Clear Sky Science · es
Conjunto de Datos de Percepción de la Experiencia de Usuario (UXPID): Retroalimentación de Usuario Sintética a partir de Foros Industriales Públicos
Por qué importan las conversaciones técnicas en línea
Cada día, personas de todo el mundo publican preguntas y quejas en los foros de soporte de empresas cuando su software o dispositivos industriales fallan. Enterrados en esos hilos hay una mina de información sobre con qué luchan los usuarios reales, qué les gusta y qué necesitan todavía. Sin embargo, esa información es desordenada, dispersa y a menudo está restringida por normas de privacidad. Este artículo presenta una nueva forma de aprovechar ese conocimiento oculto sin exponer los datos personales de nadie.
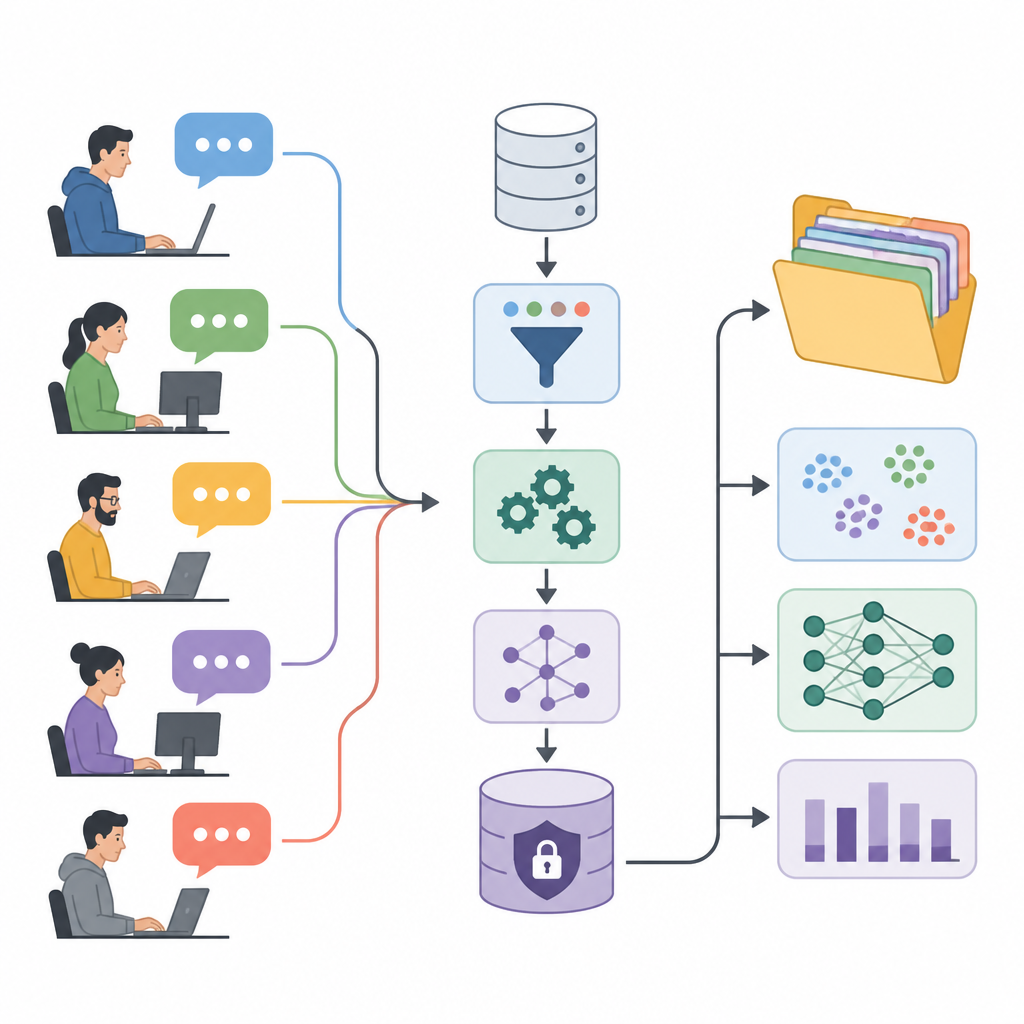
Convertir las conversaciones de foro en combustible para la investigación
Los autores presentan el Conjunto de Datos de Percepción de la Experiencia de Usuario, o UXPID, una amplia colección de discusiones de usuario sintéticas basadas en un foro público de automatización industrial. En lugar de compartir las publicaciones originales, que podrían contener nombres, códigos de producto y detalles de empresas, crearon versiones cuidadosamente reformuladas que mantienen el significado pero eliminan pistas sensibles. Cada registro describe una rama completa de discusión, desde la pregunta de un usuario e incluyendo todas las respuestas, de modo que los investigadores pueden ver no solo comentarios sueltos sino conversaciones completas de resolución de problemas.
Añadiendo estructura a conversaciones desordenadas
Lo que distingue a UXPID es la rica estructura añadida sobre el texto bruto. El equipo usó un potente modelo de lenguaje para leer cada discusión y producir resúmenes del problema principal, qué esperaba el usuario que sucediera y cuán grave parecía el problema. También etiquetó cada rama con temas, indicó si el tono era positivo, negativo o neutral, y extrajo frases cortas sobre molestias, ventajas y funciones solicitadas. Esto convierte el parloteo libre en información organizada que las máquinas pueden aprender.
