Clear Sky Science · de
PrimerAST: Ein prädiktives Machine-Learning-Tool zur Primer-Entwicklung und Qualitätsbewertung
Warum intelligentere Testwerkzeuge wichtig sind
Von der Nachverfolgung von Ausbrüchen bis zur Diagnose genetischer Erkrankungen beruhen zahllose Labortests auf einer zentralen Methode namens PCR, die winzige DNA-Mengen vervielfältigt, damit sie nachgewiesen werden können. Der Erfolg dieser Tests hängt von kurzen DNA-Abschnitten ab, sogenannten Primern, die der Kopiermaschinerie sagen, wo sie beginnen soll. Gute Primer zu entwerfen ist überraschend knifflig und erfolgt häufig durch Versuch und Irrtum am Labortisch. Diese Studie stellt PrimerAST vor, ein Computerwerkzeug, das Machine Learning nutzt, um Wissenschaftlern zu helfen, starke Primer-Kandidaten schnell von schwachen zu trennen und so Zeit, Geld und Frustration bei DNA-Tests zu sparen.
Die Herausforderung, die richtigen DNA-Starter auszuwählen
Primer sind kurze DNA-Abschnitte, die sich präzise an eine gewählte Stelle im Genom anlagern müssen, bevor die PCR beginnen kann. Binden sie zu locker, an der falschen Stelle oder verknäueln sie sich selbst, kann der Test fehlschlagen oder irreführende Ergebnisse liefern. Traditionelle Primer-Design-Programme folgen festen Regeln zu Primerlänge, chemischer Zusammensetzung und einfachen Stabilitätsprüfungen. Diese Regeln sind nützlich, behandeln jedoch jedes Merkmal weitgehend isoliert, sodass Wissenschaftler viele Details manuell prüfen und abschätzen müssen, wie Kombinationen von Merkmalen in realen Experimenten zusammenwirken.
Reale und fehlerhafte Designs in Trainingsmaterial verwandeln
Die Forscher bauten PrimerAST, indem sie zunächst eine sorgfältig beschriftete Sammlung von Primern zusammenstellten. Sie starteten mit realen genetischen Varianten im menschlichen Erbgut, extrahierten die umliegende Sequenz und nutzten ein verbreitetes Design-Tool, um Primerpaare unter realistischen Bedingungen für medizinische Tests zu erzeugen. Jedes dieser Primerpaare wurde dann im Labor unter Standard-PCR-Bedingungen getestet. Paare, die saubere, spezifische DNA-Produkte erzeugten, wurden als funktionierend gekennzeichnet, andere schlugen fehl und wurden verworfen. Um dem System beizubringen, wie schlechte Primer aussehen, erzeugte das Team zusätzlich synthetische Fehler, indem sie Schlüsselparameter bewusst außerhalb sicherer Bereiche verschoben — etwa Primer mit zu hohem oder zu niedrigem Anteil bestimmter Basen, lange Wiederholungssequenzen derselben Base oder zu viele natürliche DNA-Varianten nahe dem Bindungsende.
Wesentliche Primer-Eigenschaften ins Machine Learning einspeisen
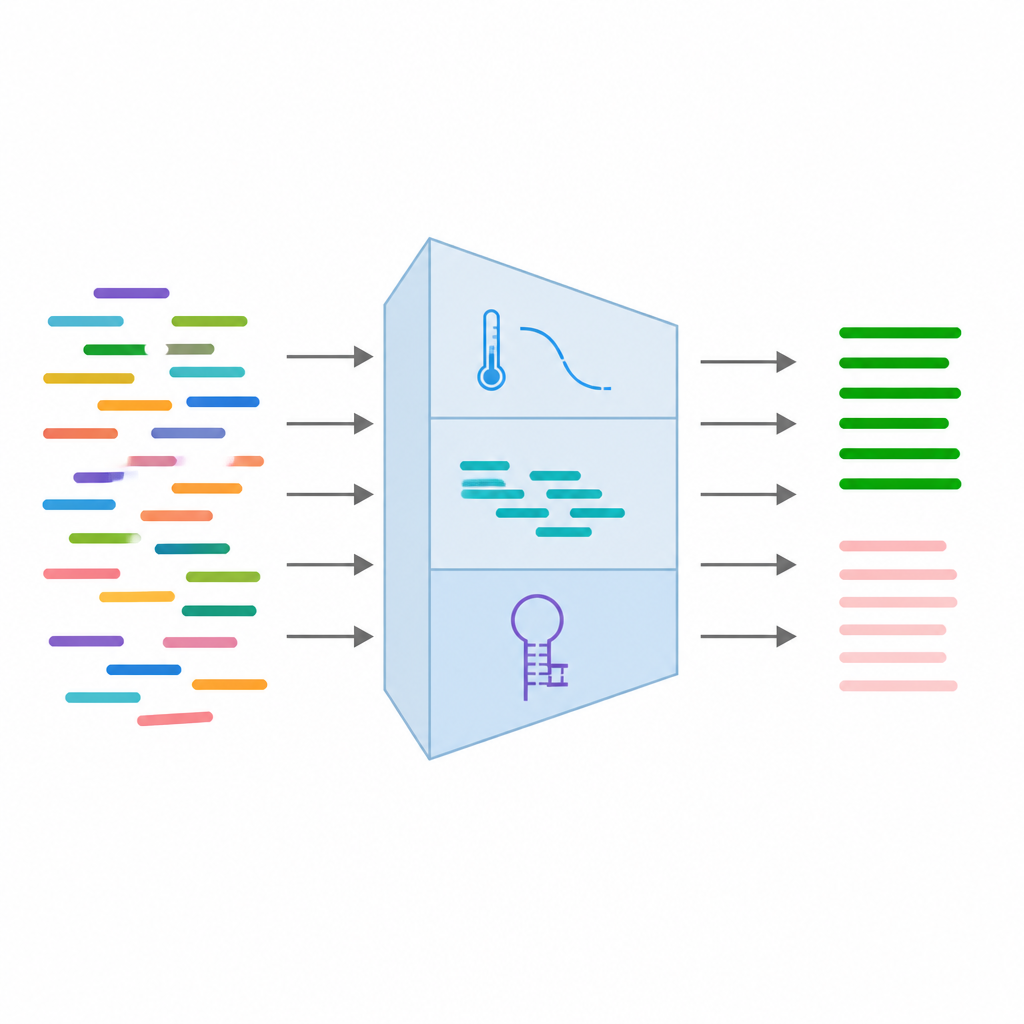
