Clear Sky Science · pt
PrimerAST: Uma ferramenta preditiva de aprendizado de máquina para projeto e avaliação de qualidade de primers
Por que ferramentas de teste mais inteligentes importam
Desde acompanhar surtos até diagnosticar condições genéticas, inúmeros testes laboratoriais dependem de um método central chamado PCR, que copia quantidades ínfimas de DNA para que possam ser detectadas. O sucesso desses testes depende de pequenos trechos de DNA chamados primers que dizem à maquinaria de cópia onde começar. Projetar bons primers é surpreendentemente difícil e muitas vezes envolve tentativa e erro no laboratório. Este estudo apresenta o PrimerAST, uma ferramenta computacional que usa aprendizado de máquina para ajudar cientistas a separar rapidamente candidatos fortes de candidatos fracos, poupando tempo, dinheiro e frustração nos testes de DNA.
O desafio de escolher os iniciadores de DNA certos
Primers são trechos curtos de DNA que devem se ligar precisamente a um ponto escolhido no genoma antes que a PCR possa começar. Se se ligarem de forma muito fraca, no lugar errado ou formarem emaranhados entre si, o teste pode falhar ou dar resultados enganosos. Programas tradicionais de projeto de primers seguem regras fixas sobre comprimento do primer, composição química e verificações simples de estabilidade. Essas regras são úteis, mas tratam cada característica de forma bastante isolada, deixando os cientistas inspecionarem muitos detalhes manualmente e adivinharem como combinações de características se comportarão juntas em experimentos reais.
Transformando projetos reais e falhos em material de treinamento
Os pesquisadores construíram o PrimerAST primeiro reunindo uma coleção cuidadosamente rotulada de primers. Eles partiram de variantes genéticas reais no DNA humano, extrairam a sequência ao redor e usaram uma ferramenta de projeto popular para gerar pares de primers sob configurações realistas para testes médicos. Cada um desses pares de primers foi então testado em laboratório usando condições padrão de PCR. Conjuntos que produziram produtos de DNA limpos e específicos foram rotulados como funcionais, enquanto outros falharam e foram descartados. Para ensinar ao sistema como são os primers ruins, a equipe também criou falhas sintéticas forçando deliberadamente propriedades-chave para além das faixas seguras, como tornar os primers muito ricos ou pobres em certas bases, permitir longas repetições da mesma letra ou posicionar muitas variantes naturais perto da extremidade de ligação.
Alimentando traços-chave dos primers no aprendizado de máquina
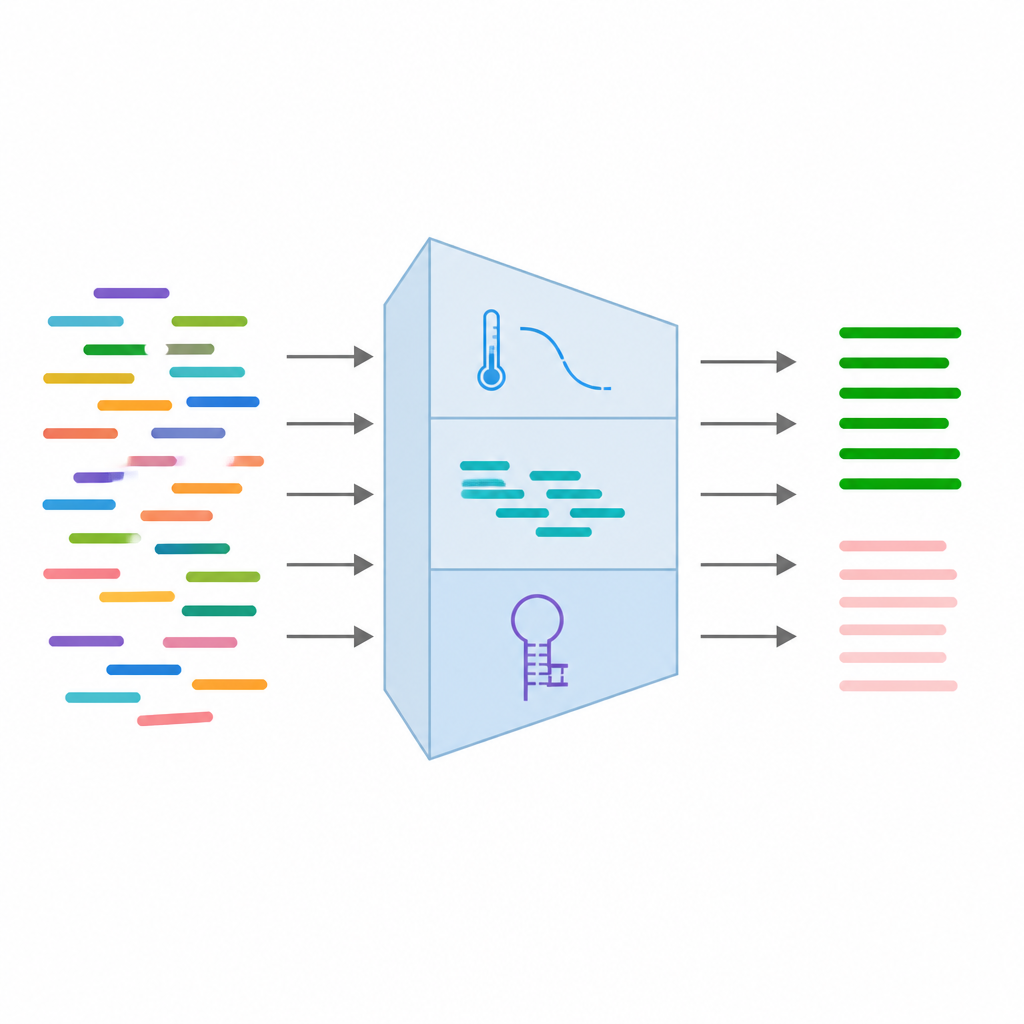