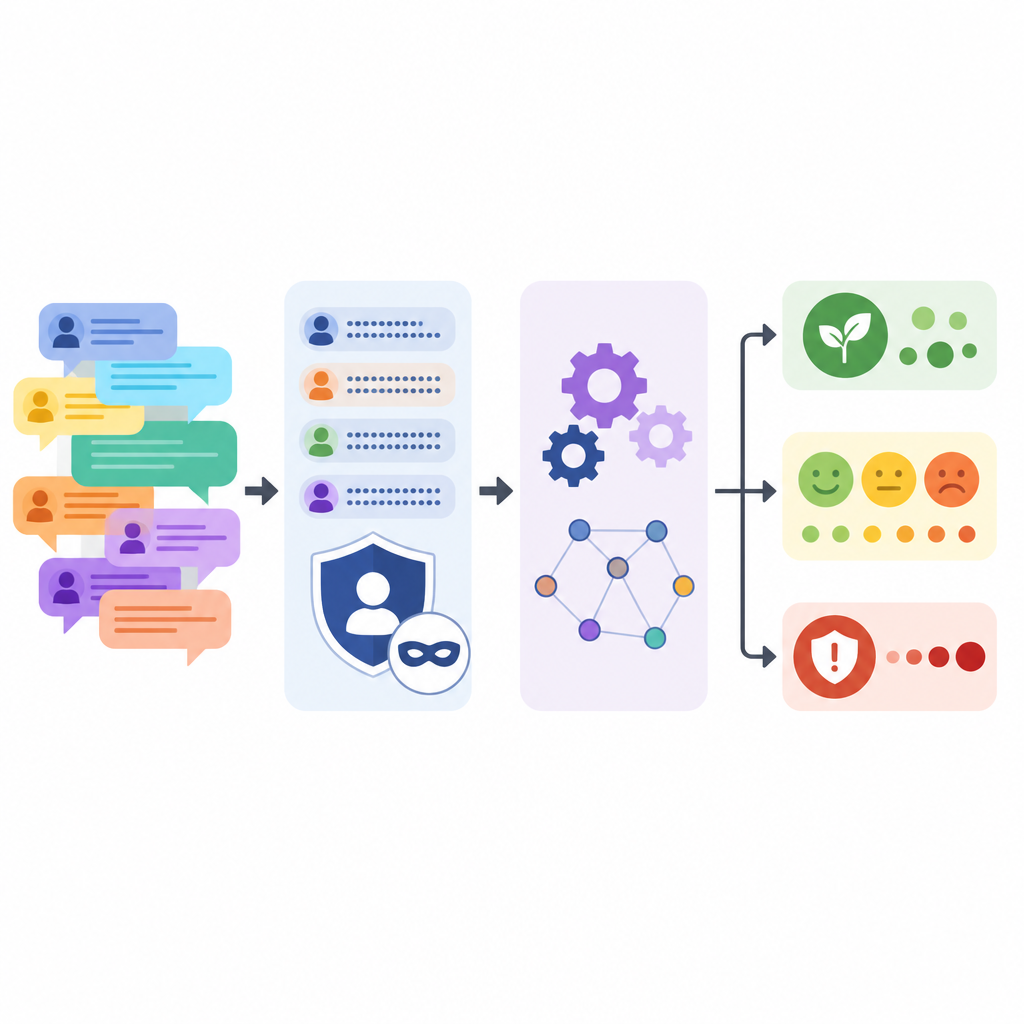
Mantener el anonimato de las personas sin perder la historia
Proteger a los participantes del foro fue un objetivo central. Se instruyó al modelo de lenguaje para que reemplazara nombres de empresas, etiquetas de producto, números de versión, nombres personales, correos electrónicos y enlaces web por marcadores simples mientras se reformulaban ligeramente los comentarios. Tras esta pasada automatizada, el equipo aplicó coincidencia de patrones para detectar cualquier pista residual como formatos de correo o IP, y luego revisó manualmente muestras. También compararon los textos originales y procesados, mostrando que la longitud y la variedad de las oraciones se mantuvieron similares, aunque el uso de mayúsculas para gritar y las cadenas de signos de exclamación se atenuaron.
Poniendo a prueba el conjunto de datos
Para comprobar si el nuevo conjunto de datos es realmente útil, los autores entrenaron dos tipos de modelos informáticos con él. Uno fue un enfoque clásico de conteo de palabras y el otro un modelo transformador moderno conocido como DistilBERT, que puede capturar el contexto en las oraciones. Pedieron a estos modelos que predijeran las etiquetas de tema y el tono general de cada discusión. El transformador rindió consistentemente mejor, especialmente en casos complejos con múltiples temas, lo que sugiere que UXPID es lo suficientemente rico para soportar herramientas de lenguaje avanzadas para tareas como detección de incidencias y análisis de sentimiento.
Qué significa esto para herramientas futuras
En términos sencillos, el artículo demuestra que es posible convertir hilos de foros ruidosos y privados en un recurso limpio y compartible que aún refleja el uso real de productos. UXPID ofrece miles de conversaciones anonimizadas y etiquetadas que otros pueden usar para construir y comparar sistemas que leen y entienden la retroalimentación de usuarios a escala. Esto podría conducir a herramientas de soporte más inteligentes, mejores decisiones de diseño de producto y nuevas formas de detectar patrones en la experiencia del cliente, todo respetando la privacidad de quienes escribieron las publicaciones originales.
Cita: Kulyabin, M., Joosten, J., Ulan uulu, C. et al. User eXperience Perception Insights Dataset (UXPID): Synthetic User Feedback from Public Industrial Forums. Sci Data 13, 762 (2026). https://doi.org/10.1038/s41597-026-07253-9
Palabras clave: retroalimentación de usuarios, foros técnicos, procesamiento de lenguaje natural, conjunto de datos sintético, experiencia de usuario