Von jedem Primerpaar sammelte das Team 24 verschiedene Messgrößen, die erfassen, wie es sich voraussichtlich verhält. Dazu gehören grundlegende Sequenzmerkmale wie Länge und Basenausgleich, thermodynamische Eigenschaften im Zusammenhang mit der Bindungsstärke und strukturelle Merkmale, die zeigen, ob sich Primer zurückfalten oder aneinander kleben könnten. Zusätzlich wurden Informationen über bekannte DNA-Varianten an der Bindungsstelle und Ergebnisse aus simulierten PCR-Läufen hinzugefügt, die prüfen, ob die Primer versehentlich an anderen Stellen im Genom passen. Nach Bereinigung und Filterung der Daten behielten sie 16 der zuverlässigsten Merkmale und standardisierten diese, damit keine einzelne Messgröße den Lernprozess dominierte.
Den Computer lehren, Gut von Schlecht zu unterscheiden
Mit diesen 16 Merkmalen trainierten die Autoren mehrere Arten überwachter Machine-Learning-Modelle, darunter logistische Regression, Random Forests, Support Vector Machines und Gradient Boosting. Sie verwendeten insgesamt 315 Primerpaare, aufgeteilt in Trainings- und Testmengen, und bewerteten die Modelle mit üblichen Genauigkeitsmetriken und Kurven, die messen, wie gut die Werkzeuge funktionierende von fehlerhaften Primern unterscheiden. Alle vier Modelle zeigten starke Leistungen, einige erreichten Genauigkeiten über 93 Prozent und sehr hohe Werte bei der Trennung der beiden Klassen. Auffällig waren Unterschiede im Temperaturgleichgewicht zwischen Primerpartnern, die Länge wiederholter Basen und die Anzahl natürlicher Varianten als entscheidende Einflussfaktoren für den Erfolg eines Primers. Auf Basis dieser Ergebnisse wurde das beste Modell in ein benutzerfreundliches Web-Tool integriert, das eine genetische Variante als Eingabe nimmt, Kandidaten-Primer entwirft und sie sofort bewertet.
Was das für die zukünftige DNA-Testung bedeutet
Für Wissenschaftler und Kliniker, die auf PCR angewiesen sind, fungiert PrimerAST wie ein intelligenter Filter, der viele Primeroptionen sichtet und diejenigen hervorhebt, die am wahrscheinlichsten funktionieren, noch bevor jemand ins Labor geht. Indem es Muster über mehrere Primer-Eigenschaften hinweg lernt statt sich nur auf starre Regeln zu stützen, kann das Tool Versuch-und-Irrtum reduzieren, Kosten senken und die Entwicklung von DNA-Tests für neue genetische Varianten beschleunigen. Obwohl es die tatsächliche Laborvalidierung nicht ersetzt und weiterhin mit mehr realen Daten wachsen muss, zeigt PrimerAST, wie die Kombination von DNA-Design und Machine Learning die alltägliche molekulare Diagnostik effizienter und zuverlässiger machen kann.
Zitation: Al-Mahrami, N., Al Yazidi, S., Alrashdi, H. et al. PrimerAST: A predictive machine learning tool for primer design and quality assessment. Sci Rep 16, 14980 (2026). https://doi.org/10.1038/s41598-026-38238-8
Schlüsselwörter: PCR-Primer, Primer-Design, Machine Learning, Bioinformatik-Werkzeug, Genetische Tests