Clear Sky Science · sv
PrimerAST: Ett prediktivt maskininlärningsverktyg för primerdesign och kvalitetsbedömning
Varför smartare testverktyg är viktiga
Från att spåra utbrott till att diagnostisera genetiska tillstånd: otaliga labbtester bygger på en väl beprövad metod kallad PCR, som kopierar små mängder DNA så att de kan detekteras. Framgången för dessa tester avgörs av korta DNA‑stycken kallade primers som talar om för kopieringsmaskineriet var det ska börja. Att designa bra primers är förvånansvärt knepigt och involverar ofta trial and error vid bänken. Denna studie introducerar PrimerAST, ett datorverktyg som använder maskininlärning för att hjälpa forskare att snabbt sortera starka primerkandidater från svaga, vilket sparar tid, pengar och frustration vid DNA‑testning.
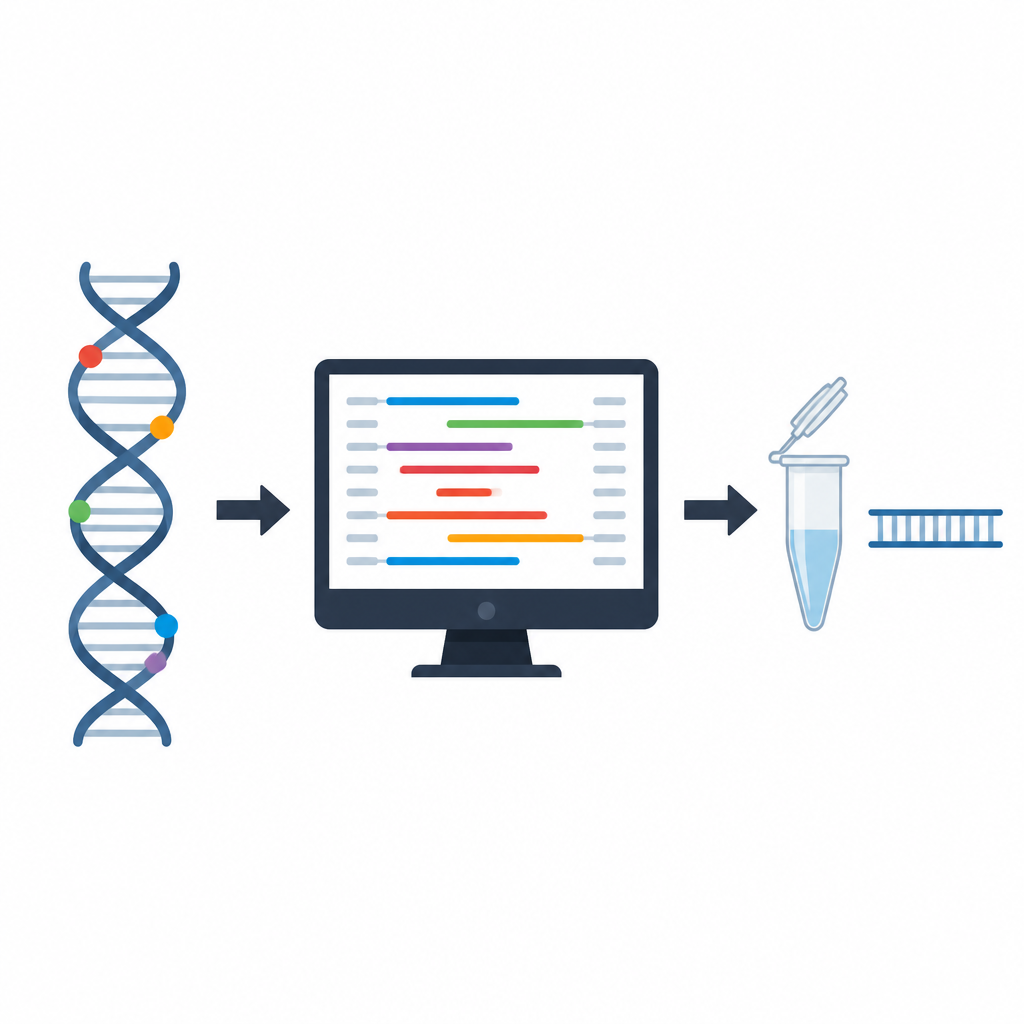
Utmaningen att välja rätt DNA‑startare
Primers är korta DNA‑sekvenser som måste binda precist till en utvald plats i genomet innan PCR kan börja. Om de binder för löst, till fel plats eller bildar trassel med sig själva kan testet misslyckas eller ge missvisande resultat. Traditionella primerdesignprogram följer fasta regler om primerlängd, kemisk sammansättning och enkla stabilitetskontroller. Dessa regler är användbara men behandlar varje egenskap i stor utsträckning för sig, vilket lämnar forskare att granska många detaljer manuellt och gissa hur kombinationer av egenskaper kommer att bete sig i verkliga experiment.
