Clear Sky Science · it
PrimerAST: uno strumento predittivo di machine learning per la progettazione e la valutazione della qualità dei primer
Perché sono importanti strumenti di test più intelligenti
Dalla sorveglianza delle epidemie alla diagnosi di condizioni genetiche, innumerevoli test di laboratorio si basano su un metodo fondamentale chiamato PCR, che copia piccole quantità di DNA per renderle rilevabili. Il successo di questi test dipende da brevi frammenti di DNA detti primer, che indicano alla macchina che copia dove iniziare. Progettare primer efficaci è sorprendentemente difficile e spesso richiede tentativi ed errori al banco di laboratorio. Questo studio presenta PrimerAST, uno strumento informatico che utilizza il machine learning per aiutare gli scienziati a distinguere rapidamente i candidati primer forti da quelli deboli, risparmiando tempo, denaro e frustrazione nelle analisi del DNA.
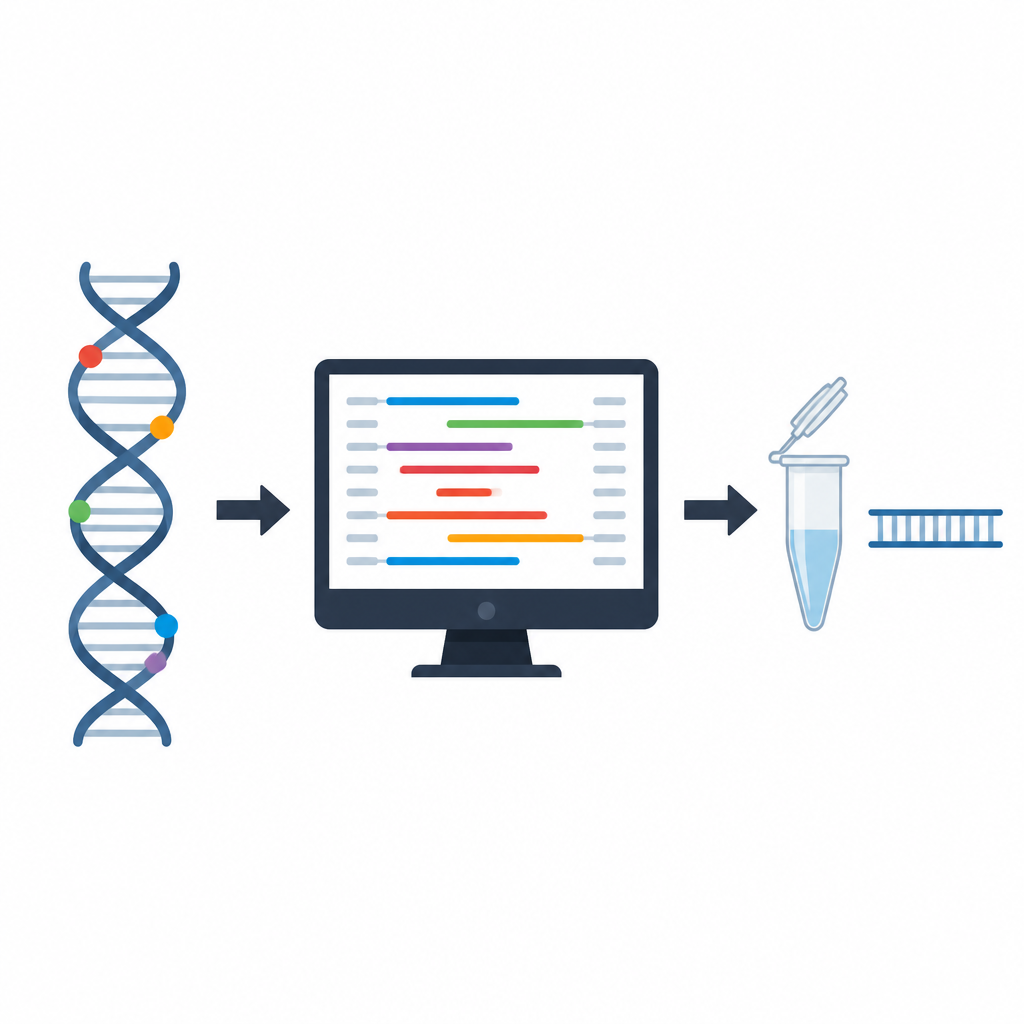
La sfida di scegliere gli iniziatori di DNA giusti
I primer sono brevi tratti di DNA che devono legarsi con precisione a un punto scelto del genoma prima che la PCR possa iniziare. Se si legano troppo debolmente, nel posto sbagliato o formano intrecci con se stessi, il test può fallire o dare risultati fuorvianti. I programmi tradizionali di progettazione dei primer seguono regole fisse sulla lunghezza del primer, la composizione chimica e controlli di stabilità semplici. Queste regole sono utili ma considerano ogni caratteristica per lo più isolatamente, lasciando agli scienziati l'ispezione manuale di molti dettagli e il compito di indovinare come le combinazioni di caratteristiche si comporteranno insieme negli esperimenti reali.
