Clear Sky Science · nl
PrimerAST: een voorspellend machine learning-hulpmiddel voor primerontwerp en kwaliteitsbeoordeling
Waarom slimme testinstrumenten ertoe doen
Van het volgen van uitbraken tot het diagnosticeren van genetische aandoeningen: talloze laboratoriumtests zijn afhankelijk van een robuuste methode genaamd PCR, die minuscule hoeveelheden DNA kopieert zodat ze detecteerbaar worden. Het succes van deze tests hangt af van korte DNA-stukjes, primers genoemd, die de kopieermachine vertellen waar te beginnen. Het ontwerpen van goede primers is verrassend complex en gaat vaak gepaard met proefondervindelijke iteraties aan de labbank. Deze studie introduceert PrimerAST, een computerhulpmiddel dat machine learning gebruikt om wetenschappers snel sterke primerkandidaten van zwakkere te scheiden, wat tijd, geld en frustratie bij DNA-testen bespaart.
De uitdaging van het kiezen van de juiste DNA-starters
Primers zijn korte stukken DNA die precies op een gekozen plek in het genoom moeten binden voordat PCR kan beginnen. Als ze te los binden, op de verkeerde plaats gaan zitten of verstrengelingen met zichzelf vormen, kan de test falen of misleidende resultaten geven. Traditionele primerontwerpprogramma’s volgen vaste regels over primerlengte, chemische samenstelling en eenvoudige stabiliteitscontroles. Die regels zijn nuttig, maar behandelen elk kenmerk grotendeels afzonderlijk, waardoor wetenschappers veel details handmatig moeten controleren en moeten raden hoe combinaties van kenmerken zich in echte experimenten zullen gedragen.
Van echte en foutieve ontwerpen naar trainingsmateriaal
De onderzoekers bouwden PrimerAST door eerst een zorgvuldig gelabelde verzameling primers samen te stellen. Ze begonnen met echte genetische varianten in menselijk DNA, haalden de omliggende sequentie eruit en gebruikten een gangbaar ontwerpgereedschap om primerparen te genereren met realistische instellingen voor medische tests. Elk van deze primerparen werd vervolgens in het laboratorium getest onder standaard PCR-condities. Sets die schone, specifieke DNA-producten opleverden, kregen het label werkend; andere faalden en werden verworpen. Om het systeem te leren herkennen wat slechte primers zijn, creëerde het team ook synthetische mislukkingen door doelbewust sleutelkenmerken buiten veilige grenzen te duwen, bijvoorbeeld door primers te rijk of te arm te maken aan bepaalde basen, lange opeenvolgingen van dezelfde letter toe te staan of te veel natuurlijke DNA-veranderingen vlak bij het bindingsuiteinde te plaatsen.
Belangrijke primer-eigenschappen invoeren in machine learning
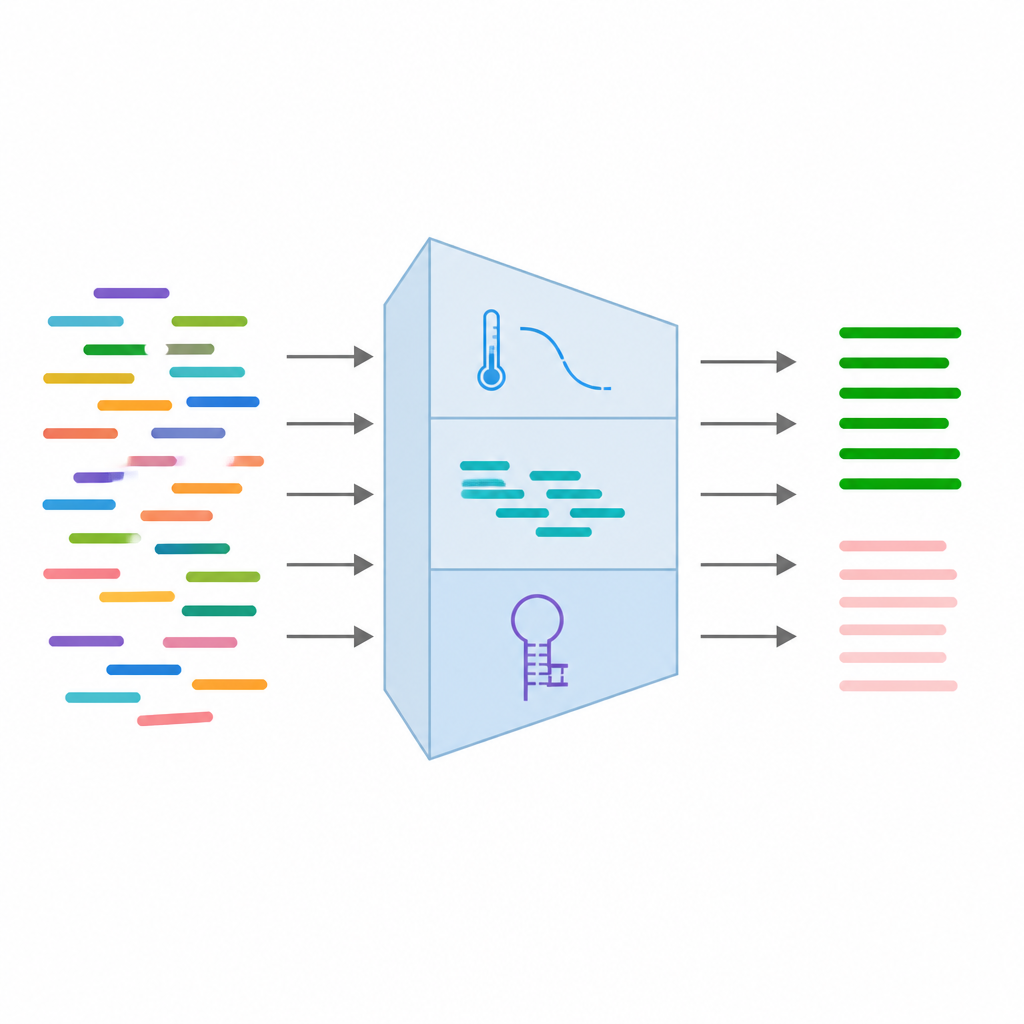
