Clear Sky Science · fr
PrimerAST : un outil d’apprentissage automatique prédictif pour la conception et l’évaluation de la qualité des amorces
Pourquoi des outils de test plus intelligents comptent
Du suivi des foyers épidémiques au diagnostic de maladies génétiques, d’innombrables tests de laboratoire reposent sur une méthode de base appelée PCR, qui copie de très petites quantités d’ADN pour permettre leur détection. Le succès de ces tests dépend de courts fragments d’ADN appelés amorces qui indiquent à la machinerie de copie où commencer. Concevoir de bonnes amorces est étonnamment complexe et implique souvent des essais-erreurs au banc de laboratoire. Cette étude présente PrimerAST, un outil informatique qui utilise l’apprentissage automatique pour aider les scientifiques à trier rapidement les candidats-amorces robustes des plus faibles, économisant temps, argent et frustration dans le dépistage d’ADN.
Le défi de choisir les bons démarreurs d’ADN
Les amorces sont de courts segments d’ADN qui doivent se lier précisément à un emplacement choisi du génome avant que la PCR puisse commencer. Si elles se lient trop faiblement, au mauvais endroit, ou forment des structures indésirables entre elles, le test peut échouer ou fournir des résultats trompeurs. Les programmes traditionnels de conception d’amorces suivent des règles fixes concernant la longueur, la composition chimique et des vérifications simples de stabilité. Ces règles sont utiles mais traitent chaque caractéristique séparément, laissant les scientifiques examiner de nombreux détails manuellement et deviner comment les combinaisons de traits se comporteront ensemble en conditions expérimentales réelles.
Transformer des conceptions réelles et défaillantes en matériel d’entraînement
Les chercheurs ont construit PrimerAST en assemblant d’abord une collection soigneusement annotée d’amorces. Ils sont partis de variantes génétiques réelles dans l’ADN humain, ont extrait la séquence environnante, et ont utilisé un outil de conception populaire pour générer des paires d’amorces selon des paramètres réalistes pour les tests médicaux. Chacune de ces paires a ensuite été testée au laboratoire en conditions PCR standard. Les ensembles produisant des produits d’ADN propres et spécifiques ont été étiquetés comme fonctionnels, tandis que les autres ont échoué et ont été écartés. Pour apprendre au système à reconnaître les mauvaises amorces, l’équipe a aussi créé des échecs synthétiques en repoussant délibérément des propriétés clés en dehors des plages sûres, par exemple en rendant les amorces trop riches ou trop pauvres en certaines bases, en autorisant de longues répétitions d’un même nucléotide, ou en plaçant trop de variations naturelles d’ADN près de l’extrémité de liaison.
Alimenter l’apprentissage automatique avec les traits clés des amorces
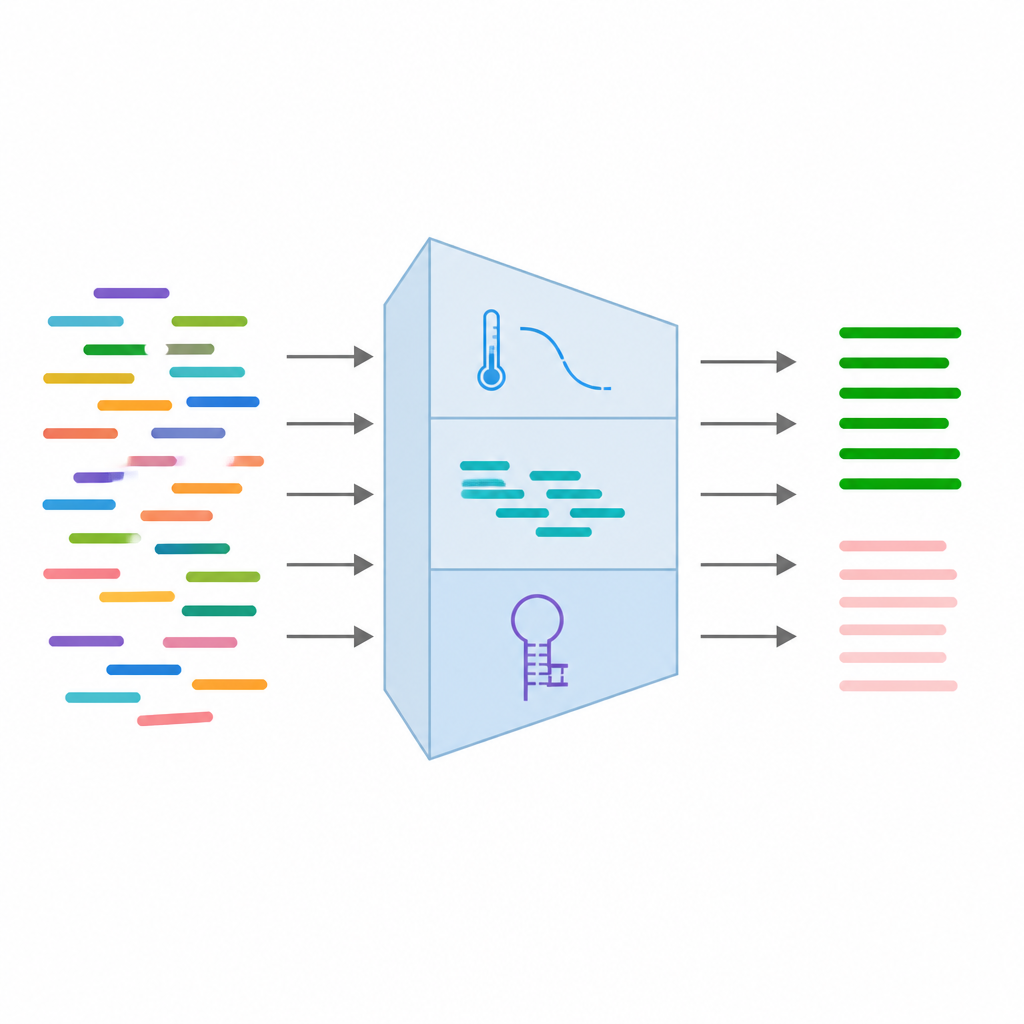
