Clear Sky Science · tr
Kaynak Kısıtlı Cihazlarda Dinamik Kannada İşaret Dili Tanıma
Konuşma Uçurumu Köprülemek
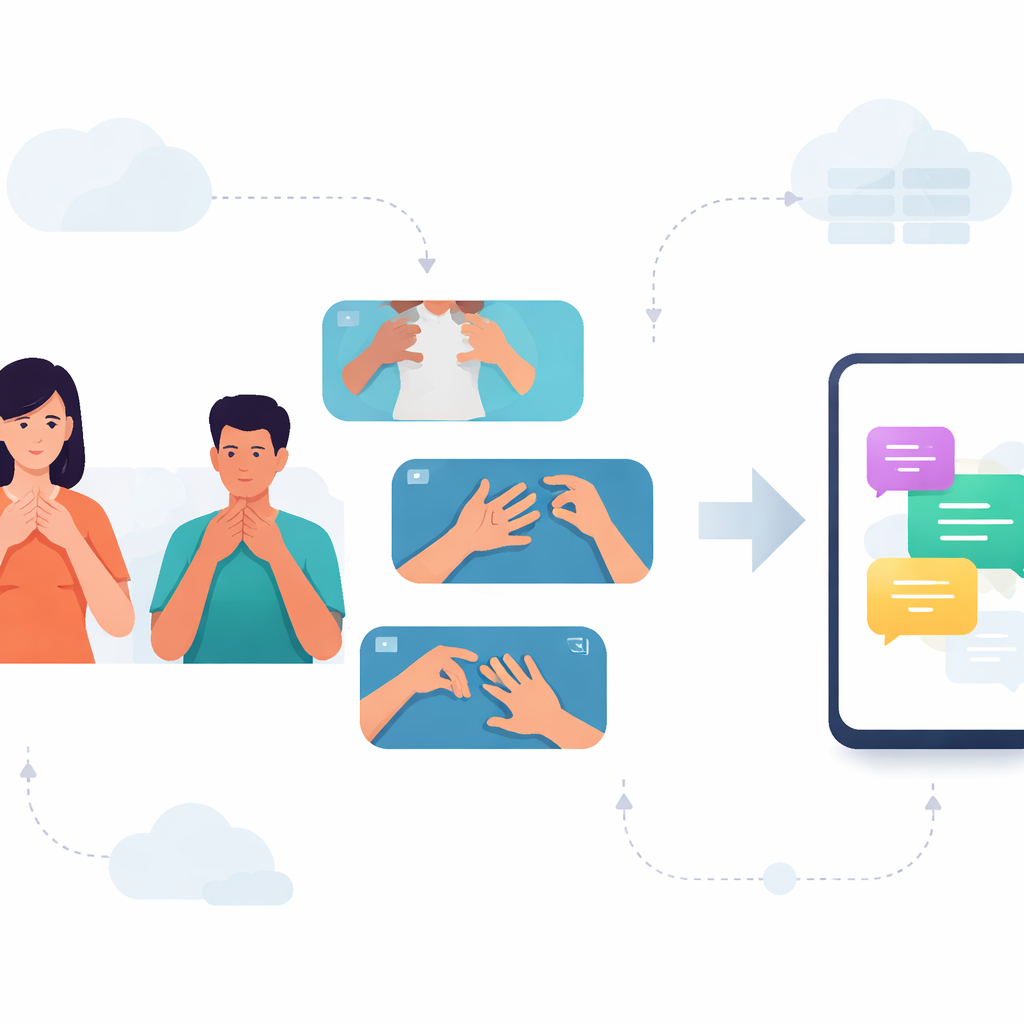
Karnataka’daki birçok İşitme Engelli kişi için günlük konuşmalar Kannada İşaret Diline (KSL) dayanır. Oysa çoğu telefon ve uygulama yalnızca konuşulan ve yazılı dilleri anlar; bu da KSL kullanıcılarını başkalarının sahip olduğu dijital araçlardan yoksun bırakır. Bu çalışma, kısa KSL işaretlerini videodan okuyabilen ve sıradan akıllı telefonlarda verimli çalışabilen bir sistem geliştirerek bu uçurumu kapatmayı amaçlıyor; böylece işaret kullanıcıları ile işitme sahibi olmayanlar arasında daha hızlı, daha özel iletişim mümkün oluyor.
