Clear Sky Science · ja
ユーザー体験認識インサイトデータセット(UXPID):公開産業フォーラムから作成した合成ユーザーフィードバック
なぜオンラインの技術チャットが重要なのか
世界中で、人々はソフトウェアや産業機器に不具合が生じたときに企業のサポートフォーラムに質問や苦情を書き込みます。こうしたスレッドには、実際のユーザーが何に困っているか、何を好み、何を求めているかについての貴重な洞察が埋もれています。しかし、この情報は散在していて雑多であり、しばしばプライバシーの規則によって守られています。本稿では、誰の個人情報もさらすことなく、その隠れた知見にアクセスする新しい方法を紹介します。
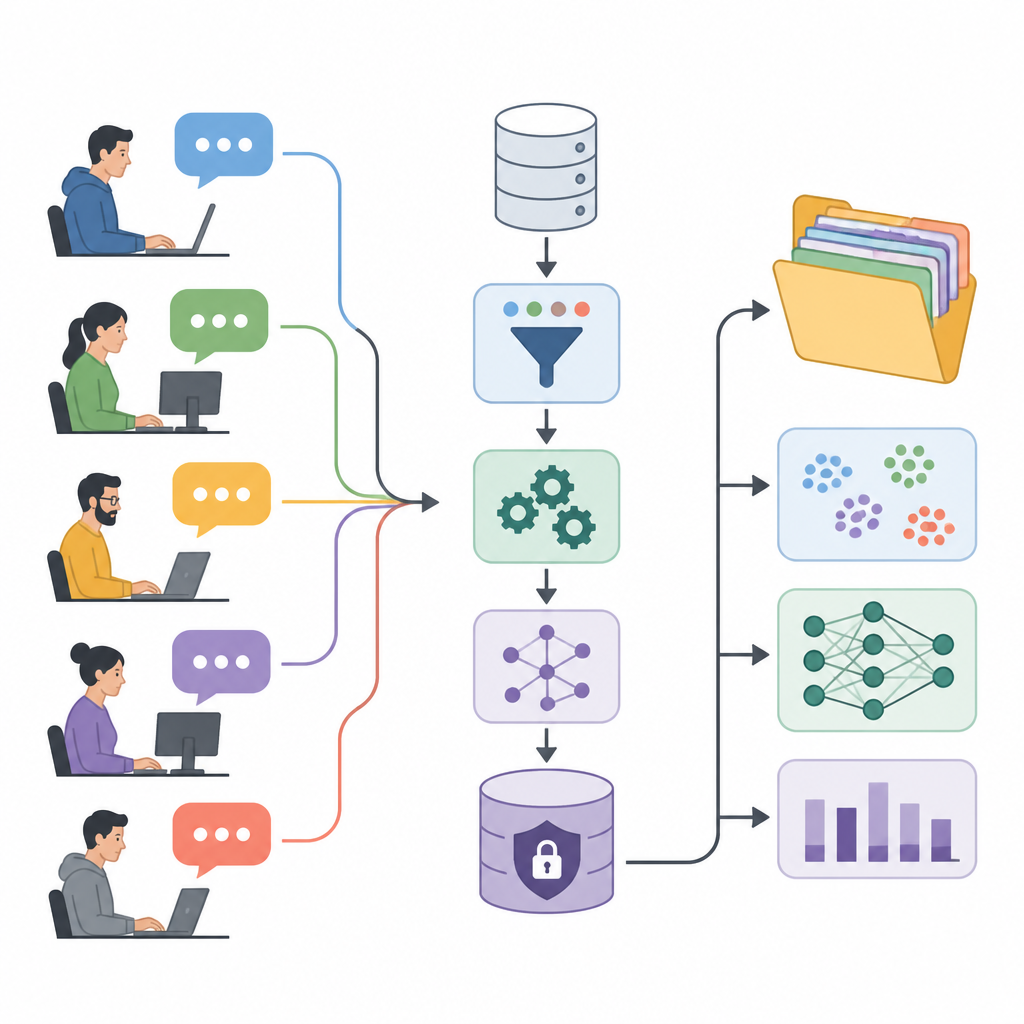
フォーラムの会話を研究の燃料に変える
著者らは、User eXperience Perception Insights Dataset(UXPID)を提示します。これは公開されている産業オートメーションフォーラムを元に作成した大規模な合成ユーザー議論コレクションです。氏名や製品コード、企業名が含まれている可能性のある元の投稿をそのまま共有する代わりに、意味を保ちながら敏感な手がかりを除去した慎重な言い換え版を作成しました。各レコードはユーザーの質問から始まり、すべての返信を含む議論の枝全体を記述しており、研究者は個々のコメントだけでなく問題解決の会話全体を把握できます。
雑多な会話に構造を付与する
UXPIDの特徴は、生テキストの上に付加された豊富な構造です。チームは強力な言語モデルを用いて各議論を読み、主要な問題点、ユーザーが期待していた事柄、および問題の重大度を要約しました。さらに各枝にトピックをタグ付けし、トーンが肯定的・否定的・中立的のいずれかであることを示し、痛み(pain)、利得(gain)、要求された機能に関する短いフレーズを抽出しました。これにより自由形式の雑談がコンピュータが学習できる組織化された情報に変わります。
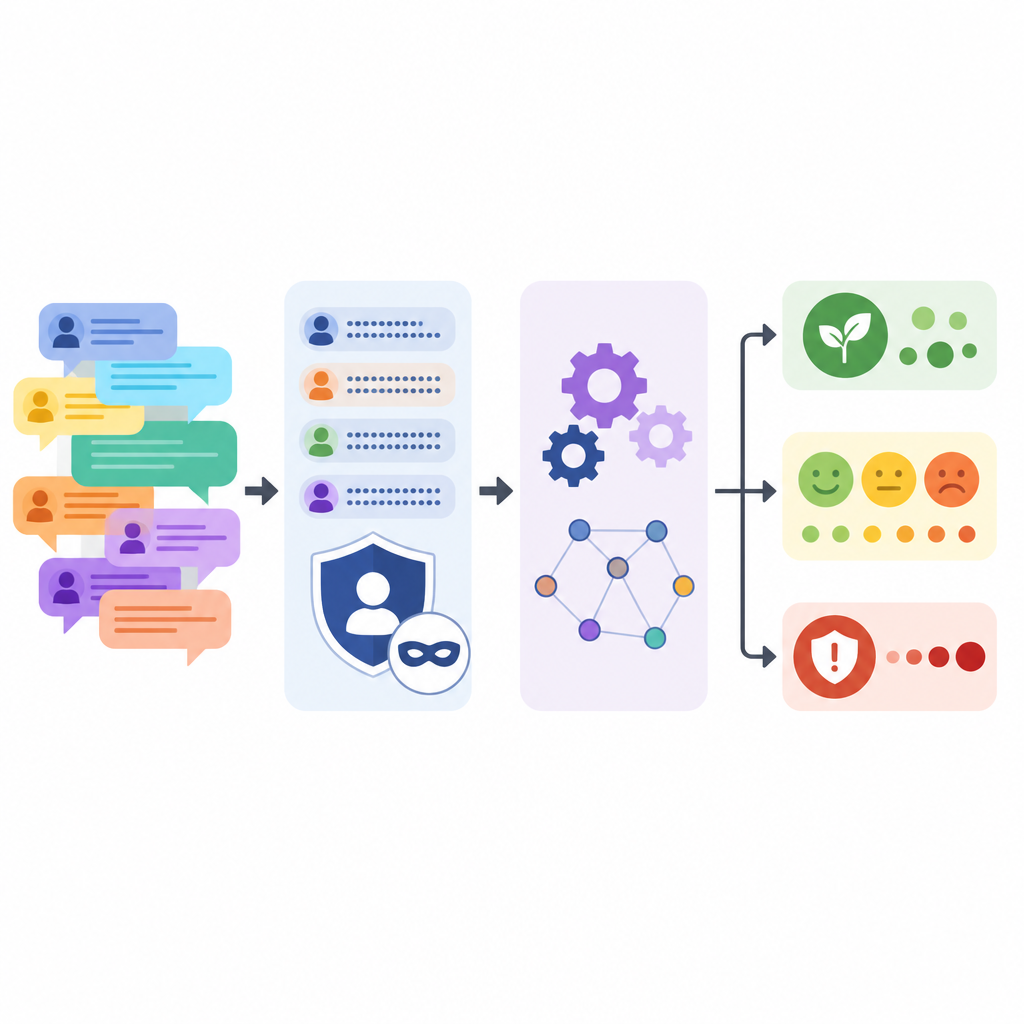
個人を特定させずにストーリーを保存する