Pour chaque paire d’amorces, l’équipe a recueilli 24 mesures différentes qui capturent leur comportement attendu. Celles-ci incluent des caractéristiques de séquence de base comme la longueur et l’équilibre des bases, des caractéristiques thermodynamiques liées à la force d’appairage, et des traits structuraux révélant la propension à se replier sur elles-mêmes ou à s’agglutiner. Ils ont aussi ajouté des informations sur des variantes d’ADN connues au site de liaison et des résultats de simulations de PCR vérifiant si les amorces s’alignent accidentellement sur d’autres endroits du génome. Après nettoyage et filtrage des données, ils ont conservé 16 des caractéristiques les plus fiables et les ont standardisées pour qu’aucune mesure unique ne domine le processus d’apprentissage.
Apprendre à l’ordinateur à distinguer le bon du mauvais
Avec ces 16 caractéristiques, les auteurs ont entraîné plusieurs types de modèles d’apprentissage supervisé, y compris la régression logistique, les forêts aléatoires, les machines à vecteurs de support et le gradient boosting. Ils ont utilisé au total 315 paires d’amorces, réparties en jeux d’entraînement et de test, et ont évalué les modèles à l’aide de scores d’exactitude classiques et de courbes mesurant la capacité à séparer les amorces fonctionnelles des défaillantes. Les quatre modèles ont donné de bonnes performances, certains atteignant plus de 93 % de précision et des scores très élevés pour la séparation nette des deux classes. De façon notable, les différences d’équilibre de température entre partenaires d’amorce, la longueur des répétitions de bases et le nombre de variantes naturelles ont fortement influencé la probabilité de succès d’une amorce. Sur la base de ces résultats, le meilleur modèle a été intégré dans un outil web convivial qui prend une variante génétique en entrée, conçoit des amorces candidates et les note instantanément.
Ce que cela signifie pour les tests ADN à venir
Pour les scientifiques et cliniciens qui s’appuient sur la PCR, PrimerAST agit comme un filtre intelligent qui scrute de nombreuses options d’amorces et met en évidence celles les plus susceptibles de fonctionner avant qu’une expérience en laboratoire ne commence. En apprenant à partir de motifs combinant plusieurs traits d’amorces plutôt que de règles rigides seules, l’outil peut réduire les essais-erreurs, diminuer les coûts et accélérer la conception de tests ADN pour de nouvelles variantes génétiques. Bien qu’il ne remplace pas la validation expérimentale en laboratoire et doive encore s’enrichir de données issues du monde réel, PrimerAST montre comment la combinaison de la conception d’ADN et de l’apprentissage automatique peut rendre la diagnostic moléculaire courant plus efficace et plus fiable.
Citation: Al-Mahrami, N., Al Yazidi, S., Alrashdi, H. et al. PrimerAST: A predictive machine learning tool for primer design and quality assessment. Sci Rep 16, 14980 (2026). https://doi.org/10.1038/s41598-026-38238-8
Mots-clés: amorces PCR, conception d’amorces, apprentissage automatique, outil de bioinformatique, dépistage génétique