Clear Sky Science · it
User eXperience Perception Insights Dataset (UXPID): Synthetic User Feedback from Public Industrial Forums
Perché le chat tecniche online sono importanti
Ogni giorno, persone in tutto il mondo postano domande e lamentele nei forum di supporto aziendale quando il loro software o i loro dispositivi industriali si comportano male. Sepolti in questi thread ci sono preziosi indizi su cosa gli utenti reali trovano difficile, cosa apprezzano e di cosa hanno ancora bisogno. Tuttavia queste informazioni sono disordinate, frammentate e spesso protette da vincoli di privacy. Questo articolo presenta un nuovo modo per accedere a quella conoscenza nascosta senza esporre i dettagli personali di nessuno.
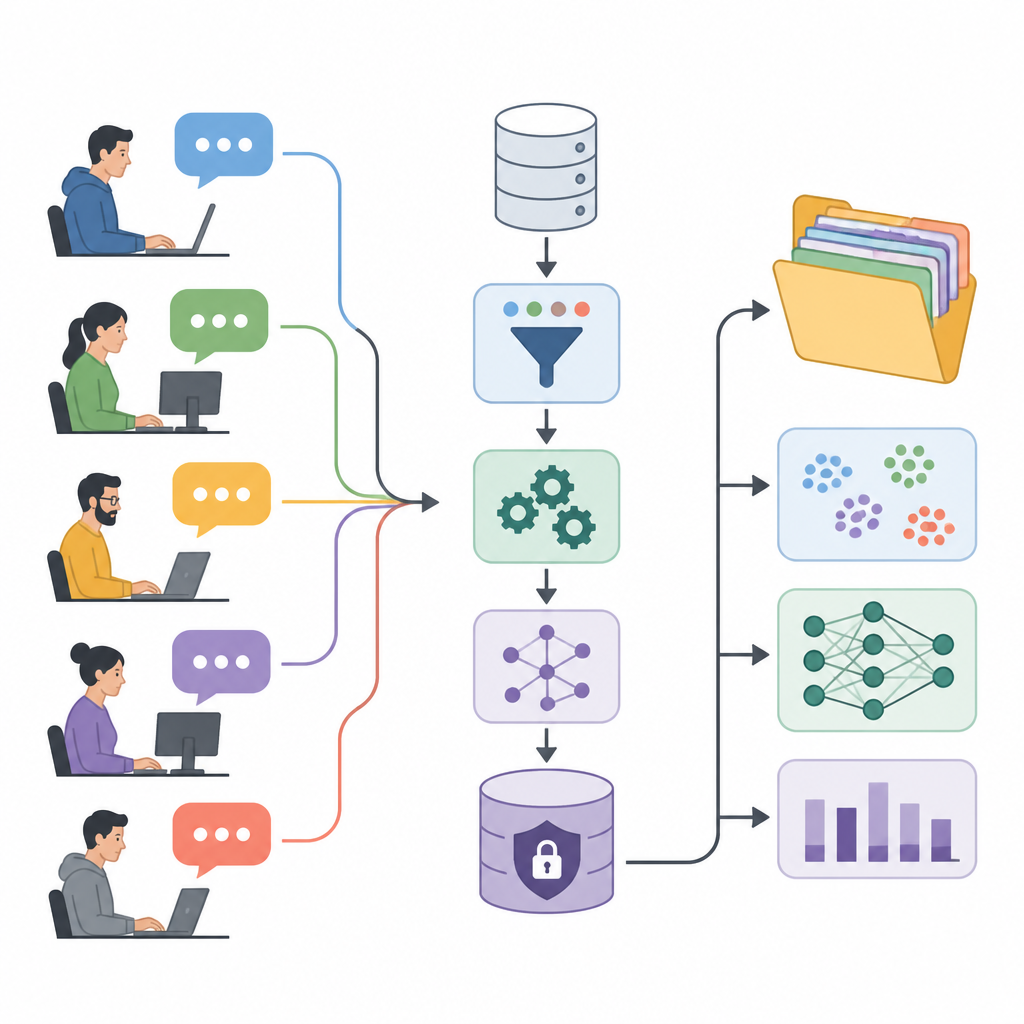
Trasformare le discussioni dei forum in carburante per la ricerca
Gli autori presentano lo User eXperience Perception Insights Dataset, o UXPID, una grande raccolta di discussioni utente sintetiche basate su un forum pubblico di automazione industriale. Invece di condividere i post originali, che potrebbero contenere nomi, codici prodotto e dettagli aziendali, hanno creato versioni riformulate con cura che mantengono il significato ma rimuovono indizi sensibili. Ogni record descrive un intero ramo di discussione, a partire dalla domanda di un utente e includendo tutte le risposte, in modo che i ricercatori possano vedere non solo singoli commenti ma conversazioni complete di risoluzione dei problemi.
Aggiungere struttura a conversazioni confuse
Ciò che distingue UXPID è la ricca struttura aggiunta al testo grezzo. Il team ha usato un potente modello linguistico per leggere ogni discussione e produrre riepiloghi del problema principale, di ciò che l’utente si aspettava che accadesse e di quanto grave sembrasse il problema. Ha anche etichettato ogni ramo con topic, indicato se il tono era positivo, negativo o neutro, ed estratto brevi frasi relative a dolori, benefici e funzionalità richieste. Questo trasforma il chiacchiericcio libero in informazioni organizzate che i computer possono apprendere.
