Clear Sky Science · pl
Zbiór danych User eXperience Perception Insights (UXPID): syntetyczne opinie użytkowników z publicznych forów przemysłowych
Dlaczego internetowe rozmowy o technologii mają znaczenie
Codziennie ludzie na całym świecie zamieszczają pytania i skargi na firmowych forach wsparcia, gdy ich oprogramowanie lub urządzenia przemysłowe źle działają. W tych wątkach kryje się skarbnica informacji o tym, z czym realni użytkownicy mają problemy, co im się podoba i czego nadal potrzebują. Jednak te informacje są nieuporządkowane, rozproszone i często ograniczone zasadami prywatności. Ten artykuł przedstawia nowy sposób dostępu do tej ukrytej wiedzy bez ujawniania czyichkolwiek danych osobowych.
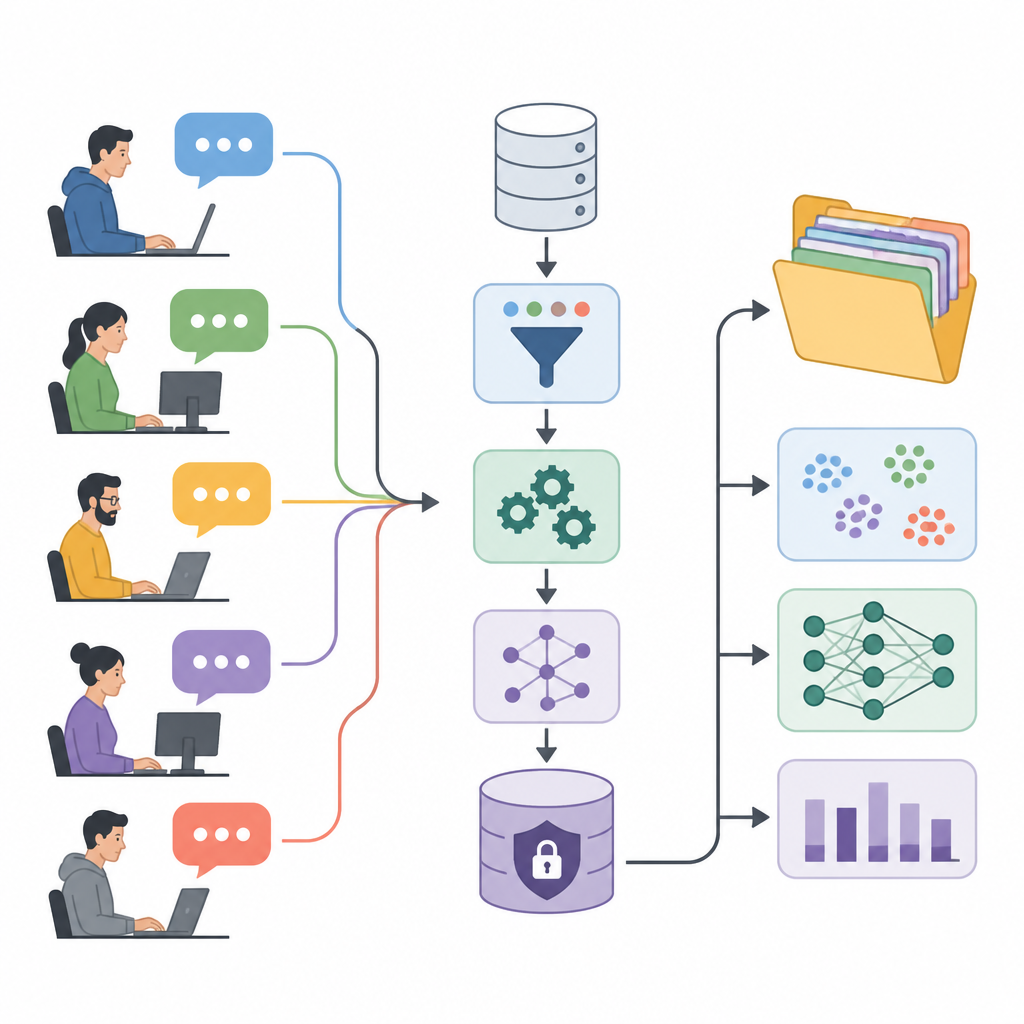
Przekształcanie rozmów z forum w materiał badawczy
Autorzy przedstawiają User eXperience Perception Insights Dataset, czyli UXPID — dużą kolekcję syntetycznych dyskusji użytkowników opartych na publicznym forum automatyki przemysłowej. Zamiast udostępniać oryginalne wpisy, które mogą zawierać nazwy, kody produktów i szczegóły firm, stworzyli starannie przeformułowane wersje, które zachowują sens, ale usuwają wrażliwe wskazówki. Każdy rekord opisuje cały wątek dyskusji, zaczynając od pytania użytkownika i obejmując wszystkie odpowiedzi, dzięki czemu badacze mogą obserwować nie pojedyncze komentarze, lecz całe konwersacje rozwiązujące problemy.