Gerçek Dünya İşaret Kütüphanesi Oluşturmak
Halihazırda kamuya açık bir KSL video veritabanı olmadığı için araştırmacılar sıfırdan bir veritabanı oluşturmaya başladı. İşitme Engelli çocukların eğitim gördüğü bir okulun öğretmenleri ve Karnataka genelinden 38 gönüllüyle çalışarak 2000’den fazla KSL işareti videosu kaydettiler. Ekip, meyveler, aylar, haftanın günleri ve günün zamanları/ mevsimler olmak üzere dört tema altında gruplanmış 33 günlük kelimeye odaklandı. Her kelime birçok kez, farklı hızlarda, değişik mekânlarda ve farklı aydınlatma koşullarında çekildi. Bu çeşitlilik, sistemin yalnızca mükemmel bir laboratuvar ortamında değil, gerçek hayattaki dağınık ve öngörülemez koşullarda da başa çıkmasına yardımcı olur.
Bilgisayarlara Hareketi Görmeyi Öğretmek
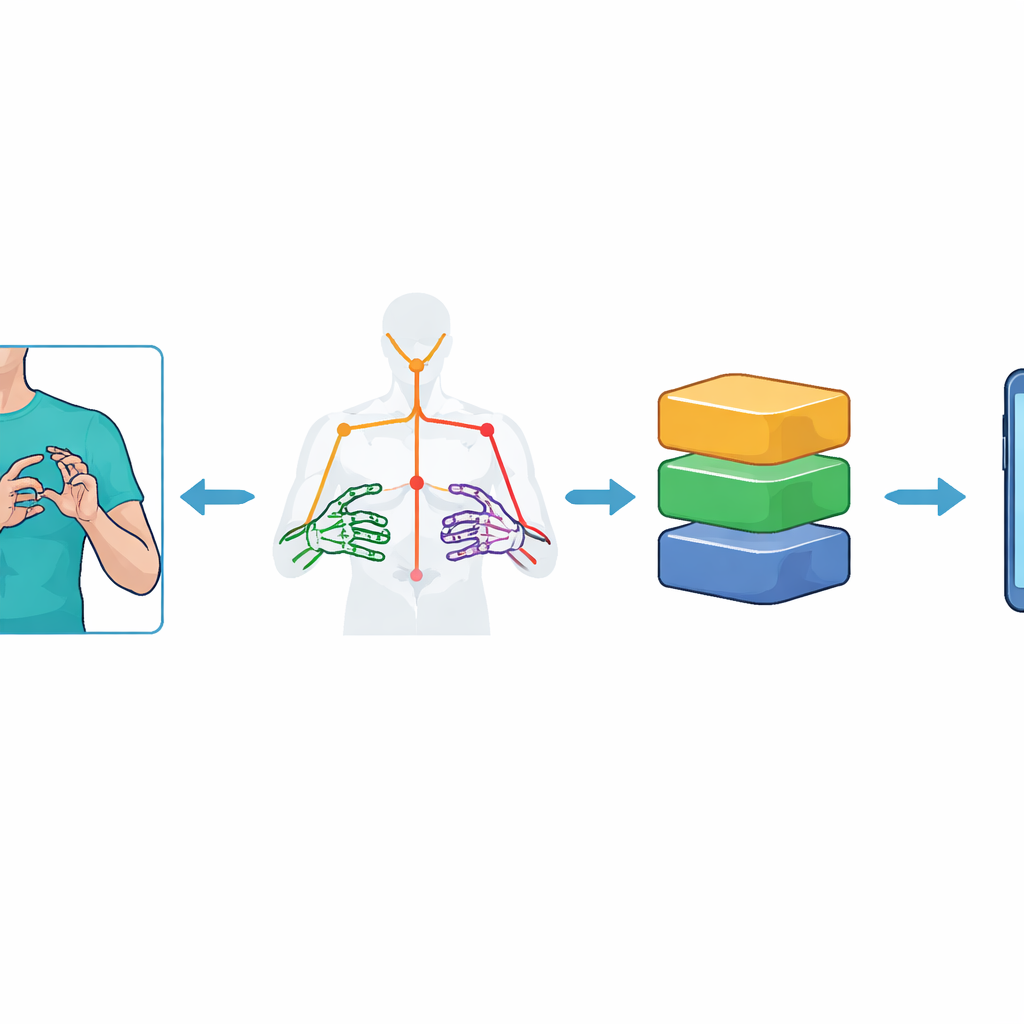
Ağır bir görsel modele tam video görüntülerini beslemek yerine sistem önce her kareyi işaretçilerin üst vücudu ve ellerini temsil eden bir anahtar nokta kümesine indirger. Google’ın MediaPipe Holistic aracı kullanılarak araştırmacılar omuz, dirsek, bilek ve parmak eklemleri gibi 59 işaret noktası izliyor ve bunların zamana göre 3B konumlarını kaydediyor. Bu, her jest dizisinin kompakt bir “iskelet” temsili oluşturur: videoda 75 kare ve her karede 177 sayısal özellik. Sistemi gürültüye karşı güçlendirmek için veri kümesi dikkatlice video artırmalarıyla genişletiliyor; ufak kamera eğimleri, aydınlatma değişimleri, yapay lekeler, hareket hızlandırma ve yavaşlatmalar ekleniyor. Bu adımlar modellerin özel bir arka planı veya kayıt koşulunu ezberlemek yerine bir işaretin özünü öğrenmesine yardımcı olur.
