Clear Sky Science · es
PrimerAST: una herramienta predictiva de aprendizaje automático para el diseño y la evaluación de la calidad de cebadores
Por qué importan herramientas de prueba más inteligentes
Desde el seguimiento de brotes hasta el diagnóstico de condiciones genéticas, innumerables pruebas de laboratorio dependen de un método básico llamado PCR, que copia pequeñas cantidades de ADN para que puedan detectarse. El éxito de estas pruebas depende de fragmentos cortos de ADN llamados cebadores que indican a la maquinaria de copiado dónde empezar. Diseñar buenos cebadores es sorprendentemente complicado y a menudo implica ensayo y error en el banco de laboratorio. Este estudio presenta PrimerAST, una herramienta informática que usa aprendizaje automático para ayudar a los científicos a clasificar rápidamente cebadores candidatos fuertes frente a débiles, ahorrando tiempo, dinero y frustración en las pruebas de ADN.
El reto de elegir los iniciadores de ADN adecuados
Los cebadores son tramos cortos de ADN que deben unirse con precisión a un lugar elegido del genoma antes de que pueda comenzar la PCR. Si se unen demasiado flojo, al lugar equivocado o forman enredos consigo mismos, la prueba puede fallar o dar resultados engañosos. Los programas tradicionales de diseño de cebadores siguen reglas fijas sobre la longitud del cebador, su composición química y comprobaciones simples de estabilidad. Estas reglas son útiles pero tratan cada característica de forma aislada en gran medida, dejando a los científicos inspeccionar muchos detalles a mano y adivinar cómo se comportarán las combinaciones de características juntas en experimentos reales.
Convertir diseños reales y fallidos en material de entrenamiento
Los investigadores construyeron PrimerAST primero reuniendo una colección cuidadosamente anotada de cebadores. Partieron de variantes genéticas reales en ADN humano, extrajeron la secuencia circundante y usaron una herramienta de diseño popular para generar pares de cebadores bajo configuraciones realistas para pruebas médicas. Cada uno de estos pares de cebadores se probó luego en el laboratorio usando condiciones estándar de PCR. Los conjuntos que produjeron productos de ADN limpios y específicos se etiquetaron como funcionales, mientras que otros fallaron y se descartaron. Para enseñar al sistema cómo son los cebadores malos, el equipo también creó fallos sintéticos empujando deliberadamente propiedades clave fuera de rangos seguros, como hacer los cebadores demasiado ricos o pobres en ciertas bases, permitir repeticiones largas de la misma letra o situar demasiados cambios naturales del ADN cerca del extremo de unión.
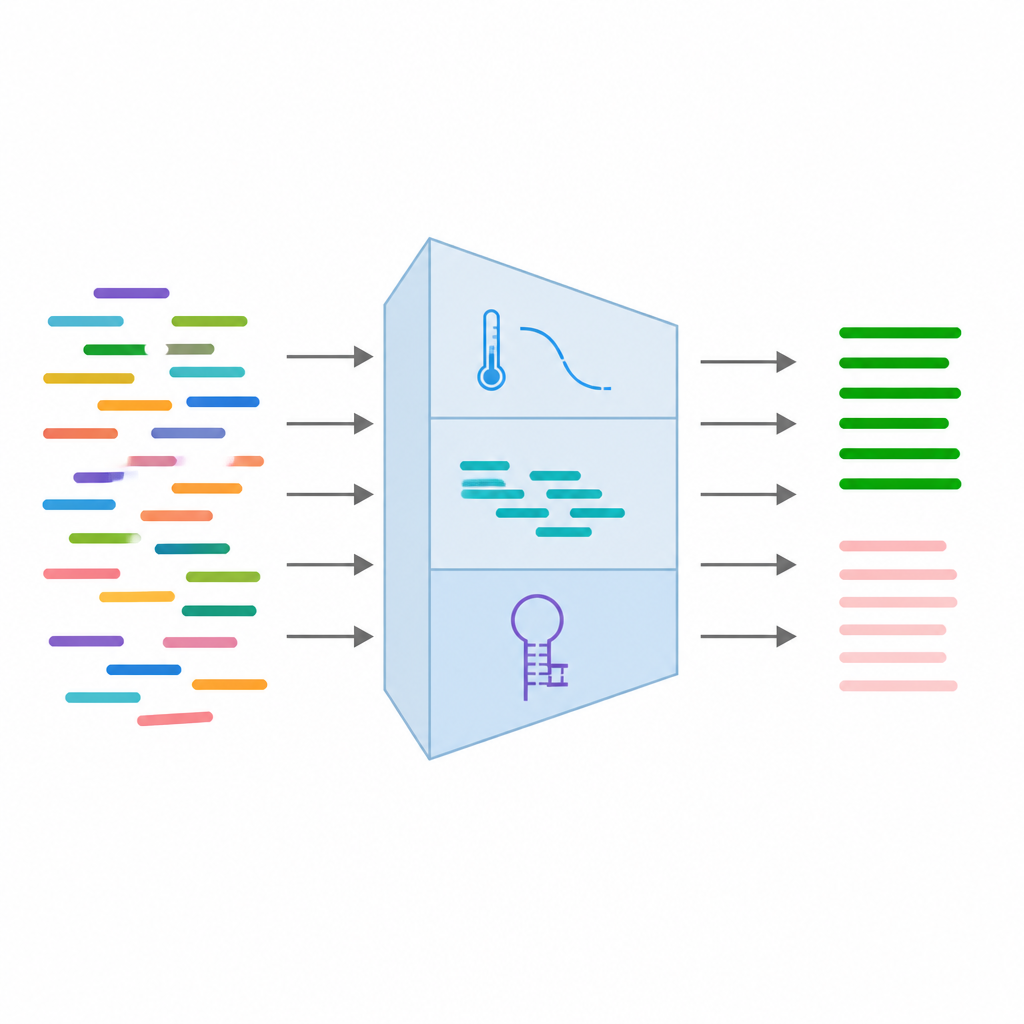
Alimentando rasgos clave de los cebadores al aprendizaje automático
