Clear Sky Science · de
User eXperience Perception Insights Dataset (UXPID): Synthetisches Nutzerfeedback aus öffentlichen Industrieforen
Warum Online‑Tech‑Gespräche wichtig sind
Tagtäglich posten Menschen weltweit Fragen und Beschwerden in Supportforen von Unternehmen, wenn ihre Software oder industriellen Geräte Probleme bereiten. In diesen Threads steckt ein Schatz an Erkenntnissen darüber, womit echte Nutzer kämpfen, was ihnen gefällt und was ihnen noch fehlt. Doch diese Informationen sind unstrukturiert, verstreut und oft durch Datenschutzregeln geschützt. Dieser Artikel stellt einen neuen Weg vor, dieses verborgene Wissen zu erschließen, ohne persönliche Daten preiszugeben.
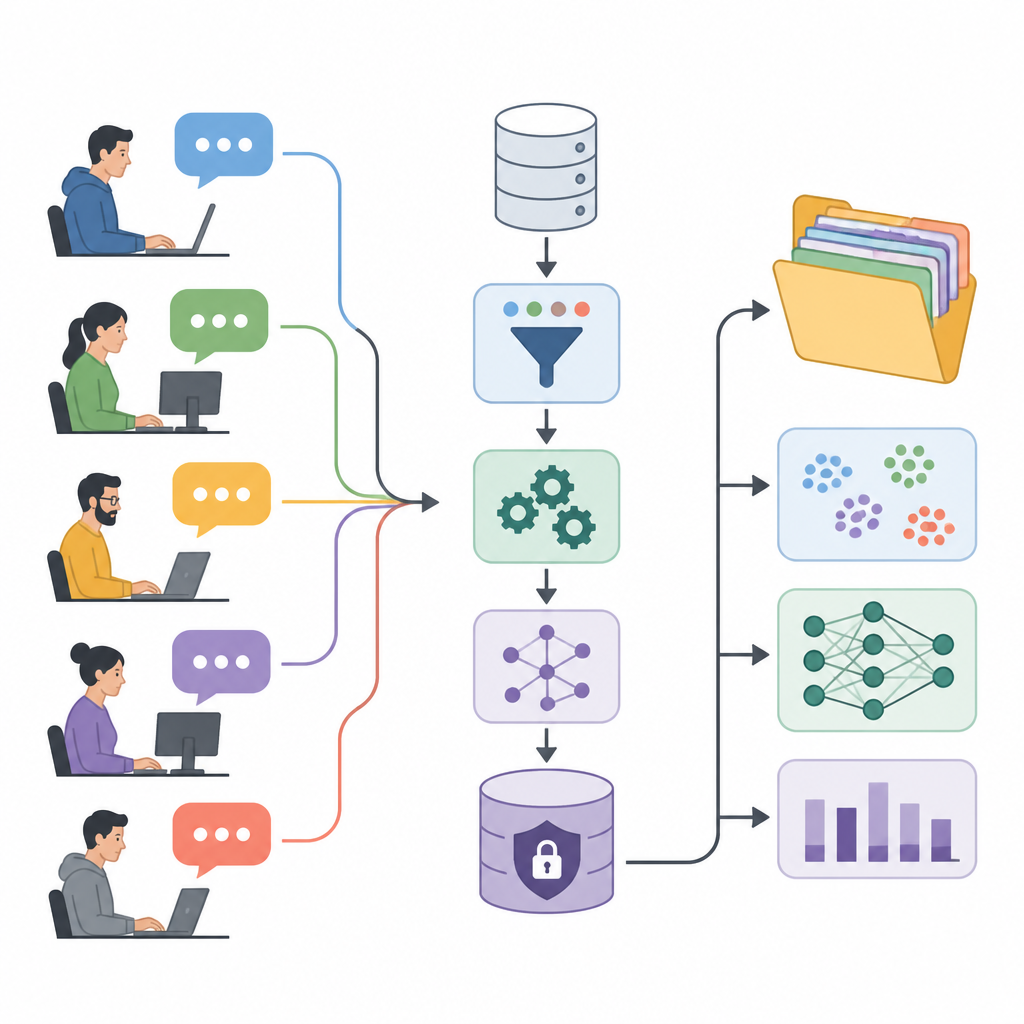
Forumsgespräche in Forschungstreibstoff verwandeln
Die Autor*innen präsentieren das User eXperience Perception Insights Dataset, kurz UXPID, eine umfangreiche Sammlung synthetischer Nutzerdiskussionen, basierend auf einem öffentlichen Industrieautomationsforum. Statt die Originalbeiträge zu teilen, die Namen, Produktcodes oder Firmendetails enthalten könnten, erzeugten sie sorgfältig umformulierte Versionen, die die Bedeutung bewahren, aber sensible Hinweise entfernen. Jeder Datensatz beschreibt einen gesamten Diskussionszweig, beginnend mit der Frage eines Nutzers und einschließlich aller Antworten, sodass Forschende nicht nur einzelne Kommentare, sondern ganze Problemlösungsdialoge sehen können.
