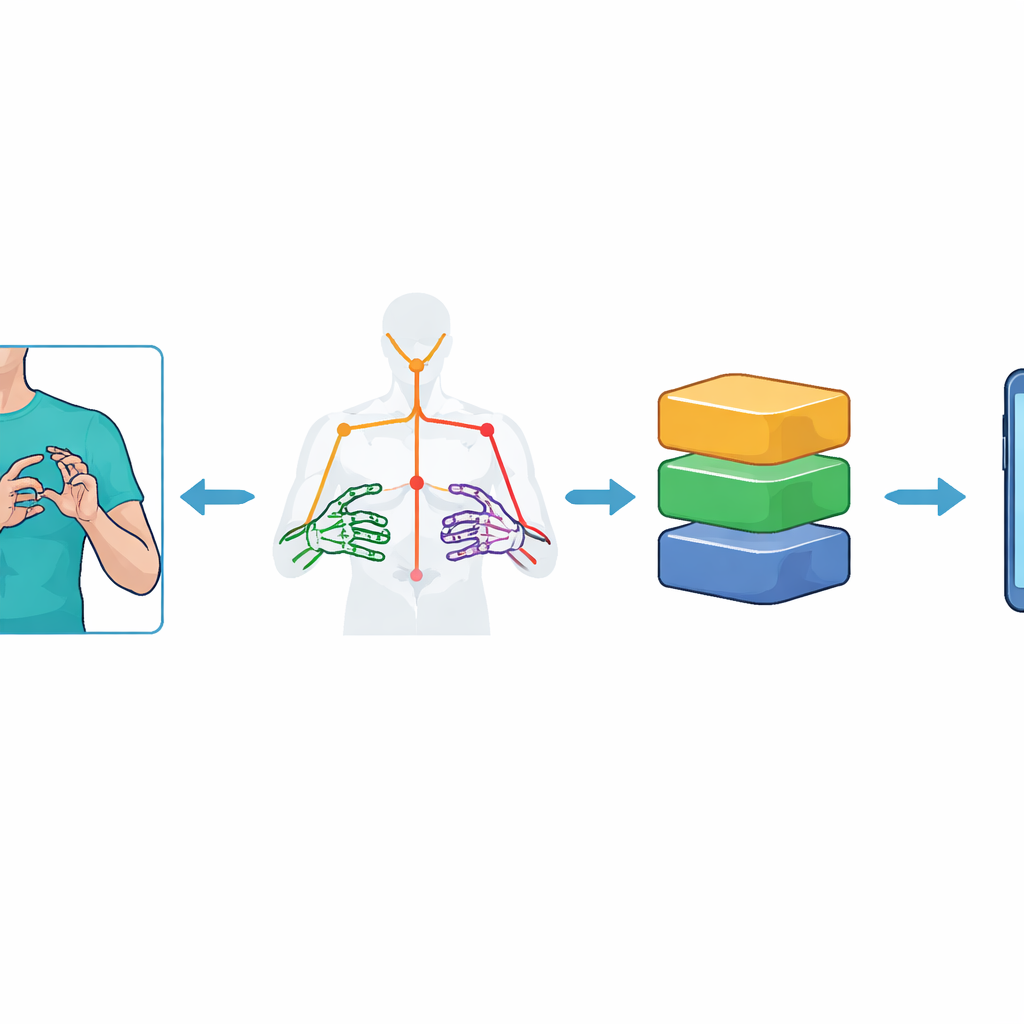
Att lära datorer att se rörelse
I stället för att mata in fullständiga videobilder i en tung synmodell reducerar systemet först varje bildruta till en uppsättning nyckelpunkter som representerar tecknarens överkropp och händer. Med Googles MediaPipe Holistic-verktygspaket spårar forskarna 59 landmärken—såsom axel, armbåge, handled och fingerleder—och registrerar deras 3D-positioner över tid. Detta ger ett kompakt ”skelett” av varje gestsekvens: 75 ramar per video, var och en med 177 numeriska funktioner. För att göra systemet mer robust mot brus förstärker de datasetet med noggrant utförda videoaugmenteringar, med små kameravinklingar, ljusförändringar, konstgjorda fläckar samt upp- och nedspolning av rörelsehastighet. Dessa steg hjälper modellerna att lära sig tecknets kärna i stället för att memorera en specifik bakgrund eller inspelningssituation.