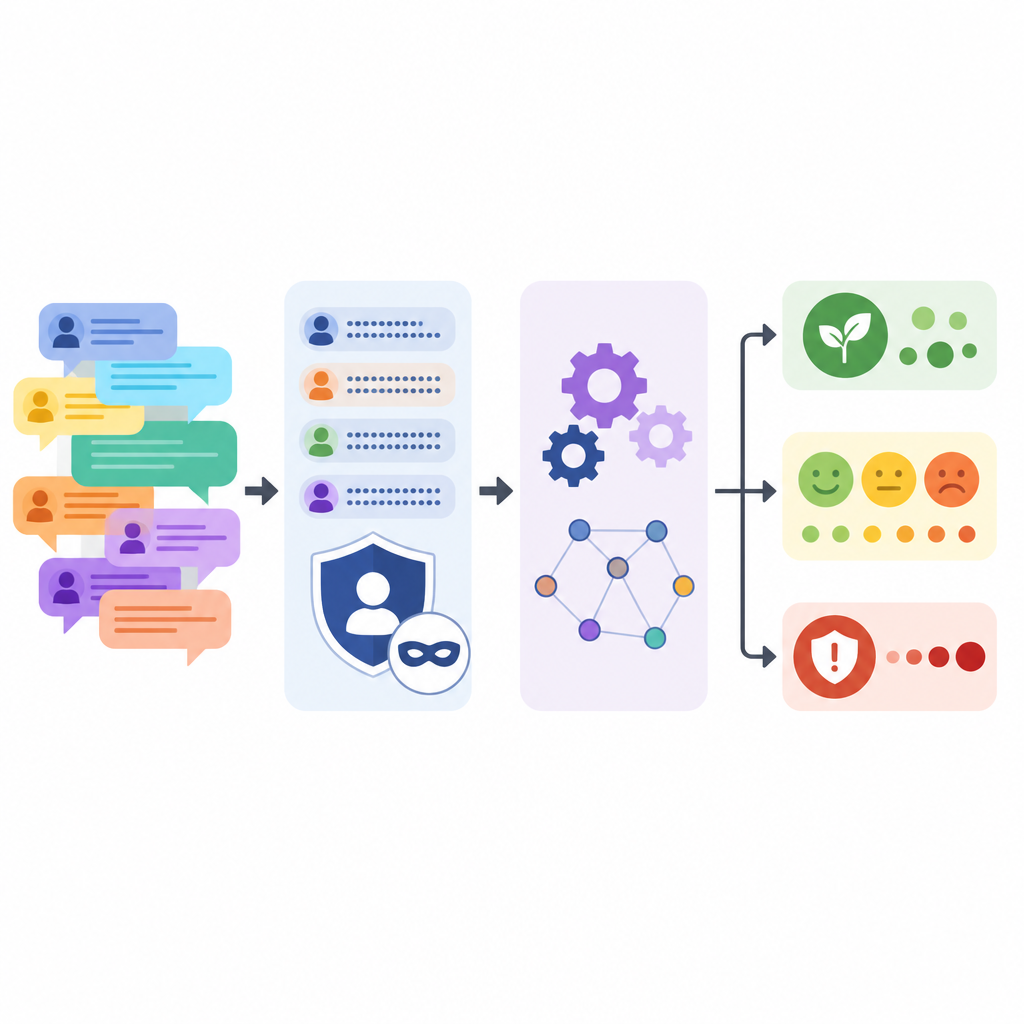
Mantenere l’anonimato delle persone salvando però la storia
Proteggere i partecipanti del forum è stato un obiettivo centrale. Al modello linguistico è stato chiesto di sostituire nomi di aziende, etichette di prodotto, numeri di versione, nomi personali, email e link web con semplici segnaposto, riformulando leggermente ogni commento. Dopo questo passaggio automatizzato, il team ha eseguito controlli basati su pattern per catturare eventuali indizi residui come formati di email o IP, e poi ha verificato manualmente dei campioni. Hanno anche confrontato i testi originali e quelli processati, dimostrando che la lunghezza e la varietà delle frasi sono rimaste simili, sebbene urla in maiuscolo e sequenze di punti esclamativi siano state attenuate.
Mettere alla prova il dataset
Per verificare se il nuovo dataset è davvero utile, gli autori hanno addestrato su di esso due tipi di modelli computazionali. Uno era un approccio classico basato sul conteggio delle parole, e l’altro un modello transformer moderno noto come DistilBERT, capace di catturare il contesto nelle frasi. Hanno chiesto a questi modelli di indovinare le etichette dei topic e l’umore complessivo di ogni discussione. Il transformer ha ottenuto risultati costantemente migliori, specialmente nei casi multi‑topic più difficili, il che suggerisce che UXPID è sufficientemente ricco da supportare strumenti linguistici avanzati per compiti come il rilevamento dei problemi e l’analisi del sentiment.
Cosa significa per gli strumenti futuri
In termini semplici, l’articolo dimostra che è possibile trasformare thread di forum rumorosi e privati in una risorsa pulita e condivisibile che continui a riflettere l’uso reale dei prodotti. UXPID offre migliaia di conversazioni anonimizzate ed etichettate che altri possono usare per costruire e confrontare sistemi che leggono e comprendono il feedback degli utenti su larga scala. Questo potrebbe portare a strumenti di supporto più intelligenti, decisioni di design del prodotto migliori e nuovi modi per individuare schemi nell’esperienza del cliente, il tutto rispettando la privacy di chi ha scritto i post originali.
Citazione: Kulyabin, M., Joosten, J., Ulan uulu, C. et al. User eXperience Perception Insights Dataset (UXPID): Synthetic User Feedback from Public Industrial Forums. Sci Data 13, 762 (2026). https://doi.org/10.1038/s41597-026-07253-9
Parole chiave: feedback degli utenti, forum tecnici, elaborazione del linguaggio naturale, dataset sintetico, esperienza utente