Clear Sky Science · pl
PrimerAST: narzędzie uczenia maszynowego do prognozowania projektowania starterów i oceny jakości
Dlaczego ważne są mądrzejsze narzędzia testowe
Od śledzenia epidemii po diagnostykę schorzeń genetycznych, niezliczone badania laboratoryjne opierają się na powszechnej metodzie zwanej PCR, która powiela niewielkie ilości DNA, aby można je było wykryć. Powodzenie tych testów zależy od krótkich fragmentów DNA zwanych starterami, które wskazują maszynerii kopiującej, gdzie zaczynać. Zaprojektowanie dobrych starterów jest zaskakująco trudne i często wymaga prób i błędów przy ławce laboratoryjnej. W tym badaniu przedstawiono PrimerAST, narzędzie komputerowe wykorzystujące uczenie maszynowe, które pomaga naukowcom szybko odróżniać silne kandydatury starterów od słabych, oszczędzając czas, pieniądze i frustrację przy testach DNA.
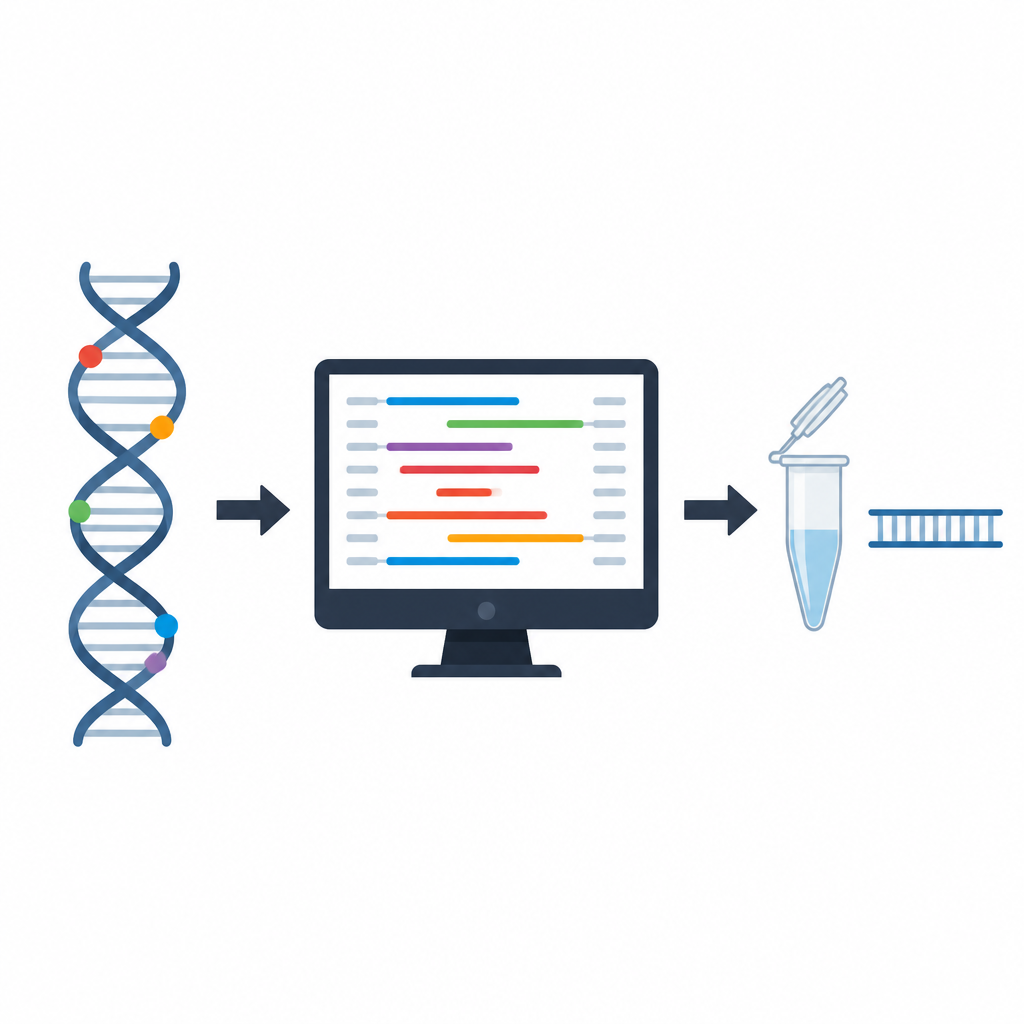
Wyzwanie wyboru właściwych starterów DNA
Startery to krótkie fragmenty DNA, które muszą precyzyjnie wiązać się z wybranym miejscem w genomie, zanim PCR będzie mógł się rozpocząć. Jeśli wiążą się zbyt słabo, w niewłaściwym miejscu lub tworzą splątania same ze sobą, test może nie powieść się lub dać mylące wyniki. Tradycyjne programy do projektowania starterów opierają się na ustalonych regułach dotyczących długości startera, składu chemicznego i prostych kontroli stabilności. Reguły te są pomocne, ale traktują każdą cechę w dużej mierze osobno, pozostawiając naukowcom konieczność ręcznej inspekcji wielu szczegółów i domysłów, jak kombinacje cech zachowają się razem w rzeczywistych eksperymentach.