Trasformare progetti reali e fallimentari in materiale di addestramento
I ricercatori hanno costruito PrimerAST assemblando innanzitutto una collezione attentamente etichettata di primer. Sono partiti da varianti genetiche reali nel DNA umano, hanno estratto la sequenza circostante e hanno usato uno strumento di progettazione diffuso per generare coppie di primer con impostazioni realistiche per test diagnostici. Ciascuna di queste coppie di primer è stata poi provata in laboratorio usando condizioni standard di PCR. I set che producevano prodotti di DNA puliti e specifici sono stati etichettati come funzionanti, mentre gli altri sono falliti ed esclusi. Per insegnare al sistema cosa costituisce un primer cattivo, il team ha anche creato fallimenti sintetici spingendo deliberatamente proprietà chiave fuori da intervalli sicuri, ad esempio rendendo i primer troppo ricchi o troppo poveri in alcune basi, permettendo run lunghi della stessa lettera o collocando troppe varianti naturali vicino all'estremità di legame.
Inserire le caratteristiche chiave dei primer nel machine learning
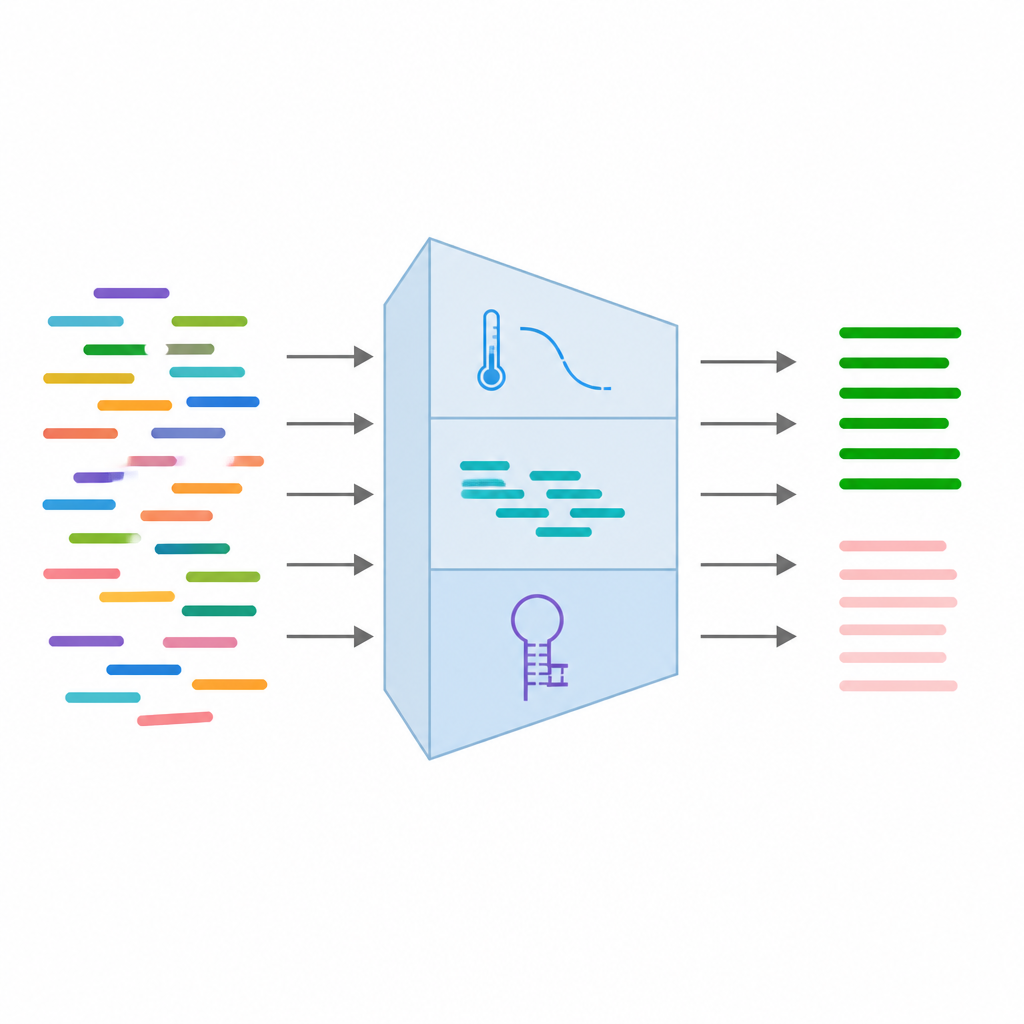
Da ogni coppia di primer, il team ha raccolto 24 diverse misure che catturano il loro comportamento previsto. Queste includono caratteristiche di sequenza di base come lunghezza ed equilibrio delle basi, tratti termodinamici legati all'affinità di legame dei primer e caratteristiche strutturali che rivelano se è probabile che si ripieghino su se stessi o si attacchino l'uno all'altro. Hanno inoltre aggiunto informazioni su varianti note nel sito di legame e risultati da simulazioni di PCR che verificano se i primer si abbinano accidentalmente ad altre posizioni nel genoma. Dopo la pulizia e il filtraggio dei dati, hanno mantenuto 16 delle caratteristiche più affidabili e le hanno standardizzate in modo che nessuna singola misura dominasse il processo di apprendimento.
Insegnare al computer a distinguere buoni da cattivi