Att omvandla verkliga och felaktiga designer till träningsmaterial
Forskarna byggde PrimerAST genom att först sammanställa en noggrant märkt samling primers. De utgick från verkliga genetiska varianter i mänskligt DNA, tog ut omgivande sekvens och använde ett populärt designverktyg för att generera primerpar under realistiska inställningar för medicinsk testning. Varje primerpar provades sedan i labbet med standard PCR‑förhållanden. De uppsättningar som gav rena, specifika DNA‑produkter märktes som fungerande, medan andra misslyckades och avvisades. För att lära systemet hur dåliga primers ser ut skapade teamet också syntetiska fel genom att medvetet pressa nyckelegenskaper utanför säkra intervall, som att göra primers för rika eller för fattiga på vissa baser, tillåta långa sekvenser av samma bokstav eller placera för många naturliga DNA‑varianter nära bindande änden.
Mata in viktiga primeregenskaper i maskininlärning
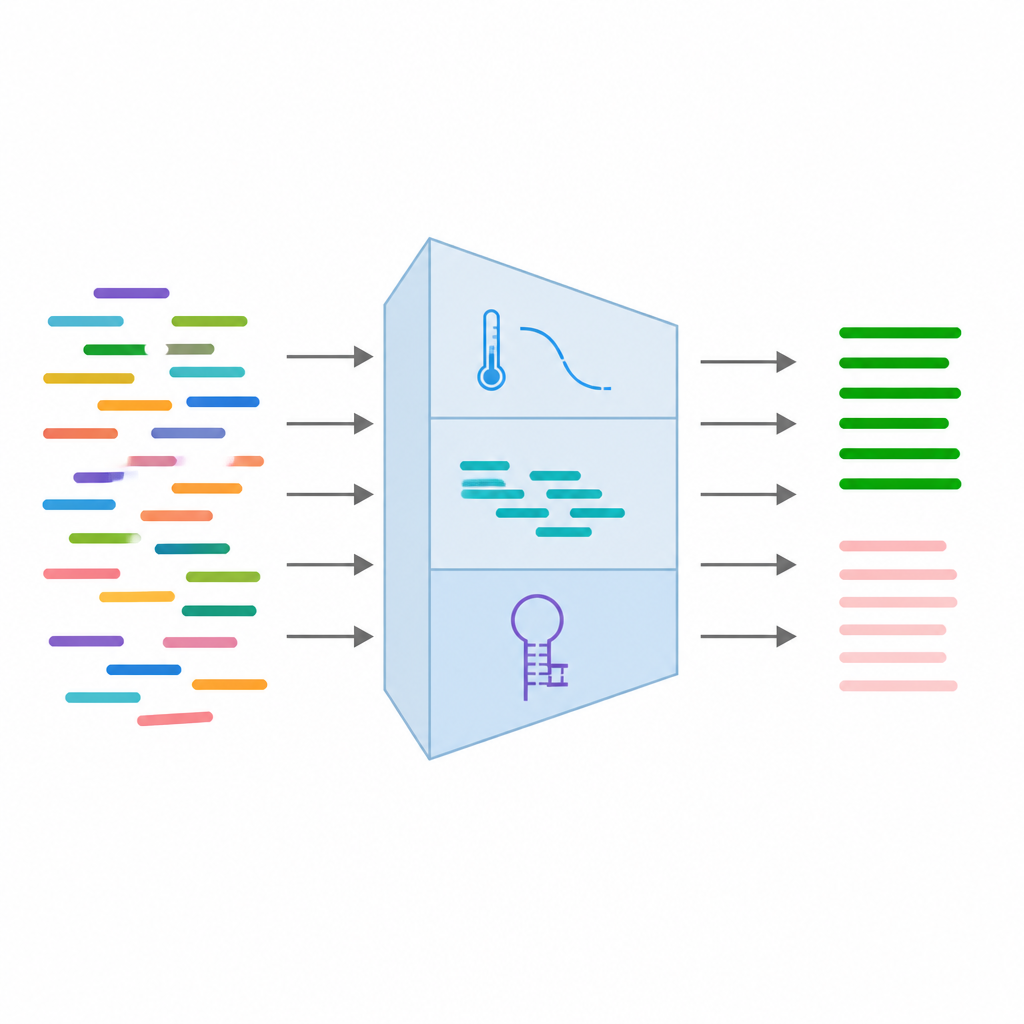
Från varje primerpar samlade teamet 24 olika mätvärden som fångar hur det förväntas bete sig. Dessa inkluderar grundläggande sekvensegenskaper som längd och basbalans, termodynamiska egenskaper relaterade till hur hårt primers binder, och strukturella egenskaper som visar om de sannolikt veckar tillbaka på sig själva eller fastnar i varandra. De lade också till information om kända DNA‑varianter vid bindningsstället och resultat från simulerade PCR‑körningar som kontrollerar om primers av misstag matchar andra platser i genomet. Efter rensning och filtrering av data behölls 16 av de mest tillförlitliga funktionerna och standardiserades så att inget enskilt mått skulle dominera inlärningsprocessen.
Att lära datorn skilja gott från dåligt