De cada par de primers, a equipe coletou 24 medições diferentes que capturam como se espera que eles se comportem. Isso inclui características básicas de sequência como comprimento e equilíbrio de bases, características termodinâmicas relacionadas ao quão firmemente os primers se ligam, e características estruturais que revelam se eles provavelmente se dobrarão sobre si mesmos ou se aderirão uns aos outros. Também adicionaram informações sobre variantes de DNA conhecidas no sítio de ligação e resultados de simulações de PCR que verificam se os primers acidentalmente correspondem a outros locais do genoma. Após limpar e filtrar os dados, mantiveram 16 das características mais confiáveis e as padronizaram para que nenhuma medição isolada dominasse o processo de aprendizado.
Ensinando o computador a distinguir bom de ruim
Com essas 16 características, os autores treinaram vários tipos de modelos supervisionados de aprendizado de máquina, incluindo regressão logística, florestas aleatórias, máquinas de vetor de suporte e gradient boosting. Usaram 315 pares de primers no total, divididos em conjuntos de treinamento e teste, e avaliaram os modelos usando medidas comuns de acurácia e curvas que medem quão bem as ferramentas distinguem primers funcionais de falhos. Todos os quatro modelos apresentaram desempenho forte, com alguns alcançando acurácia acima de 93% e pontuações muito altas na separação limpa das duas classes. Notavelmente, diferenças no equilíbrio de temperatura entre parceiros de primer, o comprimento de bases repetidas e o número de variantes naturais influenciaram fortemente se um primer tinha probabilidade de sucesso. Com base nesses resultados, o melhor modelo foi integrado a uma ferramenta web amigável que recebe uma variante genética como entrada, projeta primers candidatos e os pontua instantaneamente.
O que isso significa para futuros testes de DNA
Para cientistas e clínicos que dependem de PCR, o PrimerAST funciona como um filtro inteligente que triageia muitas opções de primer e destaca aquelas com maior probabilidade de funcionar antes de qualquer pessoa entrar no laboratório. Ao aprender padrões através de múltiplas características de primers em vez de regras rígidas isoladas, a ferramenta pode reduzir tentativa e erro, cortar custos e acelerar o desenho de testes de DNA para novas variantes genéticas. Embora não substitua a validação laboratorial real e ainda precise crescer com mais dados do mundo real, o PrimerAST demonstra como a combinação de projeto de DNA com aprendizado de máquina pode tornar o diagnóstico molecular cotidiano mais eficiente e confiável.
Citação: Al-Mahrami, N., Al Yazidi, S., Alrashdi, H. et al. PrimerAST: A predictive machine learning tool for primer design and quality assessment. Sci Rep 16, 14980 (2026). https://doi.org/10.1038/s41598-026-38238-8
Palavras-chave: Primers de PCR, projeto de primers, aprendizado de máquina, ferramenta de bioinformática, testes genéticos