Clear Sky Science · ru
PrimerAST: предиктивный инструмент машинного обучения для проектирования праймеров и оценки их качества
Почему важны более умные инструменты тестирования
От отслеживания вспышек до диагностики генетических заболеваний — множество лабораторных тестов опираются на универсальный метод ПЦР, который копирует крошечные фрагменты ДНК, чтобы их можно было обнаружить. Успех этих тестов зависит от коротких фрагментов ДНК, называемых праймерами, которые указывают копирующему механизму, где начать. Проектирование хороших праймеров оказывается удивительно сложным и часто требует проб и ошибок на лабораторной скамье. В этом исследовании представлен PrimerAST — программный инструмент, использующий машинное обучение, чтобы помочь учёным быстро отбирать сильные кандидаты на праймеры из слабых, экономя время, деньги и уменьшая разочарование при тестировании ДНК.
Проблема выбора правильных стартовых сегментов ДНК
Праймеры — короткие участки ДНК, которые должны точно связываться с выбранным местом в геноме, прежде чем начнётся ПЦР. Если они связываются слишком слабо, с неправильного участка или образуют запутывания сами с собой, тест может провалиться или дать искажённые результаты. Традиционные программы проектирования праймеров следуют фиксированным правилам по длине праймера, химическому составу и простым проверкам стабильности. Эти правила полезны, но рассматривают каждое свойство в основном по отдельности, оставляя учёным необходимость вручную проверять множество деталей и предполагать, как комбинации признаков поведут себя в реальных экспериментах.
Преобразование реальных и ошибочных дизайнов в обучающий материал
Авторы создали PrimerAST, сначала собрав тщательно размеченную коллекцию праймеров. Они начали с реальных генетических вариантов в человеческой ДНК, извлекли окружающие последовательности и использовали популярный инструмент проектирования, чтобы сгенерировать пары праймеров при реалистичных настройках для медицинского тестирования. Каждая из этих пар праймеров затем была испытана в лаборатории при стандартных условиях ПЦР. Наборы, которые давали чистые, специфичные продукты ДНК, были помечены как работоспособные, в то время как остальные не прошли и были отбрасыаны. Чтобы показать системе, как выглядят плохие праймеры, команда также создала синтетические неудачи, намеренно смещая ключевые свойства за пределы безопасных интервалов — например, делая праймеры слишком богатыми или слишком бедными определёнными основаниями, допуская длинные повторы одинаковых нуклеотидов или размещая слишком много природных вариантов ДНК рядом с концевым участком связывания.
Подача ключевых свойств праймеров в машинное обучение
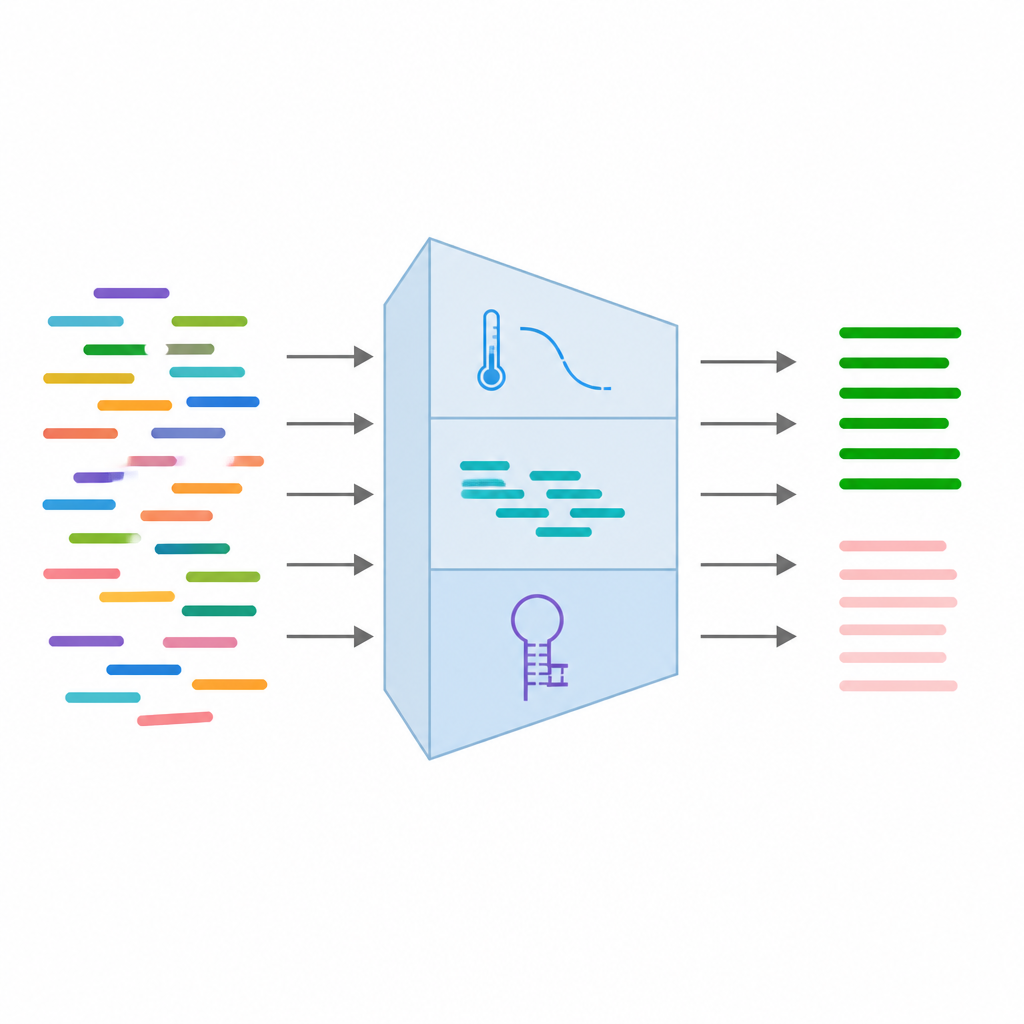