Con queste 16 caratteristiche, gli autori hanno addestrato diversi tipi di modelli di apprendimento supervisionato, inclusi regressione logistica, foreste casuali, macchine a vettori di supporto e gradient boosting. Hanno usato in totale 315 coppie di primer, suddivise in set di addestramento e di test, e hanno valutato i modelli usando punteggi di accuratezza comuni e curve che misurano quanto bene gli strumenti distinguono i primer funzionanti da quelli fallimentari. Tutti e quattro i modelli hanno mostrato prestazioni robuste, con alcuni che hanno raggiunto un'accuratezza superiore al 93% e punteggi molto alti sulla separazione netta delle due classi. In particolare, le differenze nell'equilibrio termico tra i partner di primer, la lunghezza di basi ripetute e il numero di varianti naturali hanno influenzato fortemente la probabilità di successo di un primer. Sulla base di questi risultati, il modello migliore è stato integrato in uno strumento web user-friendly che prende in input una variante genetica, progetta primer candidati e li valuta istantaneamente.
Cosa significa per il futuro dei test sul DNA
Per scienziati e clinici che si affidano alla PCR, PrimerAST funge da filtro intelligente che esamina molte opzioni di primer e mette in evidenza quelle con maggiori probabilità di funzionare prima che qualcuno entri in laboratorio. Imparando da pattern che coinvolgono molteplici caratteristiche dei primer piuttosto che da regole rigidamente definite, lo strumento può ridurre tentativi ed errori, abbattere i costi e accelerare la progettazione di test del DNA per nuove varianti genetiche. Pur non sostituendo la convalida sperimentale in laboratorio e avendo ancora bisogno di crescere con più dati reali, PrimerAST dimostra come combinare la progettazione del DNA con il machine learning possa rendere la diagnostica molecolare di tutti i giorni più efficiente e affidabile.
Citazione: Al-Mahrami, N., Al Yazidi, S., Alrashdi, H. et al. PrimerAST: A predictive machine learning tool for primer design and quality assessment. Sci Rep 16, 14980 (2026). https://doi.org/10.1038/s41598-026-38238-8
Parole chiave: Primer PCR, progettazione dei primer, machine learning, strumento di bioinformatica, test genetici