Clear Sky Science · zh
用户体验感知洞察数据集(UXPID):来自公开工业论坛的合成用户反馈
为什么在线技术交流很重要
每天,世界各地的人们在公司支持论坛中发布问题和投诉,当他们的软件或工业设备出现故障时。这些讨论串中藏着大量关于真实用户遇到的困难、喜好以及未满足需求的洞见。然而这些信息往往杂乱、分散,而且常被隐私规则所限制。本文介绍了一种在不暴露任何个人信息的情况下挖掘这些隐秘知识的新方法。
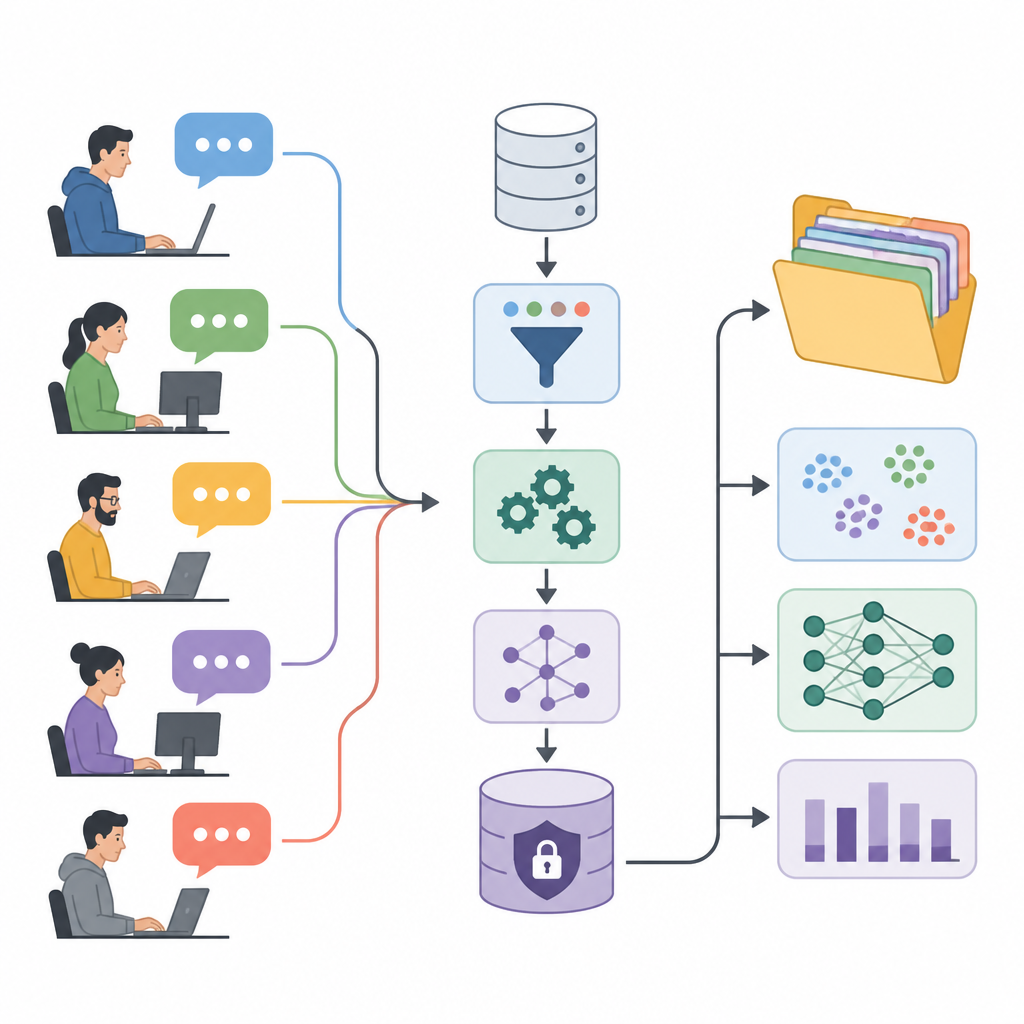
将论坛讨论转化为研究资源
作者提出了用户体验感知洞察数据集(UXPID),这是基于公开工业自动化论坛构建的大规模合成用户讨论集合。他们没有共享可能包含人名、产品编号和公司信息的原始帖子,而是创建了经过谨慎改写的版本,保留语义同时移除敏感线索。每条记录描述了整个讨论分支,从用户的问题开始并包含所有回复,使研究人员不仅能看到单条评论,还能观察完整的问题解决对话。
为混乱对话添加结构
UXPID 的突出之处在于在原始文本之上增加了丰富的结构化信息。研究团队使用强大的语言模型阅读每个讨论并生成主要问题的摘要、用户期望的结果以及问题的严重程度。它还为每个分支标注主题,标明语气为正面、负面或中性,并提取关于痛点、收益和需求功能的简短短语。这将自由形式的闲聊转化为计算机可学习的有组织信息。
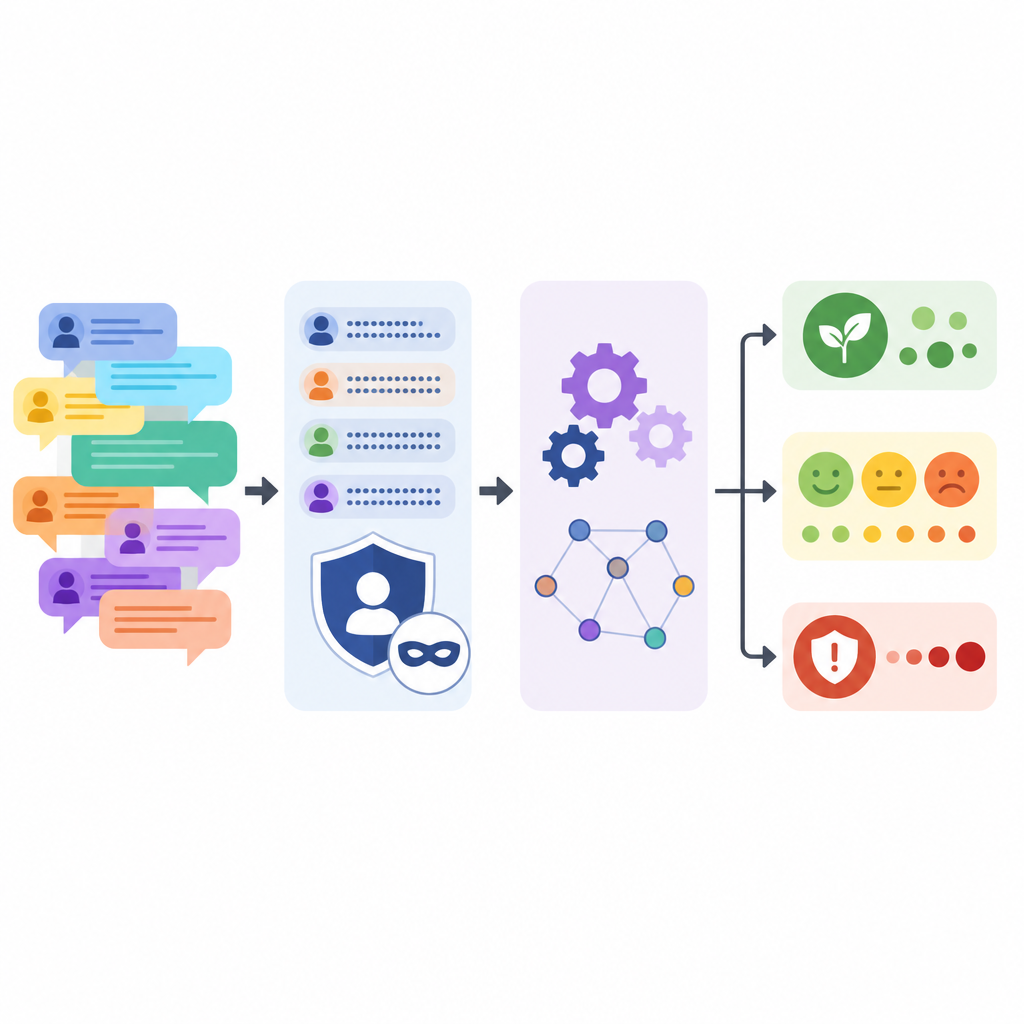
在保护匿名性的同时保留事件脉络