Przekształcanie rzeczywistych i wadliwych projektów w materiał treningowy
Badacze zbudowali PrimerAST, najpierw gromadząc starannie oznakowaną kolekcję starterów. Wykorzystali rzeczywiste warianty genetyczne w ludzkim DNA, wyodrębnili otaczającą sekwencję i użyli popularnego narzędzia projektowego do wygenerowania par starterów w realistycznych ustawieniach dla testów medycznych. Każda z tych par starterów była następnie testowana w laboratorium przy standardowych warunkach PCR. Zestawy, które dawały czyste, specyficzne produkty DNA, oznaczono jako działające, podczas gdy inne zawiodły i zostały odrzucone. Aby nauczyć system, jak wyglądają złe startery, zespół stworzył także syntetyczne awarie, celowo przesuwając kluczowe właściwości poza bezpieczne zakresy, na przykład czyniąc startery zbyt bogatymi lub zbyt ubogimi w określone zasady, dopuszczając długie powtórzenia tej samej litery lub umieszczając zbyt wiele naturalnych zmian DNA w pobliżu końca wiążącego.
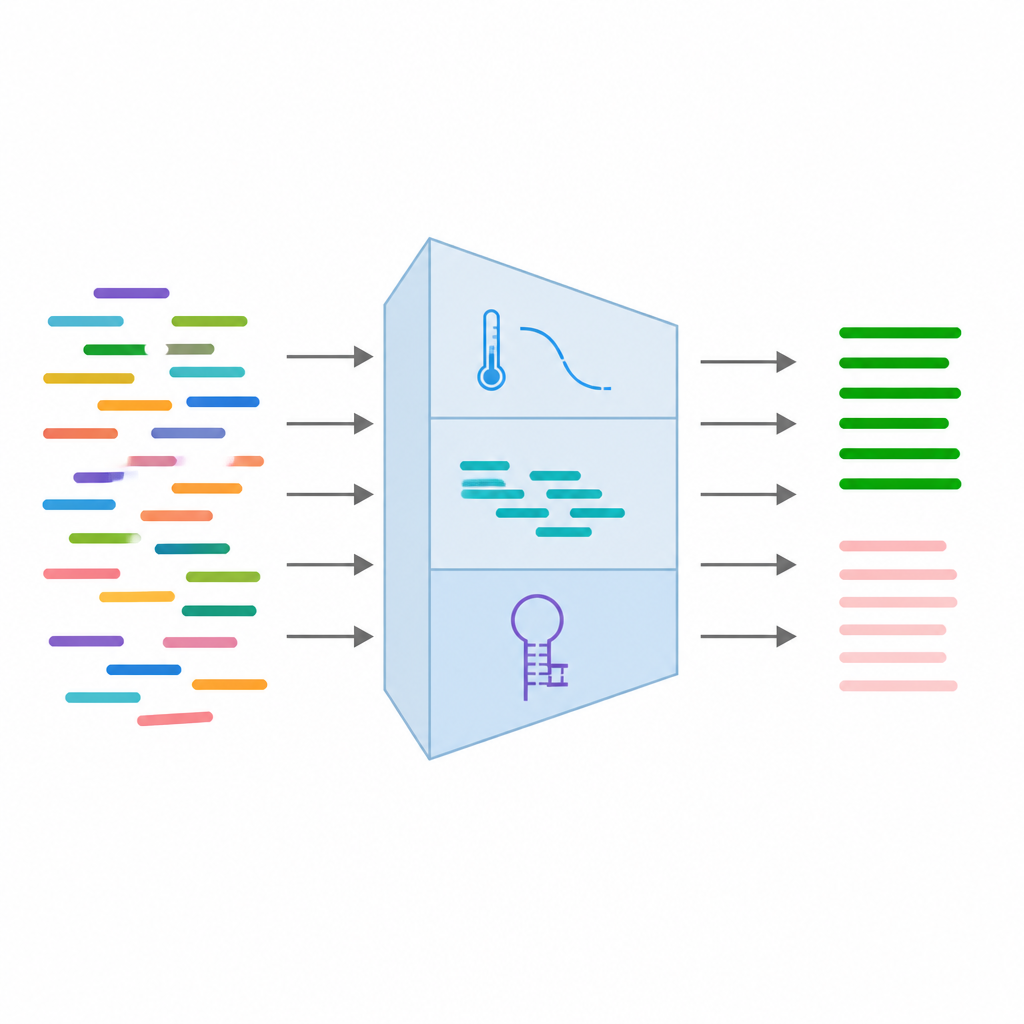
Wprowadzanie kluczowych cech starterów do uczenia maszynowego
Z każdej pary starterów zespół zebrał 24 różne miary opisujące ich oczekiwane zachowanie. Obejmowały one podstawowe cechy sekwencji, takie jak długość i równowaga zasad, cechy termodynamiczne związane z tym, jak mocno startery się wiążą, oraz cechy strukturalne ujawniające, czy prawdopodobnie będą się składać w siebie lub przylegać do siebie nawzajem. Dodano też informacje o znanych wariantach DNA w miejscu wiązania oraz wyniki symulowanych przebiegów PCR, które sprawdzają, czy startery przypadkowo nie pasują do innych miejsc w genomie. Po oczyszczeniu i odfiltrowaniu danych zachowano 16 najbardziej wiarygodnych cech i wystandaryzowano je, aby żadna pojedyncza miara nie dominowała procesu uczenia.
Nauczanie komputera rozróżniania dobrych i złych
Z tymi 16 cechami autorzy trenowali kilka typów nadzorowanych modeli uczenia maszynowego, w tym regresję logistyczną, lasy losowe, maszyny wektorów nośnych i boosting gradientowy. Wykorzystali łącznie 315 par starterów, podzielonych na zbiory treningowe i testowe, oraz oceniali modele za pomocą powszechnych miar dokładności i krzywych mierzących, jak dobrze narzędzia rozróżniają działające od zawodzących starterów. Wszystkie cztery modele wypadły mocno, niektóre osiągając dokładność powyżej 93 procent i bardzo wysokie wyniki w czystości separacji dwóch klas. W szczególności różnice w równowadze temperatur pomiędzy partnerami starterów, długość powtórzeń zasad oraz liczba naturalnych wariantów silnie wpływały na prawdopodobieństwo sukcesu startera. Na podstawie tych wyników najlepszy model zintegrowano z przyjaznym narzędziem internetowym, które jako wejście przyjmuje wariant genetyczny, projektuje kandydackie startery i natychmiast je punktuje.
Co to oznacza dla przyszłych testów DNA
Dla naukowców i klinicystów polegających na PCR, PrimerAST działa jak inteligentny filtr, który przesiewa wiele opcji starterów i wyróżnia te najbardziej prawdopodobne do działania, zanim ktokolwiek trafi do laboratorium. Ucząc się na wzorcach obejmujących wiele cech starterów zamiast samych sztywnych reguł, narzędzie może ograniczyć prób i błędów, zmniejszyć koszty i przyspieszyć projektowanie testów DNA dla nowych wariantów genetycznych. Choć nie zastępuje rzeczywistej walidacji laboratoryjnej i wciąż wymaga rozwoju wraz z kolejnymi danymi z rzeczywistego świata, PrimerAST pokazuje, jak łączenie projektowania DNA z uczeniem maszynowym może uczynić codzienną diagnostykę molekularną bardziej efektywną i niezawodną.
Cytowanie: Al-Mahrami, N., Al Yazidi, S., Alrashdi, H. et al. PrimerAST: A predictive machine learning tool for primer design and quality assessment. Sci Rep 16, 14980 (2026). https://doi.org/10.1038/s41598-026-38238-8
Słowa kluczowe: startery PCR, projektowanie starterów, uczenie maszynowe, narzędzie bioinformatyczne, testy genetyczne