Med dessa 16 funktioner tränade författarna flera typer av övervakade maskininlärningsmodeller, inklusive logistisk regression, random forests, supportvektormaskiner och gradientboosting. De använde totalt 315 primerpar, delade i tränings‑ och testuppsättningar, och utvärderade modellerna med vanliga noggrannhetsskalor och kurvor som mäter hur väl verktygen skiljer fungerande från misslyckade primers. Alla fyra modeller presterade starkt, med vissa som nådde över 93 procents noggrannhet och mycket höga poäng för hur tydligt de separerar de två klasserna. Skillnader i temperaturbalans mellan primerpartners, längden på upprepade baser och antalet naturliga varianter påverkade särskilt starkt om en primer sannolikt skulle lyckas. Baserat på dessa resultat integrerades den bästa modellen i ett användarvänligt webbverktyg som tar en genetisk variant som indata, designar kandidatprimers och omedelbart poängsätter dem.
Vad detta betyder för framtida DNA‑testning
För forskare och kliniker som litar på PCR fungerar PrimerAST som ett smart filter som screenar många primeralternativ och framhäver dem som mest sannolikt fungerar innan någon går in i labbet. Genom att lära av mönster över flera primeregenskaper snarare än enbart rigida regler kan verktyget minska trial and error, sänka kostnader och snabba på designen av DNA‑tester för nya genetiska varianter. Även om det inte ersätter faktisk laboratorieverifiering och fortfarande behöver växa med mer verkliga data, visar PrimerAST hur kombinationen av DNA‑design och maskininlärning kan göra vardaglig molekylärdiagnostik mer effektiv och tillförlitlig.
Citering: Al-Mahrami, N., Al Yazidi, S., Alrashdi, H. et al. PrimerAST: A predictive machine learning tool for primer design and quality assessment. Sci Rep 16, 14980 (2026). https://doi.org/10.1038/s41598-026-38238-8
Nyckelord: PCR-primers, primerdesign, maskininlärning, bioinformatikverktyg, genetisk testning