Ordnung in chaotische Gespräche bringen
Was UXPID auszeichnet, ist die reichhaltige Struktur, die über den Rohtext gelegt wurde. Das Team nutzte ein leistungsfähiges Sprachmodell, das jede Diskussion las und Zusammenfassungen zum Hauptproblem, zu den Erwartungen des Nutzers und zur Schwere des Problems erstellte. Zudem wurden jedem Zweig Themen zugewiesen, die Tonalität als positiv, negativ oder neutral markiert und kurze Phrasen zu Problemen, Vorteilen und gewünschten Funktionen extrahiert. So wird freier Austausch in organisierte Informationen verwandelt, aus denen Computer lernen können.
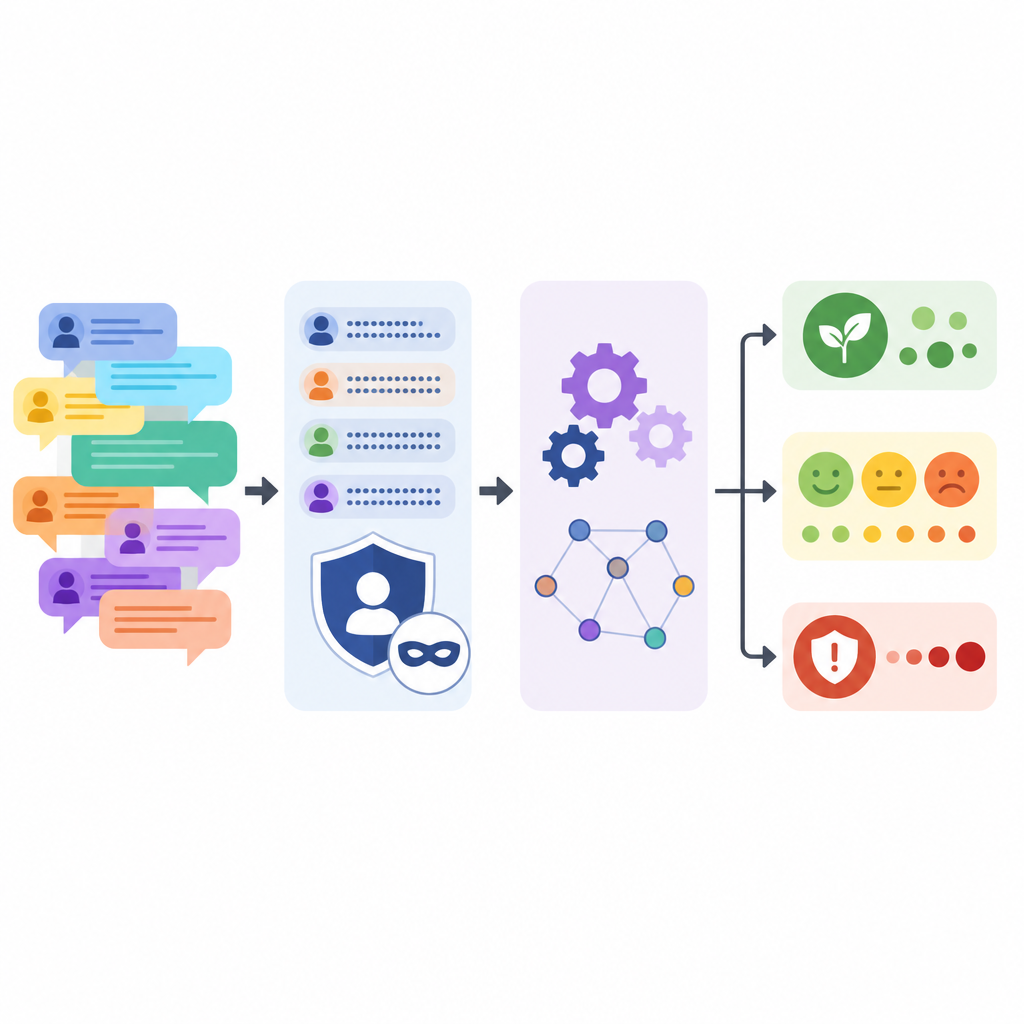
Menschen anonym halten und die Geschichte bewahren
Der Schutz der Forenteilnehmenden war ein zentrales Ziel. Das Sprachmodell wurde angewiesen, Firmennamen, Produktbezeichnungen, Versionsnummern, Personennamen, E‑Mail‑Adressen und Weblinks durch einfache Platzhalter zu ersetzen und jeden Kommentar gleichzeitig leicht umzuschreiben. Nach diesem automatisierten Schritt führte das Team Mustererkennung durch, um verbleibende Hinweise wie E‑Mail‑ oder IP‑Formate zu entdecken, und überprüfte stichprobenartig manuell. Sie verglichen außerdem Original- und verarbeitete Texte und zeigten, dass Satzlänge und Vielfalt ähnlich blieben, obwohl durchgehendes SCHREIEN und Reihen von Ausrufezeichen abgeschwächt wurden.
Das Datenset auf die Probe stellen
