Clear Sky Science · fr
Jeu de données d’aperçus de la perception de l’expérience utilisateur (UXPID) : retours d’utilisateurs synthétiques issus de forums industriels publics
Pourquoi les discussions techniques en ligne comptent
Chaque jour, des personnes du monde entier postent des questions et des plaintes dans les forums de support des entreprises lorsque leur logiciel ou leurs appareils industriels rencontrent des problèmes. Enfouis dans ces fils se trouvent une mine d’informations sur les difficultés réelles des utilisateurs, ce qu’ils apprécient et ce dont ils ont encore besoin. Pourtant ces informations sont désordonnées, dispersées et souvent protégées par des règles de confidentialité. Cet article présente une nouvelle façon d’exploiter ces connaissances cachées sans exposer les données personnelles de qui que ce soit.
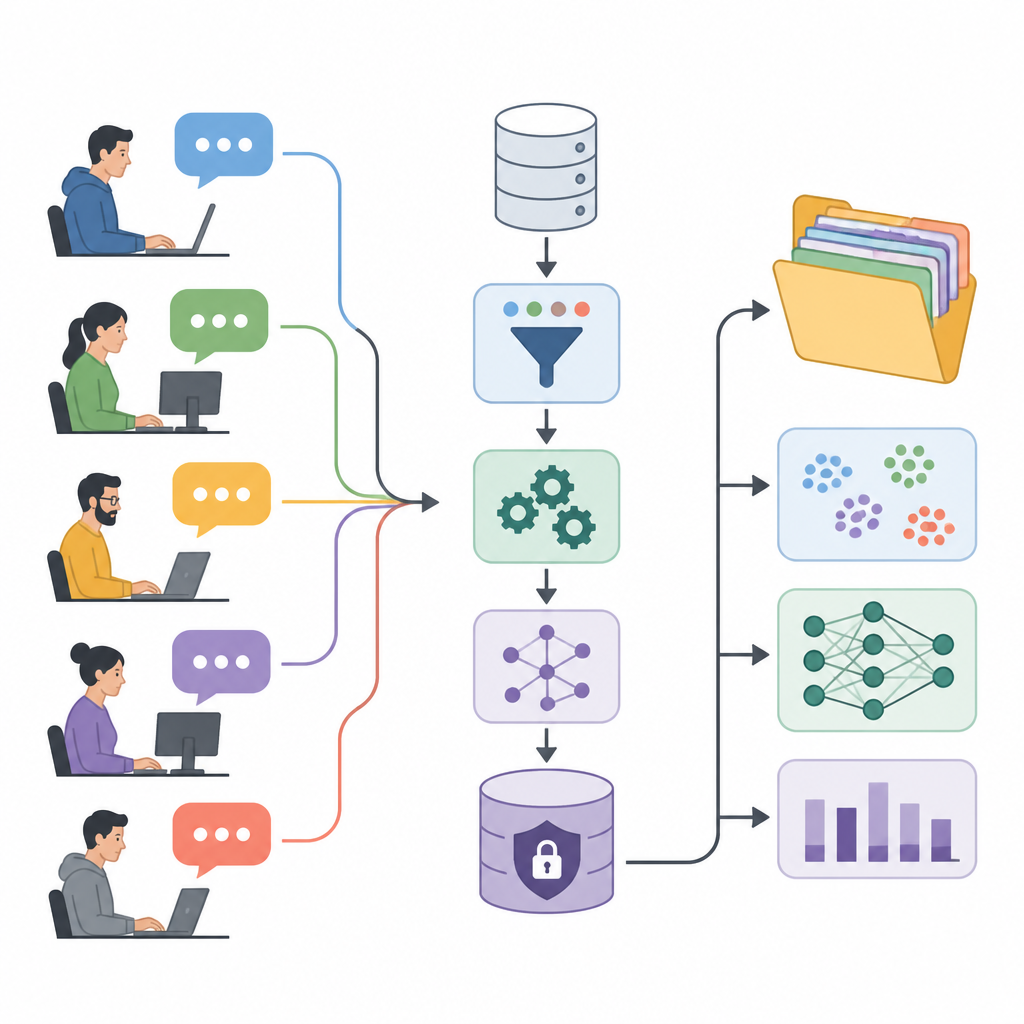
Transformer les échanges de forum en carburant pour la recherche
Les auteurs présentent le jeu de données User eXperience Perception Insights, ou UXPID, une vaste collection de discussions d’utilisateurs synthétiques inspirées d’un forum public d’automatisation industrielle. Plutôt que de partager les messages originaux, qui peuvent contenir des noms, des codes produit et des informations d’entreprise, ils ont créé des versions reformulées avec soin qui conservent le sens tout en supprimant les indices sensibles. Chaque enregistrement décrit une branche entière de discussion, depuis la question initiale d’un utilisateur jusqu’à l’ensemble des réponses, afin que les chercheurs puissent analyser non seulement des commentaires isolés mais des conversations complètes de résolution de problèmes.
Structurer des conversations chaotiques
Ce qui distingue UXPID, c’est la riche structure ajoutée au texte brut. L’équipe a utilisé un puissant modèle de langage pour lire chaque discussion et produire des résumés du problème principal, de ce que l’utilisateur s’attendait à voir se produire et de la gravité apparente du problème. Ils ont également étiqueté chaque branche avec des sujets, indiqué si le ton était positif, négatif ou neutre, et extrait de courtes expressions concernant les douleurs, les gains et les fonctionnalités demandées. Cela transforme les échanges informels en informations organisées que les ordinateurs peuvent apprendre à exploiter.