フォーラム参加者の保護が中心的な目的でした。言語モデルには企業名、製品ラベル、バージョン番号、個人名、メールアドレス、ウェブリンクを単純なプレースホルダに置き換えつつ、各コメントを軽く言い換えるよう指示しました。この自動処理の後、チームはメールやIP形式など残存する手がかりを検出するためのパターンマッチングを実施し、サンプルを手動で検査しました。元のテキストと処理後のテキストを比較したところ、文の長さや多様性は概ね保たれており、全大文字による強調や感嘆符の連続は抑えられていることが示されました。
データセットを実地で検証する
新しいデータセットが実際に有用かどうかを確認するために、著者らはこれを用いて二種類のコンピュータモデルを訓練しました。一つは古典的な語頻度に基づく手法、もう一つは文脈を捉えられる最新のトランスフォーマー型モデルであるDistilBERTです。これらのモデルに各議論のトピックラベルと全体的な感情を推定させました。トランスフォーマーは一貫して優れた結果を出し、特に複数トピックが混在する難しいケースで有利でした。これはUXPIDが問題検出や感情分析のような高度な言語ツールを支えるに足る豊富さを備えていることを示唆します。
将来のツールにとっての意義
要するに、この論文は、騒がしくプライベートなフォーラムスレッドを、現実の製品利用を反映しつつも共有可能で整備されたリソースに変えることが可能であると示しています。UXPIDは何千もの匿名化されラベル付けされた会話を提供し、他者がユーザーフィードバックを大規模に読み取り理解するシステムを構築・比較するために利用できます。これにより、より賢いサポートツール、より良い製品設計の意思決定、顧客体験のパターンを見つける新たな方法などが生まれる可能性があり、元投稿者のプライバシーも尊重されます。
引用: Kulyabin, M., Joosten, J., Ulan uulu, C. et al. User eXperience Perception Insights Dataset (UXPID): Synthetic User Feedback from Public Industrial Forums. Sci Data 13, 762 (2026). https://doi.org/10.1038/s41597-026-07253-9
キーワード: ユーザーフィードバック, 技術フォーラム, 自然言語処理, 合成データセット, ユーザー体験