Hareket Eden Bir İşareti Okumanın Üç Yolu
Bu daha temiz hareket temsiliyle ekip, imzalı her kelimeyi tanımak için üç derin öğrenme yaklaşımını karşılaştırıyor. Birincisi, kare kare sıraları izleyip önemli ayrıntıları hatırlarken dikkat dağıtıcıları unutmaya yardımcı olacak şekilde tasarlanmış bir LSTM. İkincisi, geçmişten geleceğe ve gelecekten geçmişe doğru bakarak harekete daha zengin bir görünüm kazandıran BiLSTM. Üçüncüsü ise, katmanlı dikkat mekanizmasıyla tüm kareleri birbirleriyle ilişkilendirerek sırada katı bir tarama yerine hangi anların birbirine en çok bağlı olduğunu öğrenen yalnızca kodlayıcı (encoder-only) bir Transformer. Üç model de aynı veriyi eğitim, doğrulama ve test olarak bölünmüş şekilde görüyor ve yalnızca hareket desenlerinden 33 kelimeyi sınıflandıracak biçimde ayarlanıyor.
Güçlü Modelleri Küçük Cihazlara Sığdırmak
Yüksek doğruluklu modeller genellikle orta düzey telefonlar gibi kaynak kısıtlı cihazlar için çok büyük ve yavaştır. Bunu çözmek için yazarlar TensorFlow Lite kullanarak TinyML tarzı optimizasyonlar uyguluyor. Her eğitilmiş modeli, dahili ağırlıkların sayısal hassasiyetini azaltarak daha küçük sürümlere dönüştürüyorlar — buna eğitim sonrası kantizasyon deniyor. Dinamik aralık, float16 ve tam-tamsayı gibi birkaç şema deneniyor. Bu budanmış modeller daha sonra Flutter tabanlı bir Android uygulamasına gömülüyor. MediaPipe Holistic’in doğrudan Flutter içinde telefonda çalıştırılması için henüz yerleşik destek olmadığından, hafif bir dış sunucu anahtar noktaları çıkarıyor ve yalnızca kompakt hareket verilerini uygulamaya gönderiyor; uygulama son tanımayı cihaz içinde gerçekleştiriyor.
Elinizde Hızlı, Doğru İşaret Okuma
Hız ve boyut için kısaltılmış olmalarına rağmen en iyi modeller etkileyici performansı koruyor: 33 KSL kelimesi üzerinde test doğruluğu yaklaşık %94–96 aralığında. Dinamik olarak kantize edilmiş BiLSTM en yüksek doğruluğa %95,71 ile ulaşıyor; kantize Transformer modeli ise telefonda en hızlı tahminleri sunuyor — işaret başına yaklaşık 16 milisaniye — ve model boyutu 1 MB’ın biraz üzerinde. LSTM boyut, hız ve doğruluk arasında bir orta yol sunuyor. Üçü de mütevazı CPU ve bellek kullanımıyla çalışıyor; bu da gerçek zamanlı KSL tanımanın sürekli internet bağlantısı veya pahalı donanım olmadan bile sıradan akıllı telefonlarda uygulanabilir olduğunu gösteriyor.
Günlük Yaşam İçin Anlamı
Basitçe söylemek gerekirse, bu çalışma düzenli bir akıllı telefona kısa videolardan çekirdek bir KSL kelime setini güvenilir ve hızlı biçimde “anlama” yeteneği kazandırmanın mümkün olduğunu gösteriyor. Adanmış bir KSL video veri kümesi oluşturarak, jestleri vücut ve el iskeletlerine indirerek ve modern sıra modellerini kenarda verimli çalışacak şekilde sıkıştırarak araştırmacılar bölgesel bir dile uygun erişilebilir işaret tanıma teknolojisi için bir yol haritası sunuyor. Mevcut sistem yalnızca 33 izole kelimeyi ele alıyor ve hâlâ özellik çıkarımı için küçük bir sunucuya dayanıyor olsa da, bu KSL kullanıcılarının işitme sahipleriyle daha akıcı iletişim kurmalarına yardımcı olabilecek, tamamen cihaz içi daha zengin araçlara doğru somut bir adımı temsil ediyor.
Atıf: V, U., K S, N., K S, N. et al. Dynamic Kannada Sign Language Recognition on Resource Constrained Devices. Sci Rep 16, 11186 (2026). https://doi.org/10.1038/s41598-026-40181-7
Anahtar kelimeler: Kannada işaret dili, mobil işaret tanıma, TinyML, jest tanıma, yardımcı teknoloji