Dodawanie struktury do chaotycznych rozmów
Co wyróżnia UXPID, to bogata struktura dodana ponad surowym tekstem. Zespół użył zaawansowanego modelu językowego, aby przeczytać każdą dyskusję i wygenerować streszczenia głównego problemu, tego, czego użytkownik oczekiwał, oraz oceny powagi usterki. Model oznaczył też każdy wątek tematami, określił, czy ton był pozytywny, negatywny czy neutralny, oraz wyodrębnił krótkie frazy dotyczące bolączek, korzyści i żądanych funkcji. Dzięki temu swobodna rozmowa zamienia się w uporządkowaną informację, od której komputery mogą się uczyć.
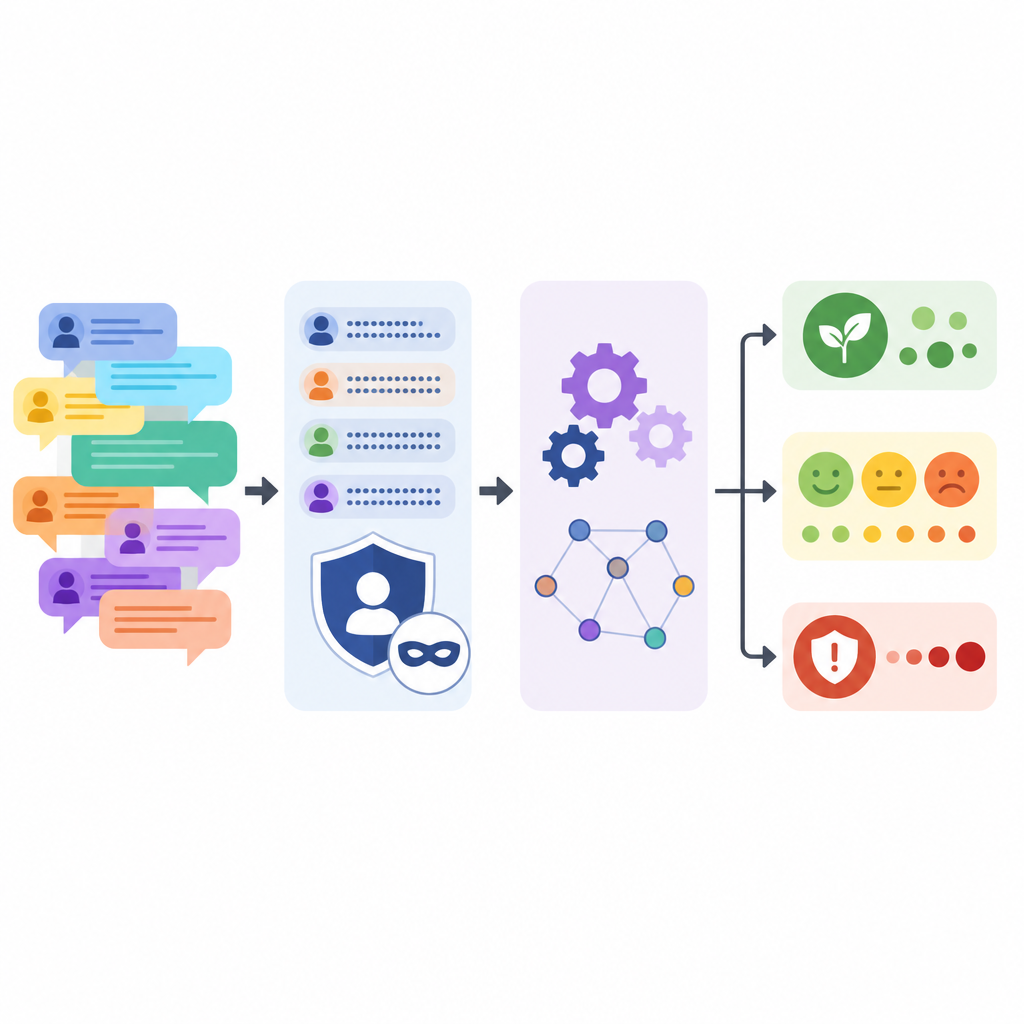
Zachowanie anonimowości przy zachowaniu treści
Ochrona uczestników forum była celem priorytetowym. Model językowy otrzymał instrukcję zastępowania nazw firm, oznaczeń produktów, numerów wersji, imion, adresów e-mail i linków internetowych prostymi symbolami zastępczymi, przy jednoczesnym lekkim przekształceniu formy każdego komentarza. Po tym automatycznym przejściu zespół uruchomił dopasowywanie wzorców, by wychwycić pozostałe wskazówki, takie jak formaty adresów e‑mail czy IP, a następnie ręcznie skontrolował próbki. Porównali też teksty oryginalne i przetworzone, pokazując, że długość zdań i ich zróżnicowanie pozostały podobne, choć krzyki wielkimi literami i ciągi wykrzykników zostały stonowane.
Testowanie użyteczności zbioru danych
