Clear Sky Science · en
PrimerAST: A predictive machine learning tool for primer design and quality assessment
Why smarter test tools matter
From tracking outbreaks to diagnosing genetic conditions, countless lab tests depend on a workhorse method called PCR, which copies tiny amounts of DNA so they can be detected. The success of these tests hinges on short DNA pieces called primers that tell the copying machinery where to start. Designing good primers is surprisingly tricky and often involves trial and error at the lab bench. This study introduces PrimerAST, a computer tool that uses machine learning to help scientists quickly sort strong primer candidates from weak ones, saving time, money, and frustration in DNA testing.
The challenge of picking the right DNA starters
Primers are short stretches of DNA that must bind precisely to a chosen spot in the genome before PCR can begin. If they bind too loosely, to the wrong place, or form tangles with themselves, the test can fail or give misleading results. Traditional primer design programs follow fixed rules about primer length, chemical makeup, and simple stability checks. These rules are helpful but treat each feature largely on its own, leaving scientists to inspect many details by hand and guess how combinations of features will behave together in real experiments.
Turning real and faulty designs into training material
The researchers built PrimerAST by first assembling a carefully labeled collection of primers. They started from real genetic variants in human DNA, pulled out the surrounding sequence, and used a popular design tool to generate primer pairs under realistic settings for medical testing. Each of these primer pairs was then tried in the lab using standard PCR conditions. Sets that produced clean, specific DNA products were labeled as working, while others failed and were discarded. To teach the system what bad primers look like, the team also created synthetic failures by deliberately pushing key properties outside safe ranges, such as making the primers too rich or too poor in certain bases, allowing long runs of the same letter, or placing too many natural DNA changes near the binding end.
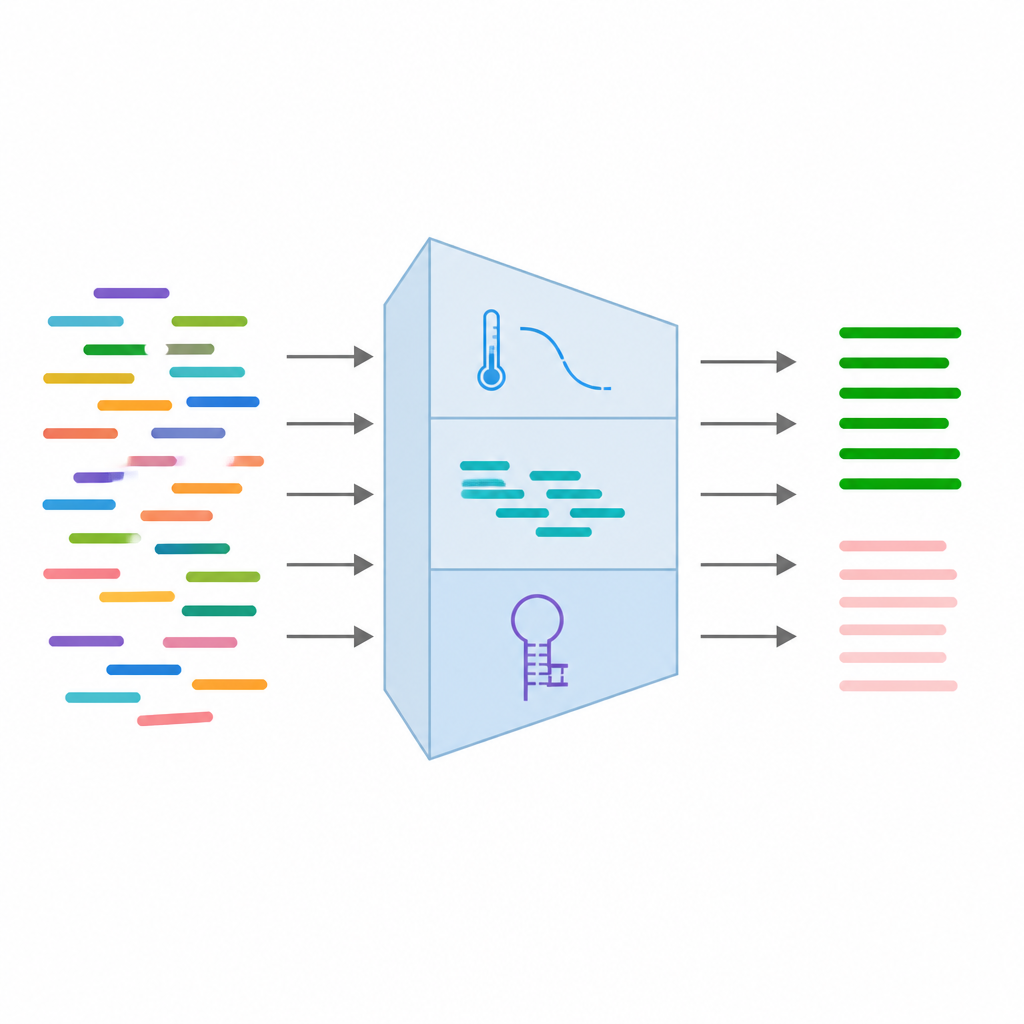
Feeding key primer traits into machine learning
From every primer pair, the team collected 24 different measurements that capture how it is expected to behave. These include basic sequence traits like length and base balance, thermodynamic traits related to how tightly the primers bind, and structural traits that reveal whether they are likely to fold back on themselves or stick to each other. They also added information about known DNA variants at the binding site and results from simulated PCR runs that check if the primers accidentally match other locations in the genome. After cleaning and filtering the data, they kept 16 of the most reliable features and standardized them so that no single measurement would dominate the learning process.
Teaching the computer to spot good from bad
With these 16 features, the authors trained several types of supervised machine learning models, including logistic regression, random forests, support vector machines, and gradient boosting. They used 315 primer pairs in total, split into training and testing sets, and evaluated the models using common accuracy scores and curves that measure how well the tools distinguish working from failing primers. All four models performed strongly, with some achieving accuracy above 93 percent and very high scores on how cleanly they separate the two classes. Notably, differences in temperature balance between primer partners, the length of repeated bases, and the number of natural variants strongly shaped whether a primer was likely to succeed. Based on these results, the best model was integrated into a user friendly web tool that takes a genetic variant as input, designs candidate primers, and instantly scores them.
What this means for future DNA testing
For scientists and clinicians who rely on PCR, PrimerAST acts like a smart filter that screens many primer options and highlights those most likely to work before anyone steps into the lab. By learning from patterns across multiple primer traits rather than rigid rules alone, the tool can reduce trial and error, cut costs, and speed up the design of DNA tests for new genetic variants. While it does not replace actual lab validation and still needs to grow with more real-world data, PrimerAST shows how combining DNA design with machine learning can make everyday molecular diagnostics more efficient and reliable.
Citation: Al-Mahrami, N., Al Yazidi, S., Alrashdi, H. et al. PrimerAST: A predictive machine learning tool for primer design and quality assessment. Sci Rep 16, 14980 (2026). https://doi.org/10.1038/s41598-026-38238-8
Keywords: PCR primers, primer design, machine learning, bioinformatics tool, genetic testing