Tre sätt att läsa en rörlig tecken
Med denna renare representation av rörelse jämför teamet tre djupa inlärningsmetoder för att känna igen varje tecknat ord. Den första är en LSTM, ett nätverk utformat för att följa sekvenser bildruta för bildruta, som kommer ihåg viktiga detaljer samtidigt som det glömmer störningar. Den andra, en BiLSTM, betraktar gesten både framifrån-till-bak och bakifrån-till-fram, vilket ger en rikare bild av rörelsen. Den tredje är en encoder-only Transformer, som ser alla ramar i relation till varandra med hjälp av en attention-mekanism: i stället för att skanna i strikt ordning lär den sig vilka ögonblick i tecknet som mest beror på varandra. Alla tre modellerna ser samma data uppdelade i tränings-, validerings- och testuppsättningar och är finjusterade för att klassificera de 33 orden enbart utifrån rörelsemönstren.
Att krympa kraftfulla modeller för små enheter
Modeller med hög noggrannhet är ofta för stora och långsamma för resursbegränsade enheter som mellanklass-telefoner. För att lösa detta tillämpar författarna TinyML-liknande optimeringar med TensorFlow Lite. De konverterar varje tränad modell till mindre versioner genom att minska den numeriska precisionen i interna vikter—en process som kallas post-training quantization. Flera scheman prövas, inklusive dynamiskt omfång, float16 och helinteger-variantar. Dessa nedtrimmade modeller bäddas sedan in i en Flutter-baserad Android-app. Eftersom det ännu inte finns inbyggt stöd för att köra MediaPipe Holistic direkt på telefonen inom Flutter används en extern, lättviktsserver för att extrahera nyckelpunkterna och skickar endast de kompakta rörelsedata tillbaka till appen, som utför den slutliga igenkänningen lokalt på enheten.
Snabb, exakt teckenavläsning i din hand
Trots att de har minskats för snabbhet och storlek behåller de bästa modellerna imponerande prestanda: omkring 94–96 % testnoggrannhet på de 33 KSL-orden. Den dynamiskt kvantiserade BiLSTM når högst noggrannhet på 95,71 %, medan den kvantiserade Transformer-modellen erbjuder de snabbaste förutsägelserna på telefonen—omkring 16 millisekunder per tecken—med en modellstorlek strax över 1 MB. LSTM-modellen hamnar i en mittposition mellan storlek, hastighet och noggrannhet. Alla tre körs med måttlig CPU- och minnesanvändning, vilket tyder på att realtidsigenkänning av KSL kan vara praktiskt även på vardagliga smartphones utan ständig internetuppkoppling eller dyr hårdvara.
Vad detta betyder för vardagslivet
Enkelt uttryckt visar detta arbete att det är möjligt att ge en vanlig smartphone förmågan att ”förstå” en kärnuppsättning KSL-ord från korta videor, pålitligt och snabbt. Genom att skapa ett dedikerat KSL-videodataset, destillera gester till kroppsoch hand-skelett och komprimera moderna sekvensmodeller för att köras effektivt i kanten, ger forskarna en mall för tillgänglig teckenspråksigenkänningsteknik anpassad till ett regionalt språk. Även om det nuvarande systemet bara hanterar 33 isolerade ord och fortfarande är beroende av en liten server för funktionsutvinning, markerar det ett konkret steg mot rikare, helt enhetsbaserade verktyg som skulle kunna hjälpa hundratusentals KSL-användare att kommunicera smidigare med hörande världen.
Citering: V, U., K S, N., K S, N. et al. Dynamic Kannada Sign Language Recognition on Resource Constrained Devices. Sci Rep 16, 11186 (2026). https://doi.org/10.1038/s41598-026-40181-7
Nyckelord: Kannada teckenspråk, mobil teckenspråksigenkänning, TinyML, gestigenkänning, hjälpteknik