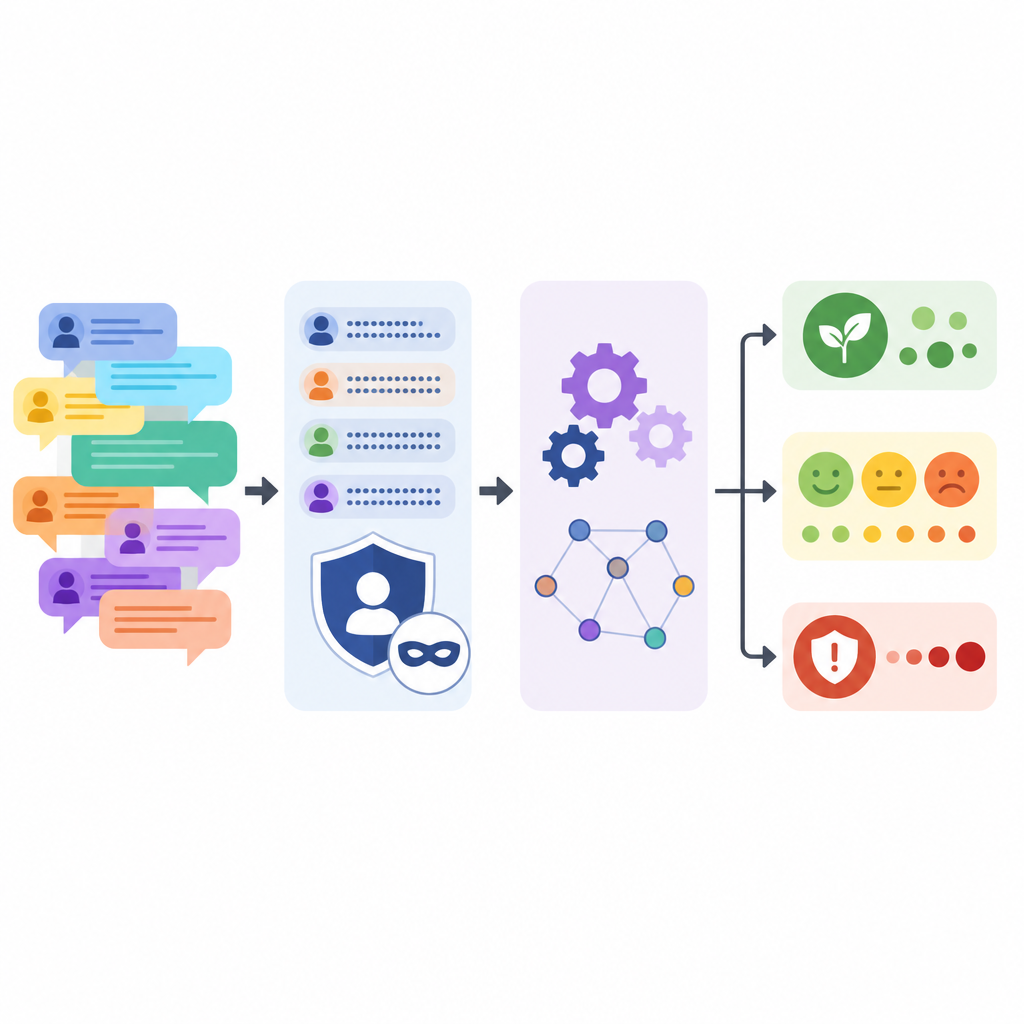
Préserver l’anonymat tout en conservant l’histoire
La protection des participants aux forums a été un objectif central. Le modèle de langage a reçu pour consigne de remplacer les noms d’entreprises, les désignations de produits, les numéros de version, les noms personnels, les adresses e‑mail et les liens web par des espaces réservés simples tout en reformulant légèrement chaque commentaire. Après ce passage automatisé, l’équipe a exécuté des recherches par motifs pour détecter d’éventuels indices restants, comme des formats d’e‑mail ou d’adresse IP, puis a vérifié manuellement des échantillons. Ils ont aussi comparé les textes originaux et traités, montrant que la longueur et la variété des phrases restaient similaires, même si les cris en majuscules et les séries de points d’exclamation ont été atténués.
Tester le jeu de données
Pour vérifier l’utilité réelle du nouveau jeu de données, les auteurs ont entraîné deux types de modèles informatiques dessus. L’un utilisait une approche classique de comptage de mots, et l’autre était un modèle transformer moderne connu sous le nom de DistilBERT, capable de saisir le contexte des phrases. Ils ont demandé à ces modèles de deviner les étiquettes de sujet et l’humeur générale de chaque discussion. Le transformer a systématiquement obtenu de meilleurs résultats, en particulier pour les cas multitopic difficiles, ce qui suggère qu’UXPID est suffisamment riche pour soutenir des outils linguistiques avancés pour des tâches comme la détection de problèmes et l’analyse des sentiments.
Ce que cela signifie pour les outils à venir
En termes simples, l’article démontre qu’il est possible de transformer des fils de forum bruyants et privés en une ressource propre et partageable qui reflète toujours l’usage réel des produits. UXPID propose des milliers de conversations anonymisées et étiquetées que d’autres peuvent utiliser pour construire et comparer des systèmes capables de lire et comprendre les retours d’utilisateurs à grande échelle. Cela pourrait conduire à des outils d’assistance plus intelligents, de meilleures décisions de conception produit et de nouvelles façons d’identifier des tendances dans l’expérience client, tout en respectant la confidentialité des contributeurs des messages originaux.
Citation: Kulyabin, M., Joosten, J., Ulan uulu, C. et al. User eXperience Perception Insights Dataset (UXPID): Synthetic User Feedback from Public Industrial Forums. Sci Data 13, 762 (2026). https://doi.org/10.1038/s41597-026-07253-9
Mots-clés: retours d’utilisateurs, forums techniques, traitement automatique du langage, jeu de données synthétique, expérience utilisateur