Van elk primerpaar verzamelde het team 24 verschillende metingen die vastleggen hoe het verwachte gedrag eruitziet. Daartoe behoren basale sequentiekenmerken zoals lengte en basenbalans, thermodynamische eigenschappen gerelateerd aan hoe stevig de primers binden, en structurele kenmerken die laten zien of ze waarschijnlijk naar zichzelf terugvouwen of aan elkaar kleven. Ze voegden ook informatie toe over bekende DNA-varianten op de bindingsplaats en resultaten van gesimuleerde PCR-runs die controleren of de primers per ongeluk andere locaties in het genoom matchen. Na het opschonen en filteren van de data behielden ze 16 van de meest betrouwbare kenmerken en standaardiseerden deze zodat geen enkele meting het leerproces zou domineren.
De computer leren goed van slecht te onderscheiden
Met deze 16 kenmerken trainden de auteurs meerdere typen gesuperviseerde machine learning-modellen, waaronder logistieke regressie, random forests, support vector machines en gradient boosting. Ze gebruikten in totaal 315 primerparen, verdeeld in trainings- en testsets, en evalueerden de modellen met gangbare nauwkeurigheidsscores en curves die meten hoe goed de hulpmiddelen werkende en falende primers van elkaar onderscheiden. Alle vier modellen presteerden sterk, waarbij sommige accuratesse boven 93 procent bereikten en zeer hoge scores op hoe duidelijk ze de twee klassen scheiden. Opvallend waren verschillen in temperatuurbalans tussen primerpartners, de lengte van herhaalde basen en het aantal natuurlijke varianten als belangrijke bepalende factoren voor het succes van een primer. Op basis van deze resultaten werd het beste model geïntegreerd in een gebruiksvriendelijke webtool die een genetische variant als invoer neemt, kandidaat-primers ontwerpt en ze direct beoordeelt.
Wat dit betekent voor toekomstige DNA-testen
Voor wetenschappers en clinici die op PCR vertrouwen, fungeert PrimerAST als een slimme filter die veel primeropties screent en de opties markeert die het meest waarschijnlijk werken voordat iemand het laboratorium betreedt. Door te leren van patronen over meerdere primerkenmerken in plaats van zich alleen op starre regels te baseren, kan het hulpmiddel proefondervindelijkheid verminderen, kosten verlagen en het ontwerp van DNA-tests voor nieuwe genetische varianten versnellen. Hoewel het geen vervanging is voor echte laboratoriumvalidatie en nog moet groeien met meer gegevens uit de praktijk, laat PrimerAST zien hoe de combinatie van DNA-ontwerp en machine learning de alledaagse moleculaire diagnostiek efficiënter en betrouwbaarder kan maken.
Bronvermelding: Al-Mahrami, N., Al Yazidi, S., Alrashdi, H. et al. PrimerAST: A predictive machine learning tool for primer design and quality assessment. Sci Rep 16, 14980 (2026). https://doi.org/10.1038/s41598-026-38238-8
Trefwoorden: PCR-primers, primerontwerp, machine learning, bioinformatica-hulpmiddel, genetische testen