Из каждой пары праймеров команда собрала 24 различных измерения, отражающих ожидаемое поведение. Сюда входят базовые признаки последовательности, такие как длина и соотношение оснований, термодинамические характеристики, связанные с силой связывания праймеров, и структурные признаки, показывающие, склонны ли они сворачиваться или слипаться друг с другом. Также добавили информацию о известных вариантах ДНК в месте связывания и результаты симулированных запусков ПЦР, которые проверяют, не совпадают ли праймеры случайно с другими участками генома. После очистки и фильтрации данных сохранили 16 наиболее надёжных признаков и стандартизировали их, чтобы ни одно отдельное измерение не доминировало в процессе обучения.
Обучение компьютера отличать хорошие праймеры от плохих
С этими 16 признаками авторы обучили несколько типов моделей контролируемого машинного обучения, включая логистическую регрессию, случайные леса, опорные векторы и градиентный бустинг. Всего использовали 315 пар праймеров, разделённых на обучающую и тестовую выборки, и оценивали модели с помощью общепринятых метрик точности и кривых, измеряющих способность инструментов различать работоспособные и неработоспособные праймеры. Все четыре модели показали высокие результаты: некоторые достигали точности выше 93 процентов и очень хорошей раздельной способности классов. Отметились такие факторы, как различия в температурном балансе между партнёрами по праймеру, длина повторяющихся оснований и количество природных вариантов — они существенно влияли на вероятность успеха праймера. На основе этих результатов лучшая модель была интегрирована в удобный веб-инструмент, который принимает на вход генетический вариант, проектирует кандидатов в праймеры и мгновенно их оценивает.
Что это значит для будущих ДНК-тестов
Для учёных и клиницистов, которые полагаются на ПЦР, PrimerAST действует как умный фильтр, который просеивает множество вариантов праймеров и выделяет те, которые с наибольшей вероятностью сработают, ещё до выхода в лабораторию. Обучаясь на шаблонах, объединяющих несколько признаков праймеров, а не полагаясь только на жёсткие правила, инструмент может сократить число проб и ошибок, снизить затраты и ускорить разработку тестов ДНК для новых генетических вариантов. Хотя он не заменяет лабораторную валидацию и всё ещё нуждается в пополнении данных из реальной практики, PrimerAST демонстрирует, как сочетание проектирования ДНК и машинного обучения может сделать повседневную молекулярную диагностику более эффективной и надёжной.
Цитирование: Al-Mahrami, N., Al Yazidi, S., Alrashdi, H. et al. PrimerAST: A predictive machine learning tool for primer design and quality assessment. Sci Rep 16, 14980 (2026). https://doi.org/10.1038/s41598-026-38238-8
Ключевые слова: ПЦР-праймеры, проектирование праймеров, машинное обучение, биоинформатический инструмент, генетическое тестирование