Clear Sky Science · zh
PrimerAST:用于引物设计与质量评估的预测性机器学习工具
为何更智能的检测工具很重要
从追踪疫情暴发到诊断遗传疾病,无数实验室检测依赖一种称为 PCR 的主力方法,它能复制微量 DNA 以便检测。此类检测的成功取决于短片段 DNA——引物,它们指示复制机器从何处开始。设计良好的引物出乎意料地棘手,往往需要在实验台上反复试验。该研究介绍了 PrimerAST,一种利用机器学习帮助科学家快速区分强效与弱效引物候选的计算工具,从而在 DNA 检测中节省时间、金钱和挫败感。
挑选合适 DNA 起始片段的挑战
引物是在 PCR 开始前必须精确结合到基因组中选定位置的短 DNA 片段。如果它们结合过于松散、结合到错误位置,或自我缠结,检测可能失败或给出误导性结果。传统引物设计程序遵循关于引物长度、化学成分和简单稳定性检查的固定规则。这些规则有帮助,但通常各特征被单独对待,科学家仍需手动检查许多细节并猜测这些特征组合在真实实验中的表现。
将真实与失败的设计转为训练材料
研究人员首先通过组装一个经过精心标注的引物集合来构建 PrimerAST。他们从人类 DNA 的真实遗传变体入手,提取其周围序列,并使用一种流行的设计工具在符合医疗检测的现实设置下生成引物对。随后在实验室中以标准 PCR 条件对每对引物进行测试。产生干净、特异性 DNA 产物的引物对被标记为成功,其他未成功的被丢弃。为了教系统识别坏引物,团队还通过故意将关键性质推离安全范围来创建合成失败样本,例如使引物在某些碱基上过于富集或过于不足、出现长的重复碱基串,或在结合末端附近放置过多天然变异。
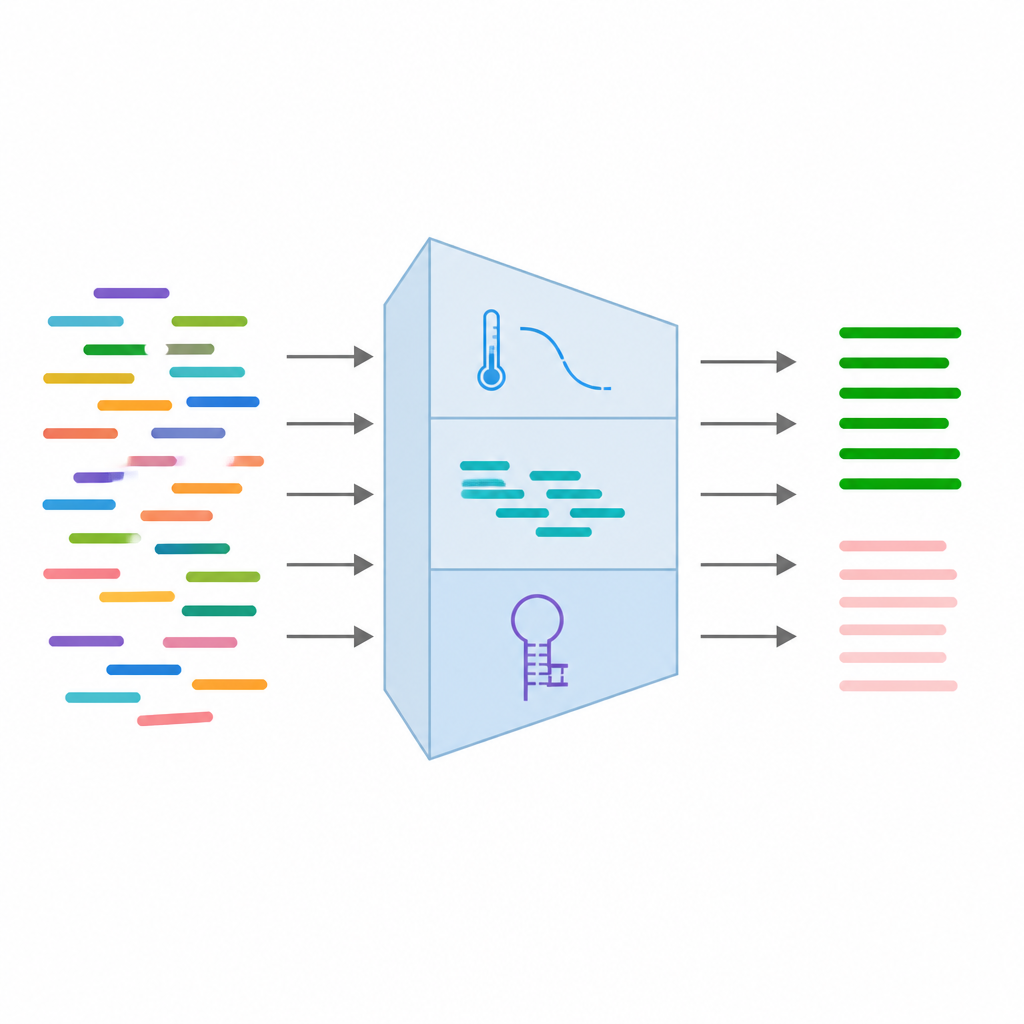
将关键引物特征输入机器学习
从每对引物中,团队收集了 24 项不同的测量值来捕捉其预期行为。这些包括长度与碱基平衡等基本序列特征、与引物结合紧密度相关的热力学特征,以及揭示其是否可能自我折叠或相互粘连的结构特征。他们还加入了结合位点已知 DNA 变体的信息以及模拟 PCR 运行的结果,以检查引物是否意外匹配基因组中的其他位置。数据清理与筛选后,保留了 16 项最可靠的特征并对其进行了标准化处理,以避免单一测量主导学习过程。
训练计算机分辨优劣
基于这 16 项特征,作者训练了几类监督式机器学习模型,包括逻辑回归、随机森林、支持向量机和梯度提升。他们共使用了 315 对引物,分为训练集和测试集,并使用常见的准确度评分与曲线来评估模型区分成功与失败引物的能力。四种模型均表现强劲,其中部分模型准确率超过 93%,并在区分两类样本方面得分很高。值得注意的是,引物配对间的温度平衡差异、重复碱基的长度以及天然变异的数量显著影响引物成功的可能性。基于这些结果,最佳模型被整合到一个用户友好的网页工具中,该工具以遗传变体为输入,设计候选引物并即时对其评分。
这对未来 DNA 检测意味着什么
对依赖 PCR 的科学家和临床医生而言,PrimerAST 像一个智能筛选器,在任何人进入实验室之前筛选众多引物选项并突出最有可能成功的那些。通过学习跨多个引物特征的模式而非仅依赖僵化规则,该工具可以减少反复试验、降低成本并加速针对新遗传变体的 DNA 检测设计。尽管它无法替代实际的实验室验证并仍需以更多真实世界数据不断完善,PrimerAST 展示了将 DNA 设计与机器学习结合如何使日常分子诊断更高效、更可靠。
引用: Al-Mahrami, N., Al Yazidi, S., Alrashdi, H. et al. PrimerAST: A predictive machine learning tool for primer design and quality assessment. Sci Rep 16, 14980 (2026). https://doi.org/10.1038/s41598-026-38238-8
关键词: PCR 引物, 引物设计, 机器学习, 生物信息学工具, 基因检测