De cada par de cebadores, el equipo recopiló 24 mediciones diferentes que capturan cómo se espera que se comporten. Estas incluyen rasgos básicos de secuencia como longitud y equilibrio de bases, rasgos termodinámicos relacionados con la afinidad de unión de los cebadores y rasgos estructurales que revelan si es probable que se plieguen sobre sí mismos o se adhieran entre sí. También añadieron información sobre variantes de ADN conocidas en el sitio de unión y resultados de corridas de PCR simuladas que comprueban si los cebadores coinciden accidentalmente con otras ubicaciones del genoma. Tras limpiar y filtrar los datos, conservaron 16 de las características más fiables y las estandarizaron para que ninguna medición individual dominara el proceso de aprendizaje.
Enseñar al ordenador a distinguir buenos de malos
Con estas 16 características, los autores entrenaron varios tipos de modelos de aprendizaje supervisado, incluyendo regresión logística, bosques aleatorios, máquinas de soporte vectorial y boosting de gradiente. Utilizaron 315 pares de cebadores en total, divididos en conjuntos de entrenamiento y prueba, y evaluaron los modelos usando puntuaciones de precisión comunes y curvas que miden qué tan bien las herramientas distinguen cebadores funcionales de fallidos. Los cuatro modelos rindieron con fuerza, algunos alcanzando precisión por encima del 93 por ciento y puntuaciones muy altas en la separación de las dos clases. Cabe destacar que diferencias en el equilibrio de temperatura entre las parejas de cebadores, la longitud de repeticiones de bases y el número de variantes naturales influyeron fuertemente en la probabilidad de éxito de un cebador. Basándose en estos resultados, el mejor modelo se integró en una herramienta web fácil de usar que toma una variante genética como entrada, diseña cebadores candidatos y los puntúa al instante.
Lo que esto significa para las pruebas de ADN futuras
Para científicos y clínicos que dependen de la PCR, PrimerAST actúa como un filtro inteligente que examina muchas opciones de cebadores y resalta aquellas con mayor probabilidad de funcionar antes de que nadie entre al laboratorio. Al aprender de patrones a través de múltiples rasgos de cebadores en lugar de depender solo de reglas rígidas, la herramienta puede reducir el ensayo y error, recortar costes y acelerar el diseño de pruebas de ADN para nuevas variantes genéticas. Aunque no sustituye la validación experimental y aún necesita crecer con más datos del mundo real, PrimerAST muestra cómo combinar el diseño de ADN con aprendizaje automático puede hacer que la diagnóstico molecular cotidiano sea más eficiente y fiable.
Cita: Al-Mahrami, N., Al Yazidi, S., Alrashdi, H. et al. PrimerAST: A predictive machine learning tool for primer design and quality assessment. Sci Rep 16, 14980 (2026). https://doi.org/10.1038/s41598-026-38238-8
Palabras clave: Cebadores de PCR, diseño de cebadores, aprendizaje automático, herramienta bioinformática, pruebas genéticas