Um zu prüfen, ob das neue Datenset tatsächlich nützlich ist, trainierten die Autor*innen zwei Arten von Computermodellen damit. Das eine war ein klassischer Wortzählansatz, das andere ein modernes Transformer‑Modell namens DistilBERT, das Kontext in Sätzen erfassen kann. Sie veranlassten diese Modelle, die Themenlabel und die Gesamttonalität jeder Diskussion vorherzusagen. Der Transformer schnitt durchgängig besser ab, besonders bei schwierigen Multi‑Topic‑Fällen, was darauf hindeutet, dass UXPID reichhaltig genug ist, um fortgeschrittene Sprachwerkzeuge für Aufgaben wie Problemerkennung und Sentiment‑Analyse zu unterstützen.
Was das für zukünftige Werkzeuge bedeutet
Kurz gesagt zeigt die Studie, dass sich raue, private Forenthreads in eine saubere, teilbare Ressource verwandeln lassen, die weiterhin reale Produktnutzung widerspiegelt. UXPID bietet Tausende anonymisierter, gekennzeichneter Konversationen, die andere nutzen können, um Systeme zu entwickeln und zu vergleichen, die Nutzerfeedback in großem Maßstab lesen und verstehen. Das könnte zu intelligenteren Support‑Tools, besseren Produktdesign‑Entscheidungen und neuen Wegen führen, Muster in der Kundenerfahrung zu erkennen — und zwar bei gleichzeitiger Achtung der Privatsphäre der Autoren der Originalbeiträge.
Zitation: Kulyabin, M., Joosten, J., Ulan uulu, C. et al. User eXperience Perception Insights Dataset (UXPID): Synthetic User Feedback from Public Industrial Forums. Sci Data 13, 762 (2026). https://doi.org/10.1038/s41597-026-07253-9
Schlüsselwörter: Nutzerfeedback, technische Foren, natürliche Sprachverarbeitung, synthetisches Datenset, Benutzererfahrung