Aby sprawdzić, czy nowy zbiór rzeczywiście ma wartość, autorzy przeszkolili na nim dwa rodzaje modeli komputerowych. Jeden to klasyczne podejście oparte na zliczaniu słów, a drugi to nowoczesny model transformerowy znany jako DistilBERT, potrafiący uchwycić kontekst w zdaniach. Poprosili te modele o przewidywanie etykiet tematycznych i ogólnego nastroju każdej dyskusji. Transformer konsekwentnie radził sobie lepiej, zwłaszcza w trudnych przypadkach wielotematycznych, co sugeruje, że UXPID jest wystarczająco bogaty, by wspierać zaawansowane narzędzia językowe do zadań takich jak wykrywanie problemów i analiza sentymentu.
Co to oznacza dla przyszłych narzędzi
Mówiąc prosto, artykuł pokazuje, że można przekształcić hałaśliwe, prywatne wątki forum w czyste, możliwe do udostępnienia zasoby, które nadal odzwierciedlają rzeczywiste użycie produktów. UXPID oferuje tysiące zanonimizowanych, oznakowanych konwersacji, których inni mogą użyć do budowy i porównywania systemów czytających i rozumiejących opinie użytkowników na dużą skalę. To może prowadzić do inteligentniejszych narzędzi wsparcia, lepszych decyzji projektowych i nowych sposobów wykrywania wzorców w doświadczeniu klientów, przy jednoczesnym poszanowaniu prywatności autorów oryginalnych wpisów.
Cytowanie: Kulyabin, M., Joosten, J., Ulan uulu, C. et al. User eXperience Perception Insights Dataset (UXPID): Synthetic User Feedback from Public Industrial Forums. Sci Data 13, 762 (2026). https://doi.org/10.1038/s41597-026-07253-9
Słowa kluczowe: opinie użytkowników, fora techniczne, przetwarzanie języka naturalnego, syntetyczny zbiór danych, doświadczenie użytkownika