保护论坛参与者是该工作的核心目标。语言模型被指示将公司名、产品标签、版本号、个人姓名、电子邮件和网页链接替换为简单占位符,同时对每条评论进行轻度改写。在此自动处理之后,团队还运行模式匹配以捕捉任何残留的线索(例如电子邮件或 IP 格式),并对样本进行了人工检查。他们还比较了原始文本与处理后文本,表明句子长度和多样性保持相似,即使全部大写的咆哮式文字和一连串感叹号被淡化了。
检验数据集的实用性
为了验证新数据集是否真正有用,作者用它训练了两类计算模型。一类是经典的词频统计方法,另一类是能够捕捉句子上下文的现代 Transformer 模型 DistilBERT。他们让这些模型预测每个讨论的主题标签和整体情绪。Transformer 在各项任务中持续表现更好,尤其是在复杂的多主题案例中,这表明 UXPID 足够丰富,可支持用于问题检测和情感分析等任务的高级语言工具。
这对未来工具的意义
简而言之,论文表明可以将嘈杂且受隐私保护的论坛帖子转变为一份干净、可共享且仍反映真实产品使用情况的资源。UXPID 提供了数千条匿名且带标注的对话,其他研究者可以用来构建和比较用于规模化读取和理解用户反馈的系统。这可能推动更智能的支持工具、更好的产品设计决策以及发现客户体验模式的新方法,同时尊重原帖作者的隐私。
引用: Kulyabin, M., Joosten, J., Ulan uulu, C. et al. User eXperience Perception Insights Dataset (UXPID): Synthetic User Feedback from Public Industrial Forums. Sci Data 13, 762 (2026). https://doi.org/10.1038/s41597-026-07253-9
关键词: 用户反馈, 技术论坛, 自然语言处理